Now that you have an understanding of how to use 1) data blocks, 2) the data dictionary, and 3) data structures for advanced Oracle tuning, you are ready to more closely examine the Oracle partitioning facility.
By the time you complete this module you should be able to:
Describe how partitioning functions in Oracle
List the differences between global and local partitioning
Describe the structure of a partitioned index
Explain how to load a partition
Explain how to maintain an indexed partition
Partitioning Capabilities
Partitioning allows a table, index, or index-organized table to be subdivided into smaller pieces, where each piece of such a database object is called a partition. Each partition has its own name, and may optionally have its own storage characteristics. From the perspective of a database administrator, a partitioned object has multiple pieces that can be managed either collectively or individually. This gives the administrator considerable flexibility in managing partitioned objects. From the perspective of the application, a partitioned table is identical to a non-partitioned table; no modifications are necessary when accessing a partitioned table using SQL queries and DML statements.
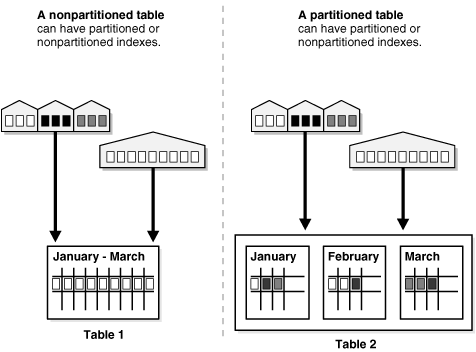
The figure below offers a graphical view of how partitioned tables differ from non-partitioned tables.
Comparison of a non-partitioned table with a partitioned table
A very large database has no minimum absolute size. Although a VLDB is a database similar to smaller databases, there are specific challenges in managing a VLDB. These challenges are related to the sheer size, and the cost-effectiveness of performing operations against a system that size, taken for granted on smaller databases. Several trends have been responsible for the steady growth in database size:
For a long time, systems have been developed in isolation. Companies have started to see the benefits of combining these systems to enable cross-departmental analysis while reducing system maintenance costs. Consolidation of databases and applications is a key factor in the ongoing growth of database size.
Many companies face regulations that set specific requirements for storing data for a minimum amount of time. The regulations generally result in more data being stored for longer periods of time.
Companies grow organically and through mergers and acquisitions, causing the amount of generated and processed data to increase. At the same time, the user population that relies on the database for daily activities increases.
Partitioning is a critical feature for managing very large databases. Growth is the basic challenge that partitioning addresses for very large databases, and partitioning enables a "divide and conquer" technique for managing the tables and indexes in the database, especially as those tables and indexes grow. Partitioning is the feature that allows a database to scale for very large datasets while maintaining consistent performance, without unduly increasing administrative or hardware resources.