Reduce Data Redundancy
An existing ER diagram was presented in a previous lesson and illustrated how the entities in the diagram could be represented as tables.
Now I will show you how to examine your tables to ensure they reduce data redundancy and allow records to be
- added,
- updated, and
- deleted
What is Data Redundancy?
Data redundancy occurs in database systems which have a field in a table that is repeated in two or more tables.
When customer data is duplicated and attached with each product bought, this will create a source of inconsistency,
since the entity "customer" may appear with different values for a given attribute.
Data redundancy leads to data anomalies and corruption and should be avoided when creating a relational database consisting of several entities. Database normalization prevents redundancy and makes the best possible usage of storage. The proper use of foreign keys can minimize data redundancy and reduce the chance of destructive anomalies appearing. Concerns with respect to the efficiency and convenience can sometimes result in redundant data design despite the risk of corrupting the data.
Difference between Redundant Data and Duplicate Data
Care must be taken to distinguish between 1) duplicated data and 2) redundant data.
Duplicated data is present when an attribute has two (or more) identical values. A data value is redundant if you can delete it without information being lost. In other words, redundancy is unnecessary duplication. Table Part in Fig. 3.1 a) contains duplicated data, because the value
nut occurs twice for the attribute partDescription. The table does not, however, contain redundant data.
If, as in Fig. 3.1 b), the value nut is deleted from the row P2 nut, you will no longer be able to tell from the table what the description of part P2 should be.
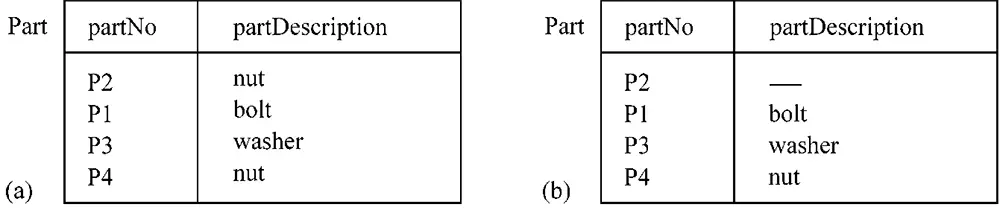
(a) Duplication but no redundancy (b) Deletion of duplicated but non-redundant data value causes loss of information
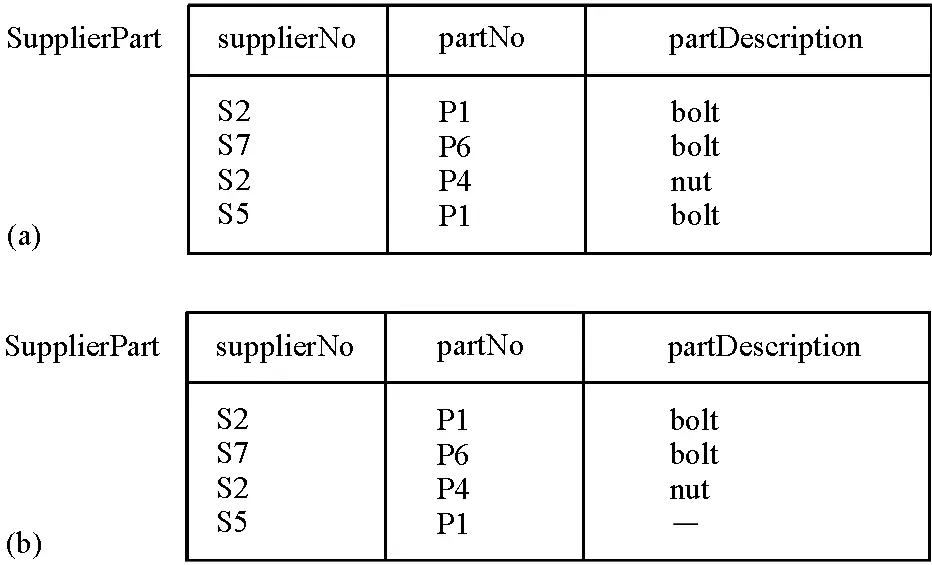
In contrast, table SupplierPart in Fig. 3.1 b) contains duplicated data which is
redundant. This table shows which suppliers supply which parts, and also the descriptions of the parts. Notice that partNo P1 is a bolt and is duplicated, and that the duplication is redundant because, even if the value bolt were deleted from
one of the occurrences of P1 bolt, you could still tell from the table that P1 is a bolt.
In Fig. 3.1 b), the value bolt has been deleted from the fourth row, but the description of partNo P1 can still be deduced from the first row.
In Fig. 3.1 b), the value bolt has been deleted from the fourth row, but the description of partNo P1 can still be deduced from the first row.
Normalization and removing Duplication in Data
The term normalization means to make normal in terms of causing something to conform to a standard, or to introduce consistency with respect to style and content. In terms of relational database modeling, that consistency becomes a process of removing duplication in data. Removal of duplication tends to minimize redundancy and minimization of redundancy implies getting rid of unneeded data present in particular tables. In reality, normalization usually manages to divide information into smaller, more manageable parts.The most obvious redundancies can usually be removed without involving math. Commercially speaking, the primary objectives of normalization are usually to save space and organize data for usability and manageability, without sacrificing performance. This process can present a challenge and solved through trial and error. Additionally the demands of 1) intensely busy applications and 2) end-user needs can tend to necessitate breaking the rules of normalization in many ways to meet performance requirements. Rules are usually broken simply by not applying every possible layer of normalization. Normal Forms beyond 3rd Normal Form are often ignored and sometimes even 3rd Normal Form itself is discounted.
Normalization can be described as an introduction of granularity, removal of duplication, or minimizing of redundancy, or simply the introduction of tables, all of which place data into a better organized state.
Normalize your Schema
Yes, once again, somebody is telling you to normalize your schema. In addition to the benefits of normalization that are glorified elsewhere, a normalized schema is far easier to replicate.
Why? Consider a schema that is in first normal form (1NF) meaning its tables contain redundant data.
For example, a CUSTOMER table might have a column company_name.
If this table contains 1000 records for customers who work for Acme Tire and Rubber, then 1000 records will have to be updated when Acme Tire and Rubber changes its name to Acme Tire and Rubber and Lawn Furniture. Since every update is a potential conflict, updates should be kept to a minimum.
In addition, if a field such as company_name appears in numerous tables, you will have to devote significant effort to devising methods to ensure that an update to the field in one table affects the appropriate updates in the other tables not only locally but globally. A more practical concern with a denormalized schema is that such schemas are typically characterized by tables with many columns. Since replicated (DML) Data Manipulation Language must compare the old and new values of every column of every changed row, performance will suffer.
An unfortunate myth among database designers is that normalization reduces performance. The thought process is that since a denormalization can lead to a performance gain, any steps in the opposite direction must lead to performance losses. This conclusion is not accurate and do not denormalize for performance without the metrics to justify it.
Why? Consider a schema that is in first normal form (1NF) meaning its tables contain redundant data.
For example, a CUSTOMER table might have a column company_name.
If this table contains 1000 records for customers who work for Acme Tire and Rubber, then 1000 records will have to be updated when Acme Tire and Rubber changes its name to Acme Tire and Rubber and Lawn Furniture. Since every update is a potential conflict, updates should be kept to a minimum.
In addition, if a field such as company_name appears in numerous tables, you will have to devote significant effort to devising methods to ensure that an update to the field in one table affects the appropriate updates in the other tables not only locally but globally. A more practical concern with a denormalized schema is that such schemas are typically characterized by tables with many columns. Since replicated (DML) Data Manipulation Language must compare the old and new values of every column of every changed row, performance will suffer.
An unfortunate myth among database designers is that normalization reduces performance. The thought process is that since a denormalization can lead to a performance gain, any steps in the opposite direction must lead to performance losses. This conclusion is not accurate and do not denormalize for performance without the metrics to justify it.
Ad Database Analysis for Design
