| Lesson 2 | Overview of partitioning |
| Objective | Describe partitioned Objects |
Define Oracle Objects and Partitioning
Oracle partitioning allows large tables and indexes to be divided into manageable pieces that share the same logical attributes. Each piece — called a partition — is accessed and manipulated independently and can be managed as a separate database object. This is especially valuable in large-scale data warehouse environments where full-table scans against tables containing hundreds of millions of rows would otherwise be prohibitively expensive.
Partitioning gives the DBA a tool to manage large objects at the partition level rather than the table level. Index creation, data loading, and data purge can all be scoped to a single partition, dramatically reducing maintenance time without affecting the availability of other partitions in the same table. From the perspective of the application, a partitioned table is identical to a non-partitioned table — SQL queries and DML statements require no modification.
Partitions and Data Management
Modern databases routinely manage terabytes of data. Partitioning addresses the operational challenges of very large databases by allowing the DBA to perform the following at the partition level rather than against the entire table:
- Index creation
- Data loading
- Data purge
The result is a dramatically reduced maintenance window. A partition holding two years of historical data can be dropped in a single metadata operation — instantaneous, with no I/O — while the remaining partitions stay fully online and accessible to users and applications.
Oracle MDM: Master Data Management
Master Data Management (MDM) is the process of defining and managing consistent shared data assets across the enterprise. When business computing was called Data Processing, this function was known as Data Administration — the job of cataloging and managing an organization's common data attributes. The formal definition of MDM is identical to the 1980s Data Administrator role:
Master data is the consistent and uniform set of identifiers and extended attributes that describe the core entities of the enterprise.
The predecessor to the MDM specialist was the metadata specialist, common in data warehouse and business intelligence environments where data from disparate operational systems was integrated. This role required intimate knowledge of source system data, whether from legacy relational databases, IMS hierarchical systems, or COBOL flat-file environments.
MDM may be workflow-driven or transactional in nature. Business units and IT departments collaborate to publish and protect common information assets shared across the enterprise. For Oracle databases, MDM enables four key data management functions:
- Data Uniformity: calling shared attributes by common names across all systems. The MDM
administrator collects all synonymous names for shared data elements, often by mining the Oracle data dictionary
and
DBA_SYNONYMS. - Data Synonyms: managing context-sensitive entity names. A person may be a customer to the sales department and an employee to HR. MDM documents the department-specific attributes — customer_status, employee_type — for the same underlying entity.
- Data Keys: managing the different key columns used to identify the same entity across departments. A customer_id in sales and an emp_id in HR may both identify the same person.
- Cross-platform data usage: understanding data structures and relationships across the corporate schema, including null constraints, and devising common data formats for extraction, cleansing, unification, and validation of shared data from legacy systems.
Scale and Data Warehouse Performance
Scale is a defining factor in data warehouse performance. A large FACT table may contain hundreds of millions of rows; a full-table scan against such a table without partitioning could take hours or days to complete. Partitioning limits the blocks Oracle must read to only those partitions that satisfy the query predicate, making warehouse queries tractable at scale.
Since the earliest Decision Support Systems (DSS) of the 1960s, database professionals have recognized that data warehouse processing is fundamentally different from OLTP. Warehouse workloads are I/O intensive — reading trillions of bytes to satisfy aggregation and summarization queries. Most data warehouses are bi-modal: they run batch processes when new data is loaded, indexed, and summarized, then shift to query-intensive read workloads. The server must have on-demand CPU and RAM resources, and the database engine must dynamically reconfigure its resources to accommodate these shifts in processing.
Evolution of the Data Warehouse
The questions data warehouses answer have not changed in four decades — summarization of numbers, aggregation of associated data, data variance analysis. What has changed is the volume at which those questions must be answered and the speed at which answers are expected. Regardless of the sophistication of the database manager, all databases are constructed from simple data structures: linked lists, B-trees, and hashed files.
Oracle partitioning addresses both the volume and speed dimensions. It reduces the data scanned per query through partition pruning, and enables parallel query operations that distribute the remaining workload across multiple CPUs and I/O channels simultaneously. Oracle professionals today must be experts in performance and tuning, data warehousing, OLAP, and the management of objects — partitioning is the feature that makes all of those capabilities scale to enterprise data volumes.
Types of Oracle Partitions
Oracle provides three primary partitioning strategies for tables and indexes:
| Partition Type | Data is partitioned |
| Range | According to a range of values in the partition key column — the most common strategy for date-based or sequence-based data |
| Hash | According to a hash function applied to the partition key, distributing rows evenly across a fixed number of partitions |
| Composite | By range at the primary level, with each range partition further subdivided into sub-partitions using a hash function |
In Oracle 11g and later — including Oracle 23ai — interval partitioning extends range partitioning to automatically create new partitions as data arrives for new range intervals. A monthly interval-partitioned table creates a new partition automatically when the first row for a new month is inserted, eliminating the need to pre-create future partitions.
Advantages of Partitioning
Oracle partitioning improves performance and manageability in five measurable ways:
- Partition pruning: Oracle restricts SQL requests to only the partitions relevant to the query predicate, eliminating unnecessary block reads. A query against a 36-partition monthly table that filters on a single month reads one thirty-sixth of the data.
- Independent maintenance: index and table partitions can be reorganized, rebuilt, and backed up independently without affecting the availability of other partitions in the same table.
- Disk load balancing: table and index partitions can be located on separate tablespaces and physical disks, distributing I/O load across storage resources.
- Parallel query acceleration: the parallel query optimizer detects partition boundaries and creates parallel processes to simultaneously read each partition, reducing elapsed time proportionally to the degree of parallelism.
- Optimizer partition awareness: the SQL optimizer identifies which partitions are required for a query and accesses only those, reducing both logical and physical I/O counts.
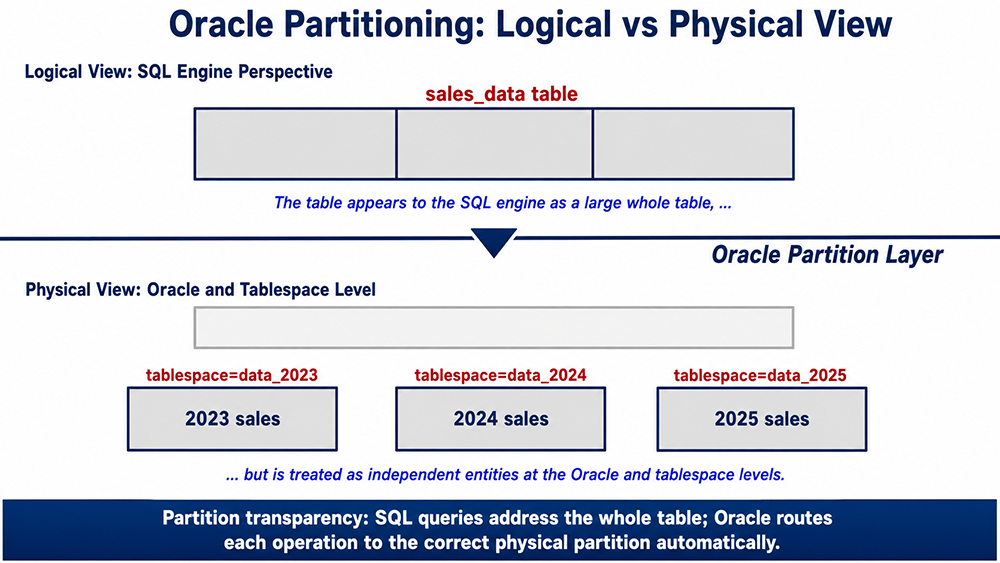
Creating a Partition
The following CREATE TABLE statement defines a sales table partitioned by year range. Each year's data resides in a separate partition, and each partition resides in a separate tablespace — making each year's data an independently manageable unit while remaining a single logical table to SQL queries.
CREATE TABLE sales_data
(
store_nbr NUMBER,
city CHAR(40),
year NUMBER(4),
month NUMBER(2),
units_sold NUMBER,
sales_dollar NUMBER
)
PARTITION BY RANGE (year)
(
PARTITION p2023 VALUES LESS THAN (2024) TABLESPACE data_2023,
PARTITION p2024 VALUES LESS THAN (2025) TABLESPACE data_2024,
PARTITION p2025 VALUES LESS THAN (MAXVALUE) TABLESPACE data_2025
);Define Partitions in Oracle
Partitioning as the Foundation for Information Lifecycle Management
Information Lifecycle Management (ILM) is a set of processes and policies for managing data throughout its useful life. A core ILM decision is determining the most appropriate and cost-effective storage tier for data at each stage:
- Newer data used in day-to-day operations is stored on the fastest, most highly-available storage tier.
- Older data accessed infrequently may be stored on a less expensive, lower-performance storage tier, often compressed and designated read-only.
Oracle partitioning provides the fundamental technology for ILM by allowing data in different partitions to be stored on different storage tiers, compressed independently, and managed with different availability characteristics — all transparent to the application. The most basic ILM operation — archiving and purging older data — is orders of magnitude faster with partitioning, because dropping a partition is an instantaneous metadata operation rather than a DELETE followed by a high-water-mark reset requiring a full table reorganization.
Using a Partition to Improve Query Performance
Partitioning improves query performance by limiting the scope of the scan to only the partitions that contain relevant data. Consider a query selecting all 2023 sales in Raleigh. With Oracle's automatic partition pruning, the standard query is sufficient:
SELECT SUM(units_sold)
FROM sales_data
WHERE year = 2023
AND city = 'Raleigh';The query can also be written with an explicit partition reference when the optimizer's automatic pruning needs to be confirmed or forced:
SELECT SUM(units_sold)
FROM sales_data PARTITION (p2023)
WHERE year = 2023
AND city = 'Raleigh';Both forms limit the query scope to only the blocks that need to be accessed. In a table partitioned across three years, this reduces the data read to one-third of the total table size. The performance benefit scales proportionally with the number of partitions and the selectivity of the partition key predicate.
The next lesson examines how partitions work internally and describes the DBA views Oracle provides for querying partitioned object metadata.
Create Partitioned Table — Exercise
Before you continue, click the exercise link below to test your knowledge of the creation of table and index partitions.
Create Partitioned Table - Exercise