| Lesson 5 | STAR Transformation Queries |
| Objective | Execute STAR Transformation Query |
Execution STAR Transformation Queries
STAR Transformation queries in Oracle 19c and beyond still rely on the cost-based optimizer (CBO) to execute STAR queries more efficiently. Here's a deeper dive into how it works:
STAR Transformation in Action:
Benefits of STAR Transformation:
Conclusion: STAR Transformation remains a valuable tool in Oracle 19c for optimizing STAR queries, leveraging the CBO to choose the most efficient execution plan. However, understanding its limitations and dependencies is crucial for maximizing its benefits in your specific data warehouse environment.
As we demonstrated in the prior lesson, the STAR query indexing technique is very useful in cases where large, fully populated data warehouse tables are joined together. The STAR transformation is a cost-based optimizer operation to execute STAR queries more efficiently. The STAR transformation has certain requirements. Oracle also calls the STAR transformation execution plan the "parallel bitmapped star query transformation". The STAR optimization works well for schemas with dense FACT tables and a small number of DIMENSIONS. The STAR transformation may be considered where these conditions apply:
STAR Transformation in Action:
- When processing a STAR query, the CBO analyzes the query and potential plans for executing it.
- If the query involves joins between a large fact table and smaller dimension tables, and there are selective filters on the dimensions, STAR Transformation kicks in.
- CBO generates two alternative plans:
- Full table scan: Reads the entire fact table, then applies filters.
- STAR Transformation:
- Uses bitmap indexes on fact table join columns (if available).
- Constructs subqueries, called bitmap semijoin predicates, based on dimension filters.
- Uses bitmap AND/OR operations to efficiently identify relevant fact table rows that satisfy the filters.
- Joins only these identified rows with dimension tables.
- CBO compares the estimated cost of each plan and chooses the one with the lower cost.
Benefits of STAR Transformation:
- Reduced Processing: When filters significantly narrow down the relevant data, STAR Transformation can significantly reduce the number of fact table rows processed, leading to faster query execution.
- Efficient Joins: Optimized joins using bitmap indexes improve join performance compared to full scans.
- Data Warehousing Optimization: STAR schema queries are frequently used in data warehousing, making STAR Transformation a valuable tool for efficient data analysis.
- Index Dependence: Requires bitmap indexes on fact table join columns for effective operation.
- Filter Impact: The effectiveness depends on the selectivity of dimension filters. Less selective filters may not trigger the transformation or provide minimal benefit.
- CBO Cost Estimation: Relies on accurate CBO cost estimations to choose the optimal plan. Poor estimations can lead to suboptimal performance.
Conclusion: STAR Transformation remains a valuable tool in Oracle 19c for optimizing STAR queries, leveraging the CBO to choose the most efficient execution plan. However, understanding its limitations and dependencies is crucial for maximizing its benefits in your specific data warehouse environment.
As we demonstrated in the prior lesson, the STAR query indexing technique is very useful in cases where large, fully populated data warehouse tables are joined together. The STAR transformation is a cost-based optimizer operation to execute STAR queries more efficiently. The STAR transformation has certain requirements. Oracle also calls the STAR transformation execution plan the "parallel bitmapped star query transformation". The STAR optimization works well for schemas with dense FACT tables and a small number of DIMENSIONS. The STAR transformation may be considered where these conditions apply:
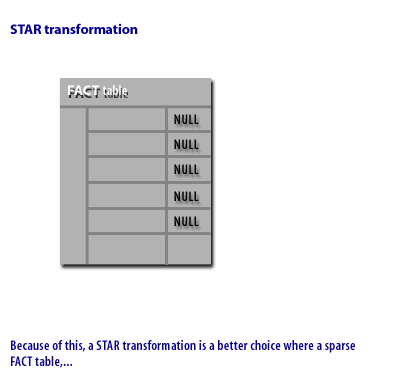
- The FACT table is sparse because many of the data columns are NULL.
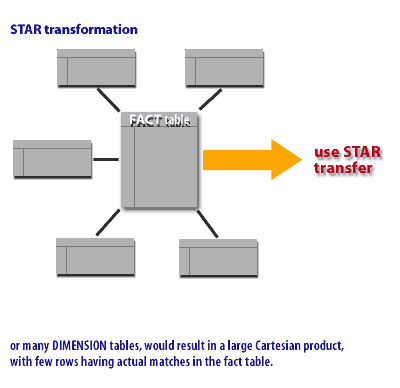
- There are many DIMENSION tables.
- There are queries where some DIMENSION tables have no constraining predicates.
- There are a large number of DIMENSION tables involved in the JOIN.
Requirements for STAR Transformation
For the STAR transformation execution plan, Oracle documentation lists the following restrictions and requirements:
Restrictions and Requirements
If all of these conditions apply, the star_transformation hint can be used to invoke this access method.
Restrictions and Requirements
| Restrictions | Requirements |
|---|---|
| Cannot have a CONNECT BY and START WITH | Must set the value of the initialization parameter star_transformation_enabled to true in the init.ora file |
| Cannot have a BIND VARIABLE in SELECT statement | Must be bitmap index defined on FACT table columns involved in EQUIJOIN predicate; more than two bitmap index on FACT table |
| Cannot include a remote FACT table | Must have more than 15,000 rows in the FACT table |
| Cannot include a FACT table which is also a view | |
| Cannot have a hint FULL on FACT table | |
| Cannot have a hint STAR; forcing a STAR query excludes a STAR transformation |
If all of these conditions apply, the star_transformation hint can be used to invoke this access method.
Using the Star Transformation
The star transformation is a powerful optimization technique that relies upon implicitly rewriting (or transforming) the SQL of the original star query. The end user never needs to know any of the details about the star transformation. Oracle Database's query optimizer automatically chooses the star transformation where appropriate. The star transformation is a query transformation aimed at executing star queries efficiently. Oracle Database processes a star query using two basic phases. The first phase retrieves exactly the necessary rows from the fact table (the result set). Because this retrieval utilizes bitmap indexes, it is very efficient. The second phase joins this result set to the dimension tables. An example of an end user query is: "What were the sales and profits for the grocery department of stores in the west and southwest sales districts over the last three quarters?" This is a simple star query.
Star Transformation with Bitmap Index
A prerequisite of the star transformation is that there be a single-column bitmap index on every join column of the fact table. These join columns include all foreign key columns. For example, the sales table of the sh sample schema has bitmap indexes on the time_id, channel_id, cust_id, prod_id, and promo_id columns. Consider the following star query:
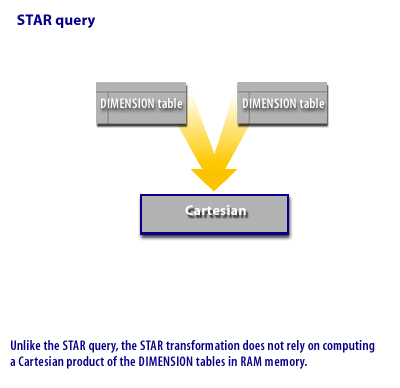
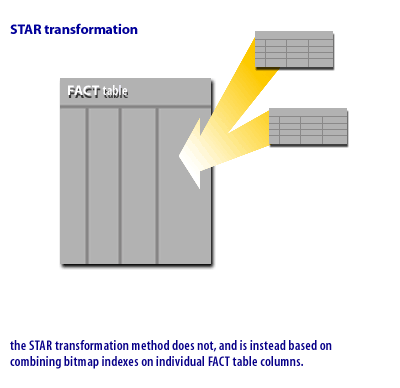
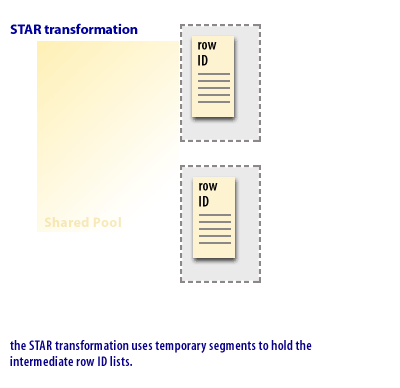
The STAR transformation is like the STAR query, except that rather than relying on a join index, it uses bitmapped indexes and builds the intermediate results in temporary segments. The following series of images demonstrates some of the differences between a 1) STAR query and a 2) STAR transformation query.
SELECT ch.channel_class, c.cust_city, t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc in ('Internet','Catalog')
AND t.calendar_quarter_desc IN ('1999-Q1','1999-Q2')
GROUP BY ch.channel_class, c.cust_city, t.calendar_quarter_desc;
The STAR transformation is like the STAR query, except that rather than relying on a join index, it uses bitmapped indexes and builds the intermediate results in temporary segments. The following series of images demonstrates some of the differences between a 1) STAR query and a 2) STAR transformation query.

Question: What is the difference between a "STAR query" and "STAR transformation query" in Oracle?
A "star query" and a "star transformation query" are both terms used within the context of Oracle databases, specifically when working with star schemas in a data warehousing environment. These terms refer to different aspects of query execution within Oracle.
In a star transformation, Oracle creates a temporary bitmap for each dimension table based on the predicates in the WHERE clause of the query. It then merges these bitmaps using a bitmap AND operation to identify the rows in the fact table that satisfy all the conditions. Finally, it retrieves the needed data from the fact table based on this bitmap, and performs any remaining operations, such as grouping or aggregation.
In summary, a star query is a type of query used in star schemas, while a star transformation refers to an optimization technique that Oracle uses to efficiently execute star queries. By understanding both concepts, one can leverage the power of Oracle's query optimizer to improve the performance of data retrieval operations in a data warehousing environment.
Utilize the Star Schema to leverage Star Query Transformation
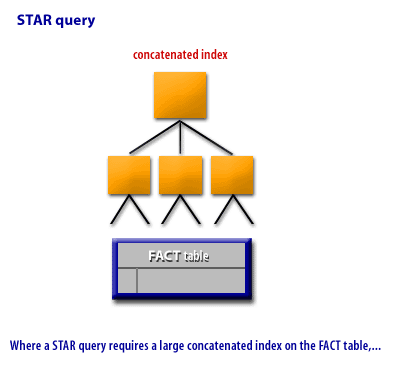
As we saw in the series of images above, unlike the STAR query, the STAR transformation does not rely on computing a Cartesian product of the DIMENSION tables in RAM memory. In a STAR transformation, a join index provides immediate access to only the relevant rows of the FACT table, whereas a STAR query requires a large concatenated index on the FACT table. More efficient FACT table access makes a STAR transformation a better choice in the case where few rows have actual matches in the fact table. In a STAR transformation, the SQL optimizer will see if there are bitmapped indexes on the FACT and DIMENSION tables and dynamically re-format the SQL query.
A "star query" and a "star transformation query" are both terms used within the context of Oracle databases, specifically when working with star schemas in a data warehousing environment. These terms refer to different aspects of query execution within Oracle.
- Star Query: A star query is a specific type of query that retrieves data from a star schema. It typically involves a join between a large fact table at the center of the star and several smaller dimension tables. Star queries are commonly used in data warehousing and business intelligence applications for complex, ad-hoc analytical queries.
- Star Transformation Query: Star transformation is a process or an optimization method applied by the Oracle query optimizer to execute a star query more efficiently. This technique transforms the original star query into a set of simpler queries that can be executed independently, and their results are then combined. This transformation allows the database to leverage bitmap indexes on the fact table's foreign key columns, significantly speeding up query execution.
In a star transformation, Oracle creates a temporary bitmap for each dimension table based on the predicates in the WHERE clause of the query. It then merges these bitmaps using a bitmap AND operation to identify the rows in the fact table that satisfy all the conditions. Finally, it retrieves the needed data from the fact table based on this bitmap, and performs any remaining operations, such as grouping or aggregation.
In summary, a star query is a type of query used in star schemas, while a star transformation refers to an optimization technique that Oracle uses to efficiently execute star queries. By understanding both concepts, one can leverage the power of Oracle's query optimizer to improve the performance of data retrieval operations in a data warehousing environment.
Utilize the Star Schema to leverage Star Query Transformation
- Oracle optimizer prunes a query's results set with its conversion of many logical joins into a single operation with Bitmap Indexes
- Bitmap Indexes are up to 100 times smaller in size and hence up to 100 times faster
- Bitmaps are not just for low cardinality
- Central table in a star schema is called a FACT table
- A fact table typically has two types of columns: 1) those that contain facts and 2) those that are foreign keys to dimension tables
- In a star schema every dimension will have a primary key
- In a star schema, a dimension table will not have any parent table
- Whereas in a snow flake schema, a dimension table will have one or more parent tables
As we saw in the series of images above, unlike the STAR query, the STAR transformation does not rely on computing a Cartesian product of the DIMENSION tables in RAM memory. In a STAR transformation, a join index provides immediate access to only the relevant rows of the FACT table, whereas a STAR query requires a large concatenated index on the FACT table. More efficient FACT table access makes a STAR transformation a better choice in the case where few rows have actual matches in the fact table. In a STAR transformation, the SQL optimizer will see if there are bitmapped indexes on the FACT and DIMENSION tables and dynamically re-format the SQL query.