Describe the characteristics of Horizontal Partitioning
Characteristics of Horizontal Partitioning in Database Design
Horizontal partitioning, sometimes called row partitioning or sharding—is a physical design technique that divides the rows of a table into multiple smaller tables or table partitions. Each partition contains the same column structure but stores a subset of the rows based on a defined rule. Modern relational systems such as Oracle 23ai, PostgreSQL 16, and SQL Server 2022 support horizontal partitioning natively, making it an essential strategy for performance, scalability, lifecycle management, and operational efficiency.
Below are the primary characteristics of horizontal partitioning:
Row-based distribution: A table is divided into multiple segments of data, each containing a subset of the rows. These segments are typically stored as physical partitions managed by the RDBMS. The structure of each partition is identical, but the row sets differ.
Partition key selection: The RDBMS uses a column—or a group of columns—as the partition key. Good partition keys:
exhibit high cardinality,
align with common filtering patterns,
support predictable data distribution, and
minimize data movement over time.
Examples of effective partition keys include date columns, customer regions, or status codes.
Improved performance: Because the RDBMS can target a specific partition instead of scanning the entire table, query execution time decreases significantly. Modern optimizers use partition pruning and partition-wise joins to eliminate unnecessary work.
Scalability: Horizontal partitioning supports large, fast-growing datasets by distributing storage and workload across multiple partitions. In distributed environments, partitions can reside on different nodes, enabling linear or near-linear scale-out.
Operational efficiency: Maintenance operations—including backups, index rebuilds, compression, or archival—can be performed at the partition level. This reduces downtime and isolates maintenance to smaller data sets.
Data lifecycle management: Horizontal partitioning is commonly used to separate current and historical data. Old partitions can be compressed, archived, or even dropped without affecting current transactional workloads.
Flexibility and modularity: Partitions can be added, removed, merged, split, or rebalanced independently. This allows the database to evolve gracefully as data volumes change.
Horizontal partitioning is most effective when the partitioning scheme aligns with how applications access data. When well-designed, it enhances performance, increases throughput, and reduces maintenance overhead.
Horizontal Splitting
Horizontal splitting occurs when a single logical table is divided into multiple physical tables or partitions that share the same columns. This approach becomes necessary when a table grows so large that queries, joins, or scans slow down significantly.
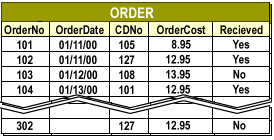
Consider an Orders table for the “Stories on CD” application. Over years of business activity, the table may accumulate hundreds of thousands or millions of rows. While all data must remain available, not all data is needed for everyday operations. Most customer-service queries focus on recent orders, not orders from several years ago.
By splitting the table into current and historical partitions or tables, the database engine can limit most queries to a far smaller dataset. Queries scanning only the “current” partition benefit from:
reduced I/O,
more efficient index usage, and
less buffer cache pressure.
When necessary, queries can access all partitions, but the RDBMS still executes them more efficiently than scanning one large monolithic table.
Historical Data in the Context of Horizontal Partitioning
Historical data consists of rows that remain important for compliance, trend analysis, or auditing but are no longer frequently accessed. Horizontal partitioning provides a structured way to store historical data without degrading the performance of day-to-day operations.
Physical separation: Historical partitions may reside on slower disks, archival storage groups, or even separate servers in distributed systems.
Dedicated partitions: Partitions are typically defined by time—for example, months, quarters, or years. This makes retention and archival policies predictable.
Independent management: Each partition may have:
a unique backup schedule,
stricter compression levels,
different indexing strategies,
custom access controls.
Minimal impact on current operations: By isolating older records:
scans become smaller,
indexes remain shallow,
locking and latching contention decreases.
Common use cases:
Archiving older financial, sales, or sensor data
Meeting legal retention or auditing requirements
Supporting long-term analytics without affecting OLTP workloads
This structure is typical of transactional order data commonly divided into current and historical partitions.
Partitioning by Date
As “Stories on CD” grows, the volume of order data increases rapidly. Employees frequently query only the most recent orders—often the last quarter. Partitioning by date allows the database to store each quarter of data in its own partition.
Advantages include:
faster access to recent orders,
smaller partitions for maintenance,
predictable archival or purging cycles.
Partitioning also aligns with the principles of normalization: a single logical table remains unified at the conceptual level, while the physical storage is optimized beneath it. The next lesson discusses the disadvantages of horizontal partitioning and considerations for when partitioning may introduce overhead.
[1]historical data: Data that is no longer part of active operations but remains stored for reference, compliance, or analysis. Historical rows typically inhabit older partitions separated by time.