| Lesson 12 | Archived Redo Logs |
| Objective | Archived redo logs provide point-in-time recovery. |
Archived Redo Logs in Oracle
Generating Change Reports from redo logs
Since all database changes end up being written to the redo log, it is possible to generate change reports by reading those files. This is called log mining [1].
Oracle never used to directly support this, and as a result several third-party tools have been developed for that purpose. With Oracle8i, Oracle delivered a feature named the LogMiner. This consists of several SQL statements that have been enhanced to allow you to read data from your log files and place that data in tables that you can query for reporting purposes.
What Is Redo?
Redo log files are crucial to the Oracle database. These are the transaction logs for the database.
Oracle maintains two types of redo log files:
- online and
- archived.
The reason for this lies in the fact that, in any multiuser system, there will be tens or hundreds or thousands of concurrent transactions.
One of the primary functions of a database is to mediate concurrent access to its data. The blocks that our transaction modifies are, in general, being modified by many other transactions as well. Therefore, we cannot just put a block back exactly the way it was at the start of our transaction, that could undo the work of someone else. For example, suppose our transaction executed an INSERT statement that caused the allocation of a new extent (i.e., it caused the table to grow).
Our INSERT would cause us to get a new block, format it for use, and put some data into it. At that point, some other transaction might come along and insert data into this block. If we roll back our transaction, obviously we cannot unformat and unallocate this block. Therefore, when Oracle rolls back, it is really doing the logical equivalent of the opposite of what we did in the first place. For every INSERT, Oracle will do a DELETE and for every DELETE, Oracle will do an INSERT.
For every UPDATE, Oracle will do an anti-UPDATE, or an UPDATE that puts the row back the way it was prior to our modification.
For every UPDATE, Oracle will do an anti-UPDATE, or an UPDATE that puts the row back the way it was prior to our modification.
Archived redo logs provide point-in-time Recovery
Explain how archived redo logs provide point-in-time recovery.
You have just learned about how redo logs can be used to replay transactions lost during a system crash. They can also be used to replay transactions when a database has been restored from a backup. This enables you to restore a database from a backup, and recover it up to the very moment of failure, without losing any committed transactions. The key to doing this is to save all the redo logs generated since the most recent backup. You do this by running your database in archive log mode, which you will learn about later in this course.
You have just learned about how redo logs can be used to replay transactions lost during a system crash. They can also be used to replay transactions when a database has been restored from a backup. This enables you to restore a database from a backup, and recover it up to the very moment of failure, without losing any committed transactions. The key to doing this is to save all the redo logs generated since the most recent backup. You do this by running your database in archive log mode, which you will learn about later in this course.
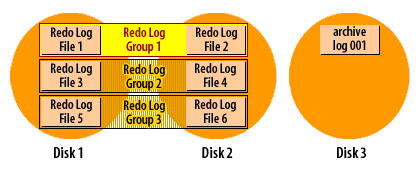
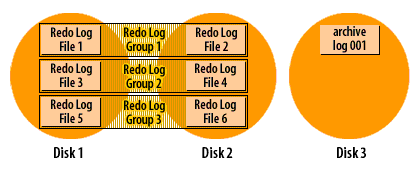
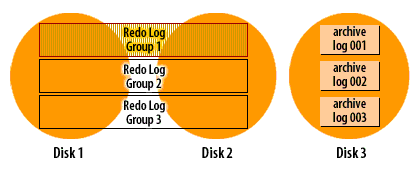
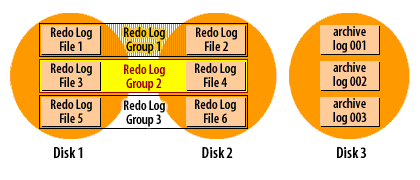
How archive log mode works
Recall that Oracle cycles through the redo log files in a circular fashion, reusing each file over and over again. When you run a database in archive log mode, Oracle makes a copy of each redo log file before it is reused.
The following series of images demonstrates how it works:
Oracle Redo log cycle in archive log mode
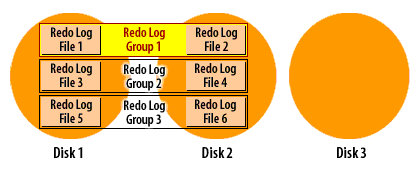
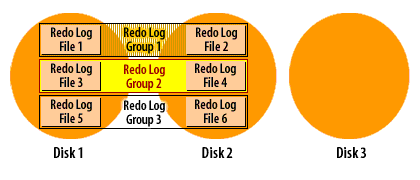
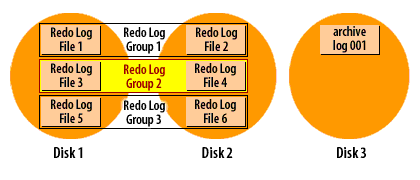
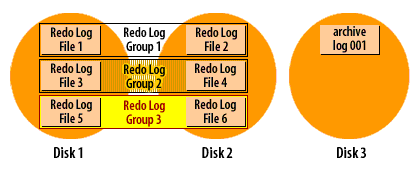
Oracle Database Administration
Naming of archive log files
As you can see from the SlideShow, the redo log filenames do not carry over when a log file is archived. Instead, archive log files are sequentially numbered. You do have control over the format of the filename through the use of the
LOG_ARCHIVE_FORMAT initialization parameter. You will learn about that in a later course in this series.
Timing of the archiver Process
The copying of files is done asynchronously with respect to the log switches and Oracle only copies one member of each group to the archive log destination. When a log switch occurs, the archiver process is notified. The archiver will eventually copy the log file. As the DBA, you hope this will start right away, but the archiver may be busy with a previous file. The important point is that database users do not have to wait while files are archived. As long as the archiver gets caught up before Oracle needs to reuse that log file,the archiving process will run smoothly. There are a number of things that affect whether or not the archiver will be caught up at any given moment: disk I/O speed, disk contention, CPU utilization, and the transaction rate. A sudden burst of activity could cause the archiver to slow down for awhile. That is OK, as long as it can keep up with the overall throughput.
This archiving process is one more reason why you must have a minimum of two redo log groups in an Oracle database. In order for the archiver process to make a copy of a filled redo log file, that file must be closed long enough for the copy to take place. The only way to close a redo log file and still keep the database running, is to switch to another redo log group, and that's exactly what Oracle8i does.
This archiving process is one more reason why you must have a minimum of two redo log groups in an Oracle database. In order for the archiver process to make a copy of a filled redo log file, that file must be closed long enough for the copy to take place. The only way to close a redo log file and still keep the database running, is to switch to another redo log group, and that's exactly what Oracle8i does.
[1]
log mining: The process of generating reports by reading files.
