| Lesson 2 | Re-sequencing Oracle table rows to reduce I/O |
| Objective | Re-sequence rows in an Oracle table. |
Re-sequencing Oracle table rows
A problem with all relational databases is that the physical sequence of the table rows does not always match the order of the index that accesses the table. To illustrate this concept, examine the following Slide Show that illustrates a CUSTOMER table using a CUST_NBR index:
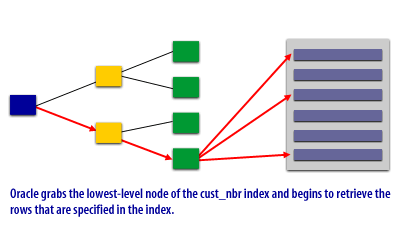
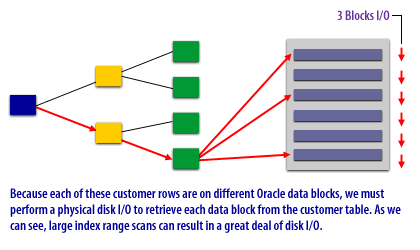
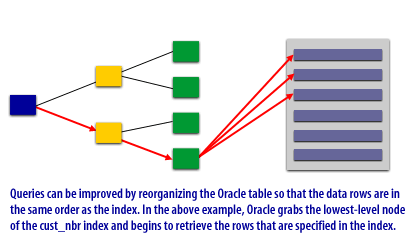
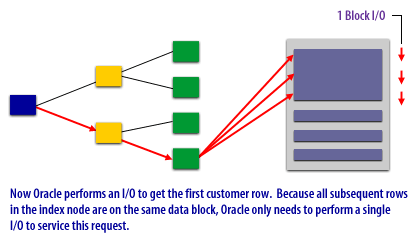
Performance Impact
While this is a simple example, the concept of row re-sequencing can have a dramatic effect on the performance of queries that access the table rows via a common index. There are cases where the response time has gone down by a factor of ten by using this technique.
What is the Clustering Factor in Oracle?
The clustering factor in Oracle is a measure of how well the data in an index is physically ordered on disk with respect to the table. It indicates the degree of data clustering for the indexed column in relation to the table, and can have a significant impact on the performance of the database.
The clustering factor is a number between 0 and the number of table blocks, and is calculated by Oracle during the creation or rebuilding of an index. The lower the clustering factor, the better the data clustering, and the more efficient the index access. If the clustering factor is high, it indicates that the data is not well-ordered, and that index access may be less efficient. A low clustering factor means that the indexed column values for adjacent rows in the table are physically close to each other on disk. This can lead to faster performance when accessing data through the index, since fewer disk reads are required. In contrast, a high clustering factor means that the indexed column values for adjacent rows are widely dispersed on disk, and that accessing data through the index may require more disk reads.
To improve the clustering factor, you can use techniques such as table reorganization, index rebuilding, or partitioning. By improving the data clustering, you can improve the performance of the index and the overall performance of the database.
The clustering factor is a number between 0 and the number of table blocks, and is calculated by Oracle during the creation or rebuilding of an index. The lower the clustering factor, the better the data clustering, and the more efficient the index access. If the clustering factor is high, it indicates that the data is not well-ordered, and that index access may be less efficient. A low clustering factor means that the indexed column values for adjacent rows in the table are physically close to each other on disk. This can lead to faster performance when accessing data through the index, since fewer disk reads are required. In contrast, a high clustering factor means that the indexed column values for adjacent rows are widely dispersed on disk, and that accessing data through the index may require more disk reads.
To improve the clustering factor, you can use techniques such as table reorganization, index rebuilding, or partitioning. By improving the data clustering, you can improve the performance of the index and the overall performance of the database.
Clustering Factor
The relative sequence of the table rows to the index is known in Oracle as the clustering factor. You can see the clustering factor by analyzing the desired index and then viewing the CLUSTERING_FACTOR column of the DBA_INDEXES view. This technique is most useful with:
The next lesson describes how to achieve row re-sequencing.
- Queries that use the same index
- Databases where the majority of table accesses are range scans
- Full-table scan queries that employ the ORDER BY clause For database tables with multiple indexes that are used frequently, this will only help for the index range scans on the key where you have re-sequenced the rows.
The next lesson describes how to achieve row re-sequencing.