| Lesson 4 | Characteristics of a full-table scan |
| Objective | Explain FTS and Buffer Hit ratio |
Characteristics of Full Table Scan
A full table scan reads all rows from a table, and then filters out those rows that do not meet the selection criteria.
How a Full Table Scan Works
In a full table scan, the database sequentially reads every formatted block under the high water mark. The database reads each block only once. The following graphic depicts a scan of a table segment, showing how the scan skips unformatted blocks below the high water mark.
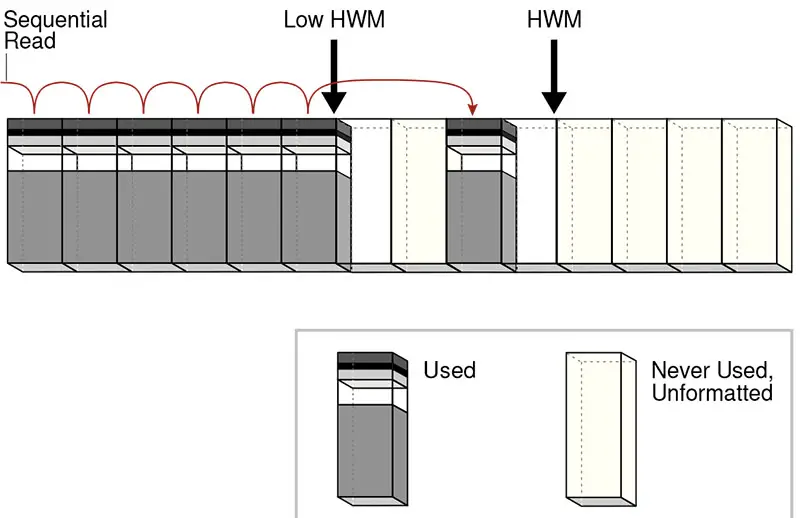
Because the blocks are adjacent, the database can speed up the scan by making I/O calls larger than a single block, known as a multiblock read. The size of a read call ranges from one block to the number of blocks specified by the DB_FILE_MULTIBLOCK_READ_COUNT initialization parameter. For example, setting this parameter to 4 instructs the database to read up to 4 blocks in a single call. The algorithms for caching blocks during full table scans are complex. For example, the database caches blocks differently depending on whether tables are small or large.
Caching Blocks
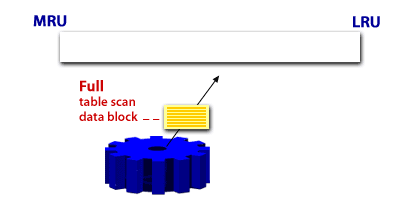
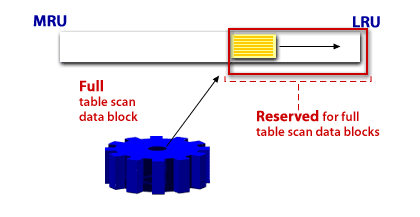
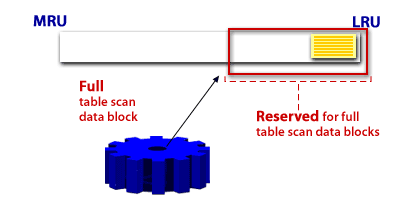
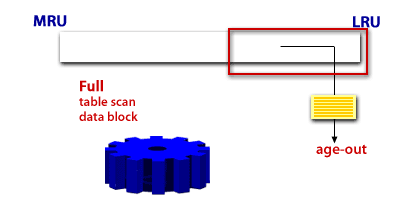
A scan of table data in which the database sequentially reads all rows from a table and filters out those that do not meet the selection criteria. All data blocks under the high water mark are scanned.
Index Clustering Factor
For a B-tree index, the index clustering factor measures the physical grouping of rows in relation to an index value, such as last name. The index clustering factor helps the optimizer decide whether
If the database performs a full table scan, then the database tends to retrieve the rows as they are stored on disk sorted by the index key. A clustering factor that is close to the number of rows indicates that the rows are scattered randomly across the database blocks in relation to the index key. If the database performs a full table scan, then the database would not retrieve rows in any sorted order by this index key.
The clustering factor is a property of a specific index, not a table. If multiple indexes exist on a table, then the clustering factor for one index might be small while the factor for another index is large. An attempt to reorganize the table to improve the clustering factor for one index may degrade the clustering factor of the other index.
- an index scan or
- full table scan
If the database performs a full table scan, then the database tends to retrieve the rows as they are stored on disk sorted by the index key. A clustering factor that is close to the number of rows indicates that the rows are scattered randomly across the database blocks in relation to the index key. If the database performs a full table scan, then the database would not retrieve rows in any sorted order by this index key.
The clustering factor is a property of a specific index, not a table. If multiple indexes exist on a table, then the clustering factor for one index might be small while the factor for another index is large. An attempt to reorganize the table to improve the clustering factor for one index may degrade the clustering factor of the other index.
Question:What happens to data blocks that are not read during a full-table scan?
High Water Mark
The High Water Mark reflects the "last" block that ever contained data, so the only blocks that are not read are the blocks that are allocated to the table but never contained any data. In addition, this prevents a large full-table scan from flushing all of the
other object data blocks from the data buffer. The size of the buffer is determined by the database administrator and for Oracle, separate buffers can be created for different tables. To maximize the use of buffers, perform a check on the buffer hit ratio.
The buffer hit ratio is the ratio of logical read requests to physical disk reads.A logical read is a request from a program for a record, while a physical read is a request from a database for a record. The equation for finding the buffer hit ratio is:
Equation for buffer hit ratio
Hit Ratio = ((Logical Reads - Physical Reads) / Logical Reads)
In general, the buffer hit ratio is a function of the application size of the buffer pool. An application with a very large customer table is not likely to benefit from an increase in buffers because the I/O is widely distributed across tables. Smaller applications will often see an improvement as the buffer size is increased.
The following query shows a typical buffer hit ratio:
Method 1- calculating the buffer hit ratio.
buffer1.sql - displays the buffer hit ratio
PROMPT *****************************************************
PROMPT HIT RATIO SECTION
PROMPT *****************************************************
PROMPT
PROMPT =========================
PROMPT BUFFER HIT RATIO
PROMPT =========================
PROMPT (should be > 70,
else increase db_block_buffers in init.ora)
SELECT TRUNC((1-(sum(decode(name,'physical reads',value,0))/
(sum(decode(name,'db block gets',value,0))+
(sum(decode(name,'consistent gets',value,0)))))
)* 100) " buffer hit ratio "
FROM v$SYSSTAT;
Method 2- calculating the buffer hit ratio.
Buffer2.sql
PROMPT *****************************************************
PROMPT HIT RATIO SECTION
PROMPT *****************************************************
PROMPT
PROMPT =========================
PROMPT BUFFER HIT RATIO
PROMPT =========================
PROMPT (should be > 70,
else increase db_block_buffers in init.ora)
COLUMN " logical_reads " FORMAT 99,999,999,999
COLUMN " phys_reads " FORMAT 999,999,999
COLUMN " phy_writes " FORMAT 999,999,999
SELECT A.value + B.value "logical_reads",
C.value "phys_reads",
D.value "phy_writes",
ROUND(100 * ((A.value+B.value)-C.value) / (A.value+B.value))
" buffer hit ratio"
FROM V$SYSSTAT A, V$SYSSTAT B, V$SYSSTAT C, V$SYSSTAT D
WHERE
A.statistic# = 37
AND
B.statistic# = 38
AND
C.statistic# = 39
AND
D.statistic# = 40;
SQL> @buffer1 ********************************************************** Hit Ratio Section ********************************************************** ========================= BUFFER HIT RATIO ========================= (should be > 70, else increase db_block_buffers in init.ora) logical_reads phys_reads phy_writes BUFFER HIT RATIO ------------- ------------ ------------ ---------------- 18,987,002 656,805 87,281 97
Be aware that the buffer hit ratio (as gathered from the V$ tables) measures the overall buffer hit ratio of the system since the Oracle instance was started. Because the V$ tables keep their information forever, your current buffer hit ratio could be far worse than the 97 percent shown in the example.
Buffer Hit Ratio
To get a short-term buffer hit ratio (i.e., five minutes elapsed), use Oracle's bstat-estat utility, and find the buffer get in the report.txt file. Oracle also provides a utility for predicting the benefit from
adding more buffers .
You must also be aware of the relationship between the DB File multi-block Read Count.
Optimal number of buffers
Adding memory to the buffers will decrease the available pool of memory in your host for other programs, and this decision should always be given careful consideration. Increasing the size of db_block_size will increase the size of the Oracle SGA. The values of db_block_size are multiplied by the value of db_block_buffers to determine the total amount of memory to allocate for Oracle's I/O buffers.
In general, db_block_size should never be set to less than 8K, regardless of the type of application. Even online transaction processing systems (OLTP) will benefit from using 8K blocks, while systems that perform many full-table scans will benefit from even larger block sizes. Depending on the operating system, Oracle can support up to 16K block sizes. Systems that perform full-table scans can benefit from this approach.
In general, db_block_size should never be set to less than 8K, regardless of the type of application. Even online transaction processing systems (OLTP) will benefit from using 8K blocks, while systems that perform many full-table scans will benefit from even larger block sizes. Depending on the operating system, Oracle can support up to 16K block sizes. Systems that perform full-table scans can benefit from this approach.
DB_BLOCK_SIZE
| Property | Description |
| Parameter type | Integer |
| Default value | 8192 |
| Modifiable | No |
| Range of values | 2048 to 32768, but your operating system may have a narrower range |
| Basic | Yes |
| Real Application Clusters | You must set this parameter for every instance, and multiple instances must have the same value. |
DB_BLOCK_SIZE specifies (in bytes) the size of Oracle database blocks. Typical values are 4096 and 8192. The value of this parameter must be a multiple of the physical block size at the device level. The value for DB_BLOCK_SIZE in effect at the time you create the database determines the size of the blocks. The value must remain set to its initial value. For Real Application Clusters, this parameter affects the maximum value of the FREELISTS storage parameter for tables and indexes. Oracle uses one database block
for each freelist group. Decision support system (DSS) and data warehouse database environments tend to benefit from larger block size values.
Short-term buffer hit ratio
The buffer hit ratio will fluctuate wildly as new transactions enter the database. You must measure the buffer hit ratio in short increments to get an accurate measure of current activity.
In the next lesson, we will examine adding data buffers.
In the next lesson, we will examine adding data buffers.
