| Lesson 4 | STAR Index Queries |
| Objective | Describe STAR Query Operation |
Describe STAR Index Query Operation
In data warehousing, a star schema is a table design pattern where a large central fact table is surrounded by smaller dimension tables. The overall shape resembles a star: the fact table is the center and the dimensions are the “points.”
The goal of this lesson is to explain the STAR query operation: how a SQL query that filters on multiple dimensions can be executed efficiently against a very large fact table, especially when Oracle can take advantage of specialized access paths (for example, bitmap indexes and star transformations).
The term “star schema” is strongly associated with dimensional modeling popularized by Ralph Kimball. The concept is not unique to Oracle; most modern database engines can query star schemas effectively. What differs is how the optimizer chooses an execution plan and which index types and transformations are available.
The goal of this lesson is to explain the STAR query operation: how a SQL query that filters on multiple dimensions can be executed efficiently against a very large fact table, especially when Oracle can take advantage of specialized access paths (for example, bitmap indexes and star transformations).
The term “star schema” is strongly associated with dimensional modeling popularized by Ralph Kimball. The concept is not unique to Oracle; most modern database engines can query star schemas effectively. What differs is how the optimizer chooses an execution plan and which index types and transformations are available.
Star Schema: Fact Tables and Dimension Tables
Fact table rows represent business events or measurements (sales, clicks, shipments, claims, etc.). Fact tables are typically very large and contain:
Dimension tables contain descriptive attributes used for filtering, grouping, and reporting (for example, time, geography, product category, customer segment). Dimensions are often denormalized and can have many attributes, because their purpose is to support flexible slicing and dicing of facts.
- Foreign keys that point to dimension tables (for example,
id_date,id_product,id_customer). - Measures (numeric values) such as revenue, quantity, or cost.
Dimension tables contain descriptive attributes used for filtering, grouping, and reporting (for example, time, geography, product category, customer segment). Dimensions are often denormalized and can have many attributes, because their purpose is to support flexible slicing and dicing of facts.
Example Star Schema
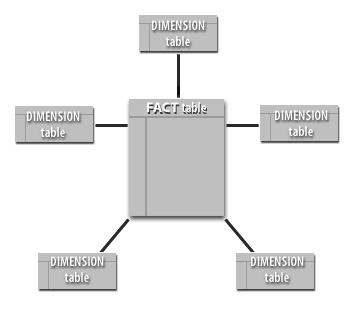
The star schema is one of the simplest data warehouse schemas. In a typical implementation:
- Dimension tables are smaller, but wide (many descriptive columns).
- The fact table is large and narrower (mostly keys plus measures).
- Queries filter on dimension attributes and aggregate measures from the fact table.
About Bitmap Indexes on Partitioned Tables
In Oracle, bitmap indexes are commonly used in data warehouse workloads because they can be very efficient for low-to-medium cardinality columns and for combining multiple predicates using bitmap operations.
Partitioning note: Bitmap indexes on partitioned tables are typically created as local indexes (aligned with the table partitions). Global bitmap indexes are generally avoided because they can become expensive to maintain and are not a good fit for many partition maintenance operations.
Bitmap indexes are primarily intended for analytic workloads where queries dominate and updates are relatively infrequent. They are usually not a good fit for high-concurrency OLTP systems with frequent row-level updates.
Partitioning note: Bitmap indexes on partitioned tables are typically created as local indexes (aligned with the table partitions). Global bitmap indexes are generally avoided because they can become expensive to maintain and are not a good fit for many partition maintenance operations.
Bitmap indexes are primarily intended for analytic workloads where queries dominate and updates are relatively infrequent. They are usually not a good fit for high-concurrency OLTP systems with frequent row-level updates.
The STAR Query
A STAR query is a query that joins a large fact table to multiple dimension tables, typically filtering by dimension attributes and aggregating measures from the fact table.
In early data warehouse implementations, optimizers could choose inefficient plans that repeatedly scanned or re-joined large portions of the fact table. Oracle’s star-related optimizations were designed to reduce unnecessary I/O and to use indexes to find qualifying fact rows more directly.
When Oracle recognizes a star query pattern, it may use a star transformation (or related star join access paths) to drive down physical I/O against the fact table.
In early data warehouse implementations, optimizers could choose inefficient plans that repeatedly scanned or re-joined large portions of the fact table. Oracle’s star-related optimizations were designed to reduce unnecessary I/O and to use indexes to find qualifying fact rows more directly.
When Oracle recognizes a star query pattern, it may use a star transformation (or related star join access paths) to drive down physical I/O against the fact table.
STAR Query Process (Conceptual Walkthrough)
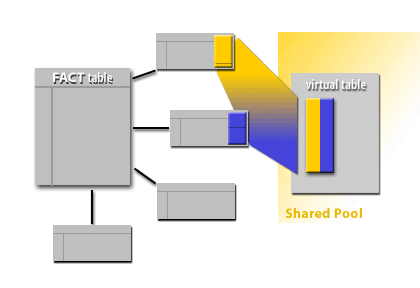
id_d1, id_d2, id_d3 values).
Conceptually, Oracle forms combinations of qualifying dimension keys and uses them to drive access into the fact table. In practice, this is not typically a literal “cartesian product table stored in the shared pool,” but an optimizer strategy that uses intermediate key sets and bitmap operations to minimize fact-table I/O.
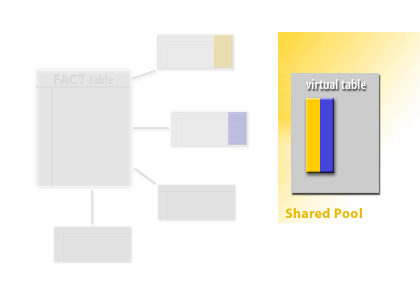
(id_d1, id_d2, id_d3, ...)).
Oracle uses these key combinations to locate fact rows efficiently, often via bitmap indexes (or bitmap join indexes) on the fact table’s dimension-key columns.
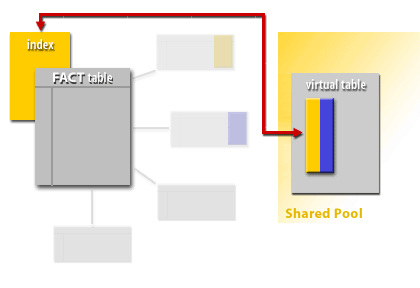
Some schemas also use concatenated (composite) indexes, but in Oracle star-optimized warehousing the most common acceleration is from bitmap-based access paths rather than relying solely on a single large concatenated B-tree index.
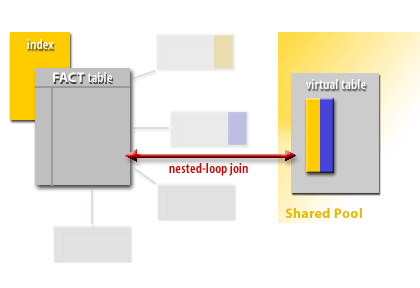
The join method may involve nested loops in some plans, but star transformation plans commonly show bitmap operations (bitmap index scans and bitmap merge/and/or) followed by fact-table row access. The important concept is that the fact table is accessed after dimension filtering has sharply reduced the candidate row set.
Star Query Rules You Should Remember
A star query typically has these characteristics:
- The query joins one large fact table to multiple dimension tables.
- Each dimension joins to the fact table using a PK-to-FK relationship.
- Dimension tables are not joined to each other.
- Predicates are usually applied to dimension attributes (for example, region, product category, time period), and measures are aggregated from the fact table.
Conditions That Help Oracle Choose a Star-Optimized Plan
In Oracle, star-optimized plans are most likely when:
The speedup comes primarily from reducing physical I/O against the fact table by using indexed key filtering.
- You have at least three tables in the join: one large fact table and multiple smaller dimensions.
- The fact table has suitable indexes on the foreign key columns used to join to dimensions (often bitmap indexes, and sometimes bitmap join indexes).
- Statistics are accurate and the cost-based optimizer can estimate selectivity well (dimension predicates should significantly reduce the candidate fact rows).
- The execution plan confirms that Oracle is using a star-friendly access path (for example, bitmap operations + rowid access) rather than a full scan of the fact table.
The speedup comes primarily from reducing physical I/O against the fact table by using indexed key filtering.
Example Plan Shape (Conceptual)
The following plan snippet is representative of the idea: Oracle evaluates dimension access paths first, combines qualifying keys, and then accesses the fact table by rowid using an index-driven approach.
The exact operators will vary by Oracle version, indexing strategy, and schema design, but the objective is the same: filter early on dimensions, access late on the fact.
NESTED LOOPS
(STAR-STYLE DIMENSION FILTERING)
...
TABLE ACCESS BY ROWID FACT_TABLE
INDEX RANGE SCAN (or BITMAP operations) on FACT_TABLE keysThe exact operators will vary by Oracle version, indexing strategy, and schema design, but the objective is the same: filter early on dimensions, access late on the fact.
In summary, the STAR query operation describes an optimizer strategy for efficiently joining a large fact table to multiple dimension tables. By leveraging dimension selectivity and star-friendly indexes, Oracle can avoid expensive repeated passes over the fact table and return analytic results quickly.
The next lesson describes the STAR transformation in more detail.
The next lesson describes the STAR transformation in more detail.