| Lesson 2 | Tuning the Oracle data buffer |
| Objective | Describe the components of the Oracle data buffer. |
Oracle Buffer Cache
The in-memory area of the (SGA) System Global Area is where incoming Oracle data blocks are kept is named the buffer cache. On standard UNIX databases, the data is read from disk into the UNIX buffer where it is transferred into the Oracle buffer.
The size of the buffer cache can have a huge impact on Oracle system performance. The larger the buffer cache, the greater the likelihood that data from a prior transaction will reside in the buffer, thereby avoiding a physical disk I/O. It would be ideal if you could create one buffer for each database page, ensuring that Oracle would read each block only once. However, the costs of memory in the real world make this prohibitive.
At best, you can only allocate a small number of real-memory buffers, and Oracle will manage this memory for you. Oracle utilizes a (LRU) least-recently-used algorithm to determine which database pages are to be flushed from memory.
The following SlideShow will guide you through the buffer utilization process step-by-step.
The size of the buffer cache can have a huge impact on Oracle system performance. The larger the buffer cache, the greater the likelihood that data from a prior transaction will reside in the buffer, thereby avoiding a physical disk I/O. It would be ideal if you could create one buffer for each database page, ensuring that Oracle would read each block only once. However, the costs of memory in the real world make this prohibitive.
At best, you can only allocate a small number of real-memory buffers, and Oracle will manage this memory for you. Oracle utilizes a (LRU) least-recently-used algorithm to determine which database pages are to be flushed from memory.
The following SlideShow will guide you through the buffer utilization process step-by-step.
Buffer Utilization Process
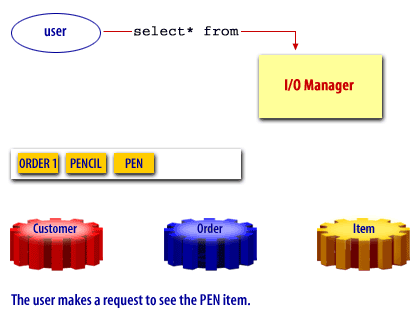
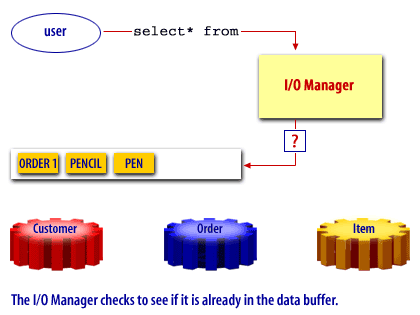
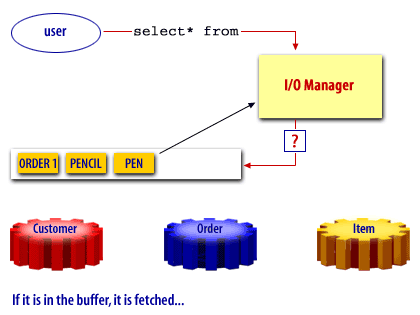
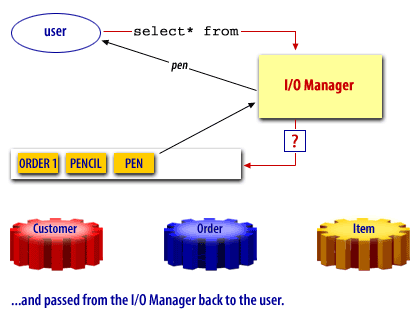
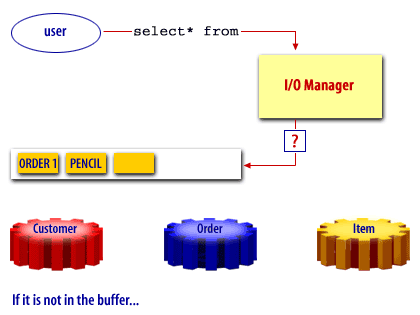
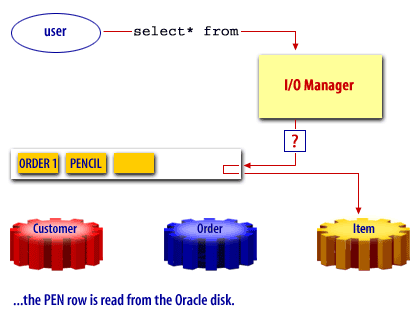
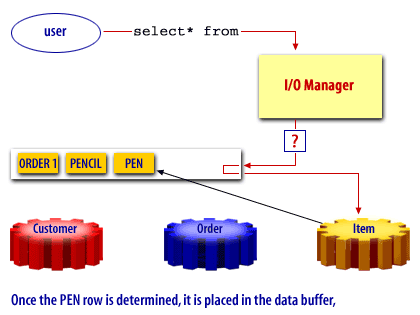
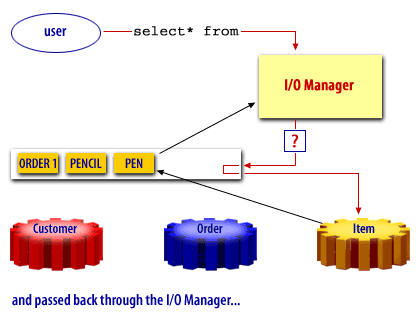
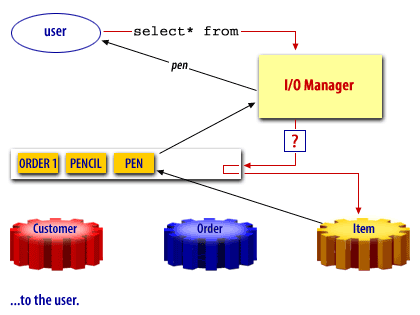
Oracle Buffer Cache
Oracle, like many other products uses a buffer cache to manage data blocks in memory. The buffer cache holds copies of data blocks read from the data files comprising the database.
The buffer cache is located in the (SGA) System Global Area and is shared by all processes connected to an instance. Some advantages of using a buffer cache are
A free buffer is a buffer that has not been modified and is available for reuse. Pinned buffers are buffers that are currently being accessed so are not candidates for replacement. The hashed chain list holds the same buffers as the LRU and LRUW lists, but buffers on this list are arranged depending on their data block addresses. It is essentially used to cache blocks in the buffer pool. When a user process needs to access a block, it first looks in the hashed chain list to see if the block is already in memory. If found, the block can be immediately used and if not, the block has to be read from a datafile on disk into a buffer in the cache. Before a block can be read into a free buffer needs to be identified and pinned.
- eliminating physical I/O on frequently accessed blocks,
- providing fast access path to find block(s) in memory and
- help in maintaining concurrency control and multi-version consistency on blocks.
- the dirty list (also called the write list or LRUW),
- the least recently used list (also called the replacement list or LRU) and
- the hashed chain list.
A free buffer is a buffer that has not been modified and is available for reuse. Pinned buffers are buffers that are currently being accessed so are not candidates for replacement. The hashed chain list holds the same buffers as the LRU and LRUW lists, but buffers on this list are arranged depending on their data block addresses. It is essentially used to cache blocks in the buffer pool. When a user process needs to access a block, it first looks in the hashed chain list to see if the block is already in memory. If found, the block can be immediately used and if not, the block has to be read from a datafile on disk into a buffer in the cache. Before a block can be read into a free buffer needs to be identified and pinned.
Cache size Database blocks
Just as the size of the buffer cache can have dramatic impact on your system, so will the database block size.
Roll your cursor over the areas outlined in red to see pop-up explanations of database blocks.
Roll your cursor over the areas outlined in red to see pop-up explanations of database blocks.
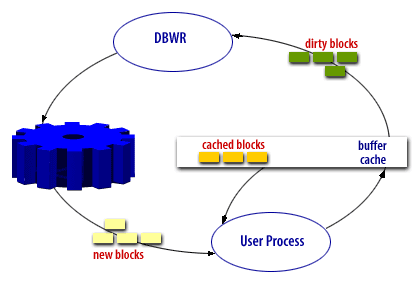
- This is the permanent residence for the Oracle data blocks.
- These are new data blocks.
- This is the user process that is requesting to see a row within an Oracle data block.
- This is the Oracle data buffer cache which contains data blocks that have been read from disk into the Oracle data buffer cache.
- These are blocks that have been modified but not yet written back to disk
- This is the Oracle background database writer process.
DBWR (DataBase Writer) is an Oracle background process created when you start a database instance. The DBWR writes modified data (dirty buffers) from the SGA into the Oracle database files. When the SGA data buffer cache fills, the DBWR process selects buffers using an LRU algorithm and writes them to disk.
Database Blocks
For batch-oriented reporting databases, very large block sizes are always recommended. As a general rule, 8K block sizes (db_block_size) will benefit most Oracle databases.
Control block size
The db_block_size parameter is used to control the physical block size of the data files, and unlike other relational databases, Oracle allocates the data files on your behalf when the CREATE TABLESPACE command is issued. One of the worst things that can happen to a buffer cache is the running of a full-table scan on a large table. In order to optimize performance, Oracle allows for several extensions to the basic parameters, and one of the most important interactions is between the db_block_size parameter and the db_file_multiblock_read_count. We will review this in a later lesson. I/O is the single most important slowdown in a client/server system, and the more relevant the data that can be grabbed in a single I/O, the better the performance. If you make appropriate use of Oracle clusters, you can reap dramatic performance improvements by switching to large block sizes. In the next lesson, you will learn to calculate the buffer hit ratio.