| Lesson 2 | Advantages of clusters |
| Objective | Know when to use clustered tables. |
Purpose of a Clustered Table
The purpose of creating a clustered table in a database is to physically group together related data on the same disk pages. This helps to improve query performance by reducing the number of disk accesses required to retrieve data.
In a clustered table, the data is physically sorted and stored on disk based on the values of one or more columns. This allows for faster data retrieval when querying on those columns, as the database engine can read in the data for an entire range of values in a single disk access.
For example, if a table is clustered on a column that contains customer IDs, all of the data for a given customer will be stored together on disk. When querying for data related to a specific customer, the database engine can quickly read in all of the data for that customer in a single disk access. Creating a clustered table can have a significant impact on query performance, particularly for large tables or tables that are frequently queried. However, it also requires careful consideration of the table's data distribution and access patterns, as well as the available disk space and I/O capabilities of the system. This will improve query performance by physically grouping related data on disk and reducing the number of disk accesses required to retrieve the data.
For example, if a table is clustered on a column that contains customer IDs, all of the data for a given customer will be stored together on disk. When querying for data related to a specific customer, the database engine can quickly read in all of the data for that customer in a single disk access. Creating a clustered table can have a significant impact on query performance, particularly for large tables or tables that are frequently queried. However, it also requires careful consideration of the table's data distribution and access patterns, as well as the available disk space and I/O capabilities of the system. This will improve query performance by physically grouping related data on disk and reducing the number of disk accesses required to retrieve the data.
Advantages of Oracle Clustered Tables
In theory, each data object within an Oracle database is a totally separate entity. In practice, certain tables are frequently used together, especially when using a normalized database design. A cluster is a way of organizing data to leverage the related nature of data stored in different locations.
What is a cluster?
Simply put, a cluster ties data values to disk location.
A cluster key is used to group data together. All rows of all tables with the same value of the cluster key are stored in the same data block. The following Slide Show shows the difference between a normal table and a clustered table.
A cluster key is used to group data together. All rows of all tables with the same value of the cluster key are stored in the same data block. The following Slide Show shows the difference between a normal table and a clustered table.
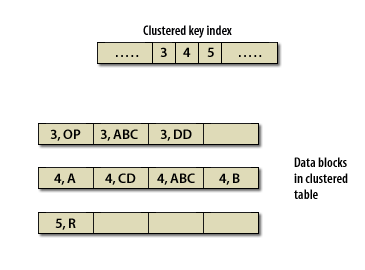
Clustered Versus Non-Clustered
Table Index versus Cluster Key (Oracle Access)
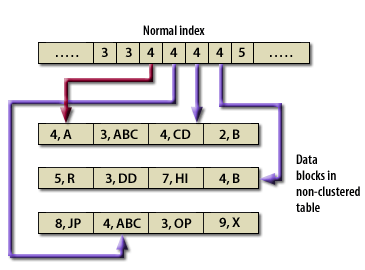
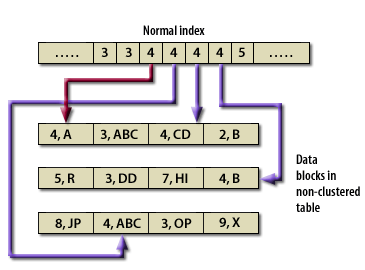
- In a normal table and index, the index tree has an entry for each row in the underlying data table, regardless of value
- If you wanted to access all the data for a particular index value, you would access each index value and its associated row in the table.
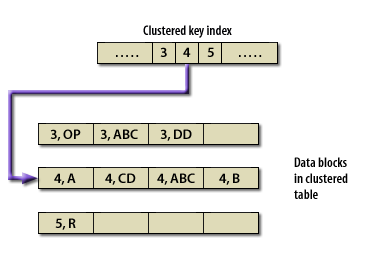
- In a cluster, Oracle keeps a single entry for each value in the cluster key.
- To access all the rows in a table that have the same value in the cluster key, Oracle reads a single entry from the cluster key
Advantages of a cluster
Since related data is stored together, the related data can be accessed with fewer data block reads. With a cluster, Oracle reads the cluster key, which directly points to the disk area that contains the data for that value of the key. The cluster delivers two advantages:
- First of all, a query can retrieve all the related data with usually no more than 2 logical reads:
- one to get the cluster key and
- another to retrieve a data block that contains only the relevant data.
- The second advantage is that the value for the cluster key is only stored once, and this reduces the amount of space required for storage.
When to use a cluster
The ideal places to use a cluster are when you have a group of tables that are frequently queried together, or when you have a single table that is frequently accessed by an index value. For example, you might cluster an order header table and an order detail table together. If you frequently accessed employees by department, you may want to cluster an employee table by department.
When not to use a cluster
In some situations, a cluster is definitely not appropriate. You should not use a cluster in the following situations:
Oracle Clustering Advantages.
The next lesson shows how to create a cluster.
- If the value for a cluster key is updated frequently.
- If the data for the values of the cluster key takes up more than one or two Oracle data blocks.
- If you frequently require full table scans on the clustered data.
Oracle Clustering Advantages.
The next lesson shows how to create a cluster.
