| Lesson 2 | Index-organized tables |
| Objective | Explain how index-organized tables differ from normal tables. |
Index-organized Tables
In the beginning, the file was a simple way to store data on disk. As data was added to a file, the file grew larger. Retrieving data from a file was simple since the software read through the file until it found the right record. With database management systems, the concept of an index was introduced. With an index, the database software could quickly locate a particular value, usually by going through a B*-tree structure. An index value would point to a row containing data in the database. This type of retrieval was much faster and more consistent than retrieving data directly from a data file, but it always needed at least two logical input/output (I/O) operations–one to retrieve an index value and one to retrieve the data.
- What Are Index-Organized Tables?
An index-organized table has a storage organization that is a variant of a primary B-tree. Unlike an ordinary (heap-organized) table whose data is stored as an unordered collection (heap), data for an index-organized table is stored in a B-tree index structure in a primary key sorted manner. Each leaf block in the index structure stores both the key and nonkey columns. The structure of an index-organized table provides the following benefits:
- Fast random access on the primary key because an index-only scan is sufficient. And, because there is no separate table storage area, changes to the table data (such as adding new rows, updating rows, or deleting rows) result only in updating the index structure.
- Fast range access on the primary key because the rows are clustered in primary key order.
- Lower storage requirements because duplication of primary keys is avoided. They are not stored both in the index and underlying table, as is true with heap-organized tables.
Index-organized tables have full table functionality. They support features such as constraints, triggers, LOB and object columns, partitioning, parallel operations, online reorganization, and replication. And, they offer these additional features:- Key compression
- Overflow storage area and specific column placement
- Secondary indexes, including bitmap indexes.
Index-organized tables are ideal for OLTP applications, which require fast primary key access and high availability. Queries and DML on an orders table used in electronic order processing are predominantly primary-key based and heavy volume causes fragmentation resulting in a frequent need to reorganize. Because an index-organized table can be reorganized online and without invalidating its secondary indexes, the window of unavailability is greatly reduced or eliminated. Index-organized tables are suitable for modeling application-specific index structures. For example, content-based information retrieval applications containing text, image and audio data require inverted indexes that can be effectively modeled using index-organized tables. A fundamental component of an internet search engine is an inverted index that can be modeled using index-organized tables. - How IOT stores Data:
With an index-organized table, the data in the table is stored within the leaf nodes, or bottom nodes, of the B*-tree index. This structure allows the Oracle database to retrieve values directly from the index structure, without having to go to a separate storage area for the data in the database row. The following series of imagess compares the way that data is retrieved from a standard table and with how it is retrieved from an index-organized table:
Indexing using Oracle Database
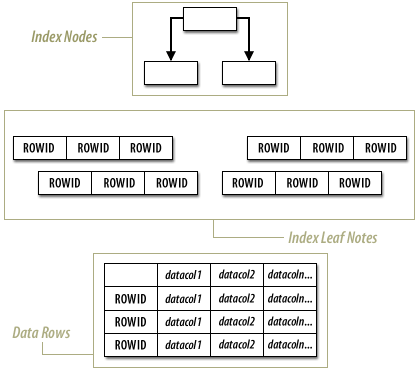
The image illustrates the structure of an index-organized table (IOT) in an Oracle database.
The rows appear as tabular data based on the information depicted in the image.
Here's how the data rows could be represented in a table format:
| ROWID | datacol1 | datacol2 | datacoln... |
|---|---|---|---|
| ROWID | value1 | value2 | value_n |
| ROWID | value1 | value2 | value_n |
| ROWID | value1 | value2 | value_n |
| ... | ... | ... | ... |
In this structure:
- ROWID
- Serves as a unique identifier for each row.
- datacol1, datacol2, ... datacoln
- Represent columns containing data values for each row.
- Index Nodes
- At the top represent the B-tree structure, which directs to
- Index Leaf Nodes containing ROWIDs.
- Data Rows
- Follow the index leaf nodes, providing the actual data.
If you need a more detailed breakdown of specific data columns or further clarification on index structures, feel free to ask!
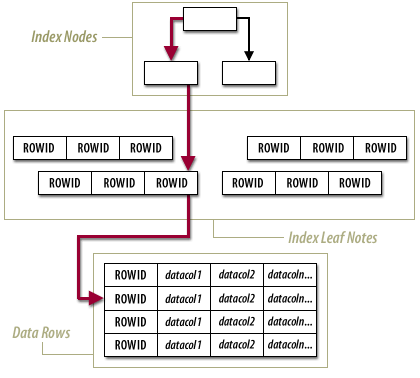
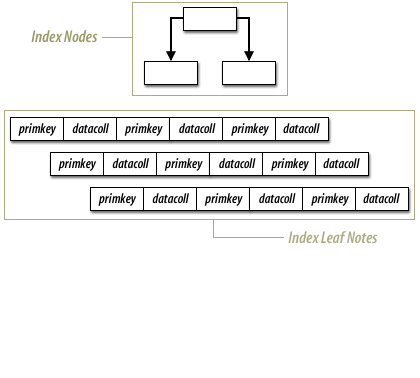
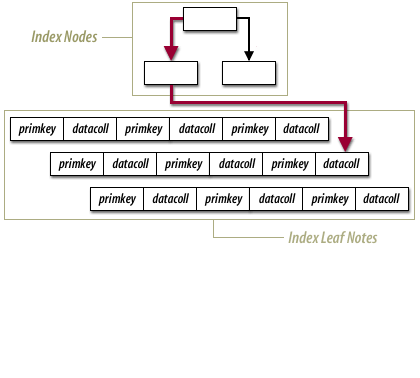
Standard Tables versus index-organized Tables
With an Index Organized Tables, a table is stored in an index structure. This imposes physical order on the rows themselves.
Whereas in a heap, the data is stuffed wherever it might fit, in an index organized table the data is stored in sorted order, according to the primary key. Efficient when most of the column values are included in the primary key. You access the index as if it were a table and the data is stored in a B-tree like structure.
An (IOT) index-organized table stores the entire contents of the table's row in a B-tree index structure. An IOT provides fast access for queries that have exact matches and/or range searches on the primary key. Even though an IOT is implemented as a B-tree index structure, it is created via the
statement.
For example,
An (IOT) index-organized table stores the entire contents of the table's row in a B-tree index structure. An IOT provides fast access for queries that have exact matches and/or range searches on the primary key. Even though an IOT is implemented as a B-tree index structure, it is created via the
CREATE TABLE...ORGANIZATION INDEX
statement.
For example,
create table prod_sku (prod_sku_id number ,sku varchar2(256), constraint prod_sku_pk primary key(prod_sku_id, sku) ) organization index;
Overview of Indexes
An index is an optional structure, associated with a table or table cluster, that can sometimes speed data access. By creating an index on one or more columns of a table, you gain the ability in some cases to retrieve a small set of randomly distributed rows from the table. Indexes are one of many means of reducing disk I/O. If a heap-organized table has no indexes, then the database must perform a full table scan to find a value. For example, without an index, a query of location 2700 in the hr.departments table requires the database to search every row in every table block for this value. This approach does not scale well as data volumes increase. For an analogy, suppose an HR manager has a shelf of cardboard boxes. Folders containing employee information are inserted randomly in the boxes. The folder for employee Whalen (ID 200) is 10 folders up from the bottom of box 1, whereas the folder for King (ID 100) is at the bottom of box 3. To locate a folder, the manager looks at every folder in box 1 from bottom to top, and then moves from box to box until the folder is found. To speed access, the manager could create an index that sequentially lists every employee ID with its folder location:
ID 100: Box 3, position 1 (bottom) ID 101: Box 7, position 8 ID 200: Box 1, position 10 . . .
Similarly, the manager could create separate indexes for employee last names, department IDs, and so on. In general, consider creating an index on a column in any of the following situations:
- The indexed columns are queried frequently and return a small percentage of the total number of rows in the table.
- A referential integrity constraint exists on the indexed column or columns. The index is a means to avoid a full table lock that would otherwise be required if you
update the parent table primary key, merge into the parent table, or delete from the parent table. - A unique key constraint will be placed on the table and you want to manually specify the index and all index options.