| Lesson 4 | Creating an index |
| Objective | Create indexes on database tables in Oracle 23ai |
Create Indexes on Database Tables (Oracle 23ai)
You can create an index on any existing table to provide Oracle Database 23ai with an additional access path for queries. Index creation is performed using DDL, and (as with other schema objects) the definition becomes part of the schema metadata. Once an index exists, Oracle can consider it during optimization without requiring application changes.
Creating indexes is a physical design activity: it does not change relational meaning, keys, or entity relationships, but it can drastically change performance characteristics (logical I/O, physical I/O, and CPU). The goal is not to “index everything,” but to create indexes that match how your workload filters, joins, and orders data.
When Creating an Index Makes Sense
- Selective predicates: Queries frequently filter by a column (or leading columns of a composite key) and return a small percentage of the table.
- Join performance: Join predicates repeatedly reference the same columns (commonly foreign keys).
- Uniqueness enforcement: A unique constraint or primary key requires uniqueness verification.
- Ordered access: Queries often request rows in a predictable order where an index can reduce sorting.
When Creating an Index Can Hurt
- Write-heavy tables: Each index increases insert/update/delete work, because Oracle must maintain index entries for DML that affects indexed columns.
- Low selectivity columns (OLTP): Indexing a column with very few distinct values can be inefficient for highly concurrent updates (the access pattern matters).
- Redundant indexes: Multiple indexes with the same leading columns can duplicate overhead with little benefit.
CREATE INDEX Syntax
The basic syntax for creating an index consists of the clauses shown below. In practice, you’ll often add storage and
operational clauses (for example, TABLESPACE and ONLINE) once you move beyond simple examples.
| CREATE | Starts the DDL statement. Indexes are schema objects and are created with DDL. |
UNIQUE / BITMAP |
Optional. Use UNIQUE to enforce uniqueness at the index level. Use BITMAP to create a
bitmap index. In most designs, these are alternative approaches with different workload goals.
|
INDEX |
Required keyword indicating the object type being created. |
[schema.]index_name |
The index name must be unique within its schema. You can optionally prefix the schema if you are creating the index in a schema other than your current user. |
ON [schema.]table_name |
Required. Identifies the table to be indexed. You may need schema qualification depending on privileges and current schema context. |
(col1, col2, ...) |
The indexed columns (or expressions). For B-tree indexes, you can define a composite index across multiple columns. Oracle supports up to 32 columns in a B-tree index definition. |
ASC / DESC |
Optional per column. Sorting direction is specified inside the column list (for example,
(last_name ASC, first_name ASC) or (created_ts DESC)). The default is ascending.
|
TABLESPACE |
Optional but common in production. Places the index segment in a specific tablespace to separate index I/O from table I/O or to align with storage policy. |
ONLINE |
Optional. Allows index creation with reduced application disruption in many operational scenarios (availability constraints still apply based on edition, workload, and object types). |
Example: Create a Single-Column Index
If you want to add an index for the BIDDER_CLIENT_ID column in the BID table, you can create a
standard B-tree index as follows:
CREATE INDEX bid_client_idx
ON bid (bidder_client_id ASC);
This index allows duplicate values because it is not declared UNIQUE. Oracle stores B-tree keys in ascending
order by default, but explicitly specifying ASC makes the design intent clear—especially when you later review
the data dictionary or compare definitions across environments.
If you define a PRIMARY KEY or UNIQUE constraint, Oracle typically creates (or requires) a unique
index to support enforcement. In other words, some indexes exist primarily to enforce relational constraints, not to
accelerate ad-hoc query filters.
Common Index Patterns You Should Recognize
Composite Indexes
A composite (multi-column) index supports predicates that reference the leading column(s) efficiently. The order of columns matters because it determines which predicates can use an index range scan without additional work.
CREATE INDEX bid_client_status_idx
ON bid (bidder_client_id ASC, bid_status ASC);
This index is useful when queries filter by bidder_client_id alone or by both columns together. It is not
designed for queries that filter only by bid_status.
Descending Indexes
Use descending keys when your workload repeatedly retrieves “most recent” rows by a sortable value (for example, a timestamp). This can reduce sorting and improve top-N patterns when the index matches the requested order.
CREATE INDEX bid_created_ts_desc_idx
ON bid (created_ts DESC);
Function-Based Indexes
If application predicates apply functions to columns, a normal index may not be usable. A function-based index stores the computed expression so Oracle can use it for matching predicates.
CREATE INDEX bidder_lastname_upper_idx
ON bidder (UPPER(last_name));
This enables efficient access for predicates such as:
SELECT bidder_id, last_name
FROM bidder
WHERE UPPER(last_name) = 'SMITH';
Unique Indexes
A unique index ensures that no two rows can store the same key value combination. Unique indexes are commonly used to enforce candidate keys when they are not declared as primary keys, or to support uniqueness constraints.
CREATE UNIQUE INDEX bidder_email_uq_idx
ON bidder (email_address);
Bitmap Indexes
Bitmap indexes store key information differently from B-tree indexes and are often used in analytic workloads where columns have relatively low cardinality and queries involve combinations of conditions across multiple columns. Bitmap indexes are generally not designed for highly concurrent OLTP updates on the indexed column.
CREATE BITMAP INDEX bid_status_bm_idx
ON bid (bid_status);
Operational Best Practices After Creating an Index
1) Validate the Definition in the Data Dictionary
After creation, confirm the index type, uniqueness, and status in USER_INDEXES, and confirm the column list
and order in USER_IND_COLUMNS.
SELECT index_name, index_type, uniqueness, status
FROM user_indexes
WHERE table_name = 'BID';
SELECT index_name, column_name, column_position, descend
FROM user_ind_columns
WHERE table_name = 'BID'
ORDER BY index_name, column_position;
2) Ensure Statistics Are Current
Oracle’s optimizer choices depend on statistics. In most environments, statistics are gathered automatically. If you create indexes as part of a change window (or after a bulk load), ensure that statistics are current so the optimizer can evaluate the new access path correctly.
3) Keep Index Design Aligned With Workload
Creating an index is easy; keeping it justified is the real discipline. If an index is rarely used but introduces DML overhead, it becomes technical debt. In production systems, index strategy should be driven by query patterns, not by general rules.
Overview of Indexed Clusters
Oracle also supports table clusters, which physically co-locate rows from one or more tables based on a shared cluster key. An indexed cluster is a table cluster that uses a B-tree index on the cluster key to locate clustered rows. In a clustered design, rows that share a cluster key value are stored near each other in the same data blocks, which can reduce I/O for join patterns that repeatedly access the same related row sets.
Indexed clusters can be useful when:
- Two tables are frequently joined by the same key (for example,
department_id). - Queries repeatedly retrieve rows for a single cluster key value.
- Physical co-location reduces block reads compared to scattered storage.
Clusters are a physical storage strategy. They trade flexibility for locality: they can improve some join/access patterns, while making other patterns less efficient. In modern Oracle designs, clusters are used selectively; they are most appropriate when the access pattern is stable and strongly key-centric.
The example below creates an indexed cluster (no HASHKEYS clause, so this is not a hash cluster), then creates
a cluster index on the cluster key.
Example: Indexed Cluster
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 512;
CREATE INDEX idx_emp_dept_cluster
ON CLUSTER employees_departments_cluster;
You then create the clustered tables and specify the cluster key column as part of the table definition:
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster (department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster (department_id);
When rows are inserted, Oracle stores related rows for a given department_id together in the same data blocks
(as space permits). The cluster index provides the entry point for locating the correct block range for a given key.
Examine the following diagram. It contrasts clustered storage (left) with conventional unclustered table storage (right).
The clustered structure groups employee and department rows by department_id, improving locality for key-based
access.
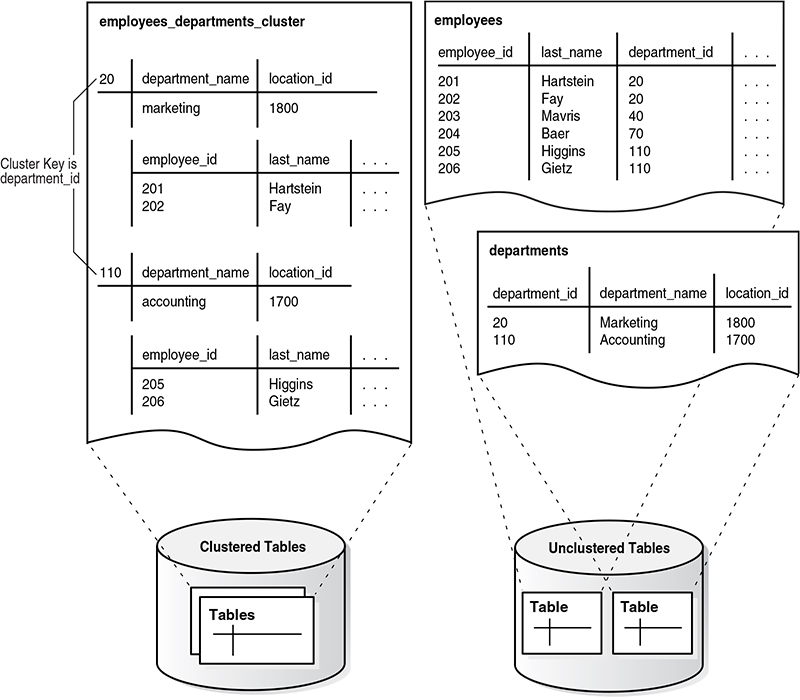
employees_departments_cluster
Cluster Key: department_id
department_id = 20
departments row:
department_name = Marketing
location_id = 1800
employees rows:
employee_id = 201, last_name = Hartstein
employee_id = 202, last_name = Fay
department_id = 110
departments row:
department_name = Accounting
location_id = 1700
employees rows:
employee_id = 205, last_name = Higgins
employee_id = 206, last_name = Gietz
employees (unclustered example)
employee_id, last_name, department_id, ...
201, Hartstein, 20
202, Fay, 20
203, Mavris, 40
204, Baer, 70
205, Higgins, 110
206, Gietz, 110
departments (unclustered example)
department_id, department_name, location_id
20, Marketing, 1800
110, Accounting, 1700
Interpretation: In a clustered design, rows that share the same cluster key value are stored together, reducing block reads for key-based access and repeated joins on the cluster key. In unclustered storage, related rows are not guaranteed to be co-located, and Oracle may need to visit more blocks to assemble the same logical result.
The next lesson explores storage considerations for index structures, including how index blocks are organized, how fragmentation can occur, and which maintenance operations are appropriate when index storage becomes inefficient.