Introduction to Third Normal Form (3NF)
Sound relational database design requires adherence to specific rules that ensure data integrity and reduce redundancy. Among the key techniques used to achieve this is normalization, a process that systematically organizes data within relational tables to eliminate anomalies and preserve logical consistency.
Understanding the Goal of Normalization
When designing a database for an enterprise, the goal is to create a structure that accurately represents:
- The entities and attributes that describe the data,
- The relationships among these entities, and
- The constraints that maintain data validity within the enterprise context.
Normalization is achieved by examining functional dependencies between attributes—how one attribute determines another. Through successive stages known as normal forms, redundant data and undesirable dependencies are systematically removed. The Third Normal Form (3NF) is one of the most critical milestones in this process.
Learning Objectives
After completing this module, you should be able to:
- Explain the requirements for achieving Third Normal Form (3NF).
- Identify and eliminate transitive dependencies.
- Normalize a relation to 3NF.
- Describe Codd’s 12 rules for a fully relational database system.
- Relate Codd’s rules to normalization principles.
- Recognize when normalization beyond 3NF (e.g., BCNF) is necessary.
- Define and evaluate the role of denormalization in performance optimization.
Third Normal Form Explained
Third Normal Form (3NF) builds upon the foundation of the Second Normal Form (2NF). A table is in 3NF if:
- It is already in Second Normal Form (2NF), and
- Every non-prime attribute (an attribute not part of any candidate key) is non-transitively dependent on the primary key.
In simpler terms, no non-key attribute should depend on another non-key attribute. This rule ensures that every piece of information in a table depends solely on the table’s primary key.
Why 3NF Matters
- Eliminates Anomalies: 3NF removes insertion, update, and deletion anomalies that occur when redundant or derived data is stored in multiple places.
- Improves Maintainability: Each non-key attribute has a clear purpose, leading to better performance and easier database updates.
- Preserves Data Integrity: Changes to one fact (such as a teacher’s address) affect only one row, ensuring referential consistency throughout the database.
While 3NF is a strong design goal, not every database must be fully normalized. Some applications—especially those requiring high-speed analytical queries—may selectively denormalize data to improve performance.
Example: Third Normal Form in Practice
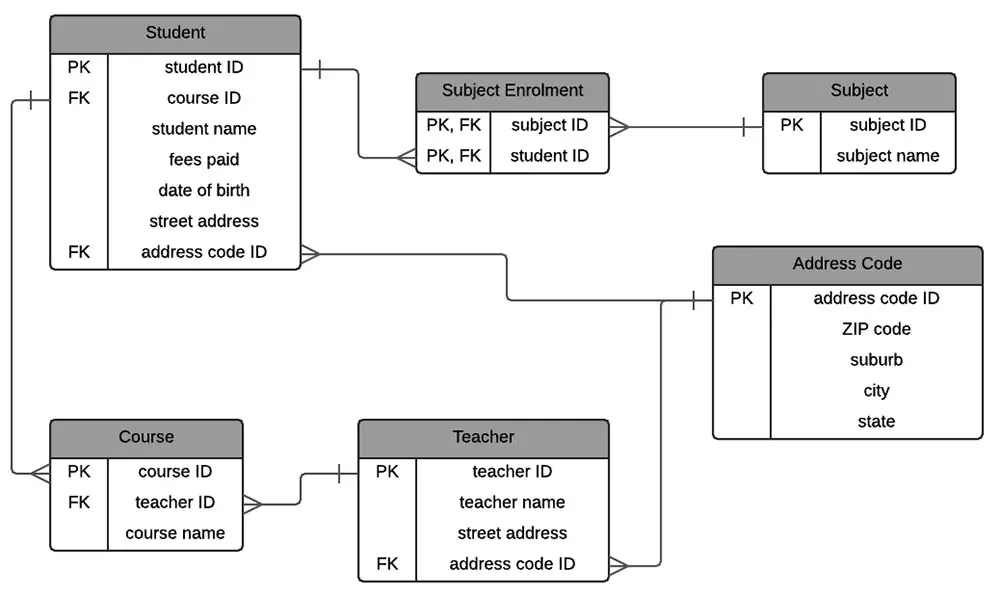
- Entities: Student, Course, Teacher, Subject, and Address Code.
- Primary Keys (PK): Each entity has a unique identifier such as
student_id,course_id,teacher_id, etc. - Foreign Keys (FK): These establish referential integrity between entities (e.g., Course → Teacher, Student → Course).
- Junction Table:
Subject Enrollmentresolves the many-to-many relationship between Students and Subjects. - Data Integrity: Address information is centralized in the
Address Codeentity, eliminating redundancy.
Beyond Third Normal Form
Although 3NF eliminates most redundancy and transitive dependencies, some databases benefit from further normalization. The Boyce-Codd Normal Form (BCNF) strengthens 3NF by addressing situations where multiple candidate keys can still lead to anomalies. Understanding when to stop normalizing—and when to denormalize—is an essential skill for database architects.
Summary
Third Normal Form (3NF) represents the balance between logical purity and practical performance. It eliminates transitive dependencies, ensures each fact is stored once, and promotes stable, scalable database systems. The result is a clean relational model that supports long-term maintainability and data integrity—key goals for any enterprise-level database.