| Lesson 4 | Partitioning enhancements |
| Objective | Identify the features for partitioned tables in Oracle |
Oracle Partitioned Tables
Oracle partitioning is a mature Oracle Database capability that lets you split a large table (and its indexes)
into smaller, manageable pieces called partitions. Each partition remains part of the same logical table,
but can be managed and accessed independently. The practical outcome is:
faster queries through partition pruning, and simpler operations because many maintenance tasks can run at the partition level rather than against an entire table.
In this lesson, focus on the features that DBAs and developers use most often when working with partitioned tables:
In this lesson, focus on the features that DBAs and developers use most often when working with partitioned tables:
- Partitioning methods: range, list, hash, and composite combinations (for example, range-list or range-hash).
- Partition-aware performance: partition pruning and partition-wise joins when the SQL predicates align with the partition key.
- Operational manageability: partition maintenance operations (add, drop, split, merge, move, truncate) and index strategy (local vs global).
- Data movement and ETL: controlled row movement when partition keys change, plus fast load patterns such as partition exchange.
Table Partitioning Improvements
The most visible “improvements” in real systems are not a single new feature, but a set of capabilities that make
partitioning safe (data stays where it belongs), scalable (operations stay bounded), and fast
(Oracle can eliminate partitions early).
-
Row movement when partition keys change.
If an UPDATE changes a row’s partition key, the row may no longer belong in its original partition. Oracle can move the row into the correct partition when row movement is enabled. This keeps partitions aligned with the partition definition and helps the optimizer continue to prune partitions reliably.
Practical note: row movement is a design choice. If you require strict immutability of the partition key (common in time-based partitioning), enforce it in application logic or with constraints/triggers. -
Partition maintenance operations.
Over time, data distribution changes. Oracle supports partition-level maintenance so you can reshape storage and data without redesigning the table. Common operations include:- SPLIT a partition when a single partition grows too large.
- MERGE partitions when older ranges become small or operationally unnecessary as separate units.
- COALESCE partitions in hash partitioning scenarios to reduce partition count with minimal disruption.
- MOVE partitions to different tablespaces (often used for tiering hot vs. cold data).
-
Automatic cleanup of retired partitions.
Many partitioning designs naturally support “rolling window” data: add new partitions for current data and drop/truncate old partitions as they age out. This is typically faster and safer than deleting millions of rows, because dropping a partition removes data as a unit. -
Partition exchange for fast load and archive workflows.
A classic high-throughput pattern is partition exchange: load data into a standalone staging table, validate it, and then exchange that table with a target partition. This enables fast “load/refresh” operations while keeping the rest of the partitioned table online and stable.
As you progress deeper into Oracle partitioning, you will also encounter modern extensions that broaden how partitioning can be applied:
- Interval partitioning: Oracle automatically creates new range partitions as new key values arrive (common for date-driven data).
- Reference partitioning: a child table inherits partitioning from a parent table via foreign key relationship, simplifying joins and maintenance.
- System partitioning: the application explicitly chooses the target partition (useful for certain sharding-style distributions).
- Local vs global indexes: local indexes align with partitions (easier maintenance); global indexes can support broader access patterns but can add maintenance complexity.
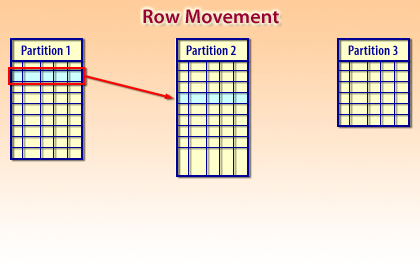
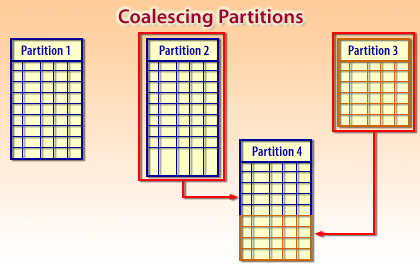
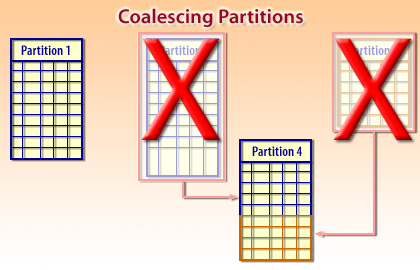
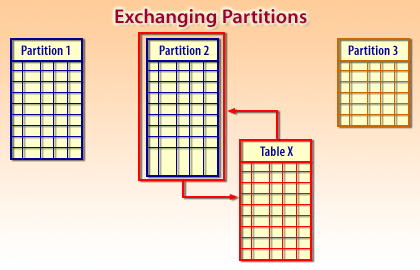
- Row movement keeps data aligned when partition keys change.
- Partition maintenance operations let you rebalance and simplify partition layouts as data distribution changes.
- Retiring old partitions supports rolling-window retention with bounded operational cost.
- Partition exchange enables fast load/refresh patterns using staging tables.
Oracle Block Size
The database standard block size is defined by the
Oracle can also support multiple nonstandard block sizes through separate buffer cache “subcaches” configured with parameters such as
In modern deployments, multiple block sizes are most relevant when you must transport data between environments with different block-size choices (for example, during transportable workflows, consolidations, or specific platform constraints). For many OLTP systems, a single standard block size remains the simplest and most common approach.
DB_BLOCK_SIZE parameter when the database is created.
Oracle uses this as the default block size for the SYSTEM tablespace and for most tablespaces in the database.
Oracle can also support multiple nonstandard block sizes through separate buffer cache “subcaches” configured with parameters such as
DB_2K_CACHE_SIZE, DB_4K_CACHE_SIZE, DB_16K_CACHE_SIZE, and DB_32K_CACHE_SIZE
(depending on platform support). You can then create tablespaces that use those nonstandard block sizes.
In modern deployments, multiple block sizes are most relevant when you must transport data between environments with different block-size choices (for example, during transportable workflows, consolidations, or specific platform constraints). For many OLTP systems, a single standard block size remains the simplest and most common approach.
[1]
Partitioned table: A single logical table whose rows are stored in multiple partitions. Each partition is a physical segment that can be managed
independently, while SQL continues to treat the object as one table.