Suppose you issue a simple SELECT statement against the PUBS database:
SELECT State
FROM Authors
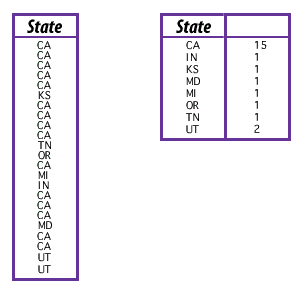
The result is 23 rows of states, ranging from California (15 instances) to Utah (2 instances). Each of the other states represented appears once. The result is 23 rows of states, ranging from California (15 instances) to Utah (2 instances). Each of the other states represented appears once. Suppose you wanted to show the count of each state in the table. This is where grouping comes in. If you can group by state, then count the states returned, correct? That is exactly what you will do. Here is the statement that will do the trick:
SELECT State, count(State)
FROM Authors
GROUP BY State
Two things are happening here.
First, you indicate the column (State) and table (Authors) that you want to use.
By using the COUNT function, SQL will return the count of all rows returned for that column.
By adding the GROUP BY clause, SQL will condense the rows that have the same state, eliminating duplicates:
The GROUP BY clause will condense the rows with the same state, eliminating duplicates.
Note that the second column has no heading. This is because the column is calculated on the fly, without specifying a column heading. Your application may label the column with NULL, No Column Heading, or some other indication that the column heading was not provided.
Example of GROUP BY clause
Null or blank values can be returned as part of your GROUP BY query's result set. These occur when the values used by the GROUP BY clause include blank values in the database table. If you group by state, for example, and you have blank values for one of the states, you will receive one of your GROUP BY classes as a blank, or null, value. These are not errors in the query, they are just indications that you have values missing from a column you have indicated in the GROUP BY clause.
This section examines the GROUP BY clause, which is used in conjunction with the SELECT statement. It allows you to group identical data into one subset rather than listing each record. The GROUP BY clause is at its most powerful when used with summarizing and aggregating functions of SQL, which are covered in the next section. The GROUP BY clause is also very useful with subqueries. The aim of this module is to get a handle on how GROUP BY works; the next section shows you how to use it more effectively
The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group the results by one or more columns.
The syntax for the GROUP BY clause is:
SELECT column1, ... , column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, ... , column_n;
Using SQL SUM function Example
Let us look at a SQL GROUP BY query example that uses the SQL SUM function.
This GROUP BY example uses the SUM function to return the name of the department and the total sales (for the department).
SELECT department, SUM(sales) AS "Total sales"
FROM order_details
GROUP BY department;
Because you have listed one column (the department field) in your SQL SELECT statement that is not encapsulated in the SUM function, you must use the GROUP BY Clause. The department field must, therefore, be listed in the GROUP BY clause.
SQL GROUP BY function
The GROUP BY statement is used in conjunction with the aggregate functions to group the result-set by one or more columns. SQL GROUP BY Syntax
SELECT column_name, aggregate_function(column_name)
FROM table_name WHERE
column_name operator value
GROUP BY column_name;