| Lesson 2 | Reviewing the optimizer |
| Objective | Describe the Oracle Optimizer Functions |
Describe the Oracle Optimizer Functions
The query optimizer is the key to one of the great advantages of all relational databases.
Before we jump into the features of the Oracle optimizer, we should review the important reasons why a query optimizer is necessary, as well as the basics of Oracle's own query optimizer.
- Purpose of Optimization
One of the foundations of a relational database is that users will not have to specify an access path to retrieve data.
Question: What if there are multiple ways to access the data needed to satisfy a particular query?
Virtually all relational databases include some form of query optimizer. As the name implies, the query optimizer is a piece of software that chooses the optimal path to access the data needed for a query. Choosing the right query access path can dramatically affect the performance of a query. For instance, if the data requested in a query can be selected and retrieved by using an index, it is usually much faster to use the index to access the data than to go directly to the database row. But what if multiple indexes could be used? Are there times when using an index will not be the fastest way to access the data? The job of the query optimizer is to provide the best path for any query.
Oracle Query Optimizer
Oracle has had a query optimizer for a long time. In the early days, Oracle offered a rule-based optimizer. As the name implies, this optimizer was based on a fixed set of rules. These rules tried to use the syntax of the Structured Query Language (SQL) query to determine the optimal access path, referred to as an execution plan [1].
For instance, if a query contained a reference to an index, the query optimizer would usually use that index to create the execution plan. There were two disadvantages of the rule-based optimizer:
- It had somewhat limited complexity, because there were not many rules.
- The rules, by themselves, did not always lead to the right decision.
Cost-based Optimizer
To correct these deficiencies, Oracle7 introduced a cost-based optimizer.
As the name implies, the cost-based optimizer includes calculations that estimate the cost of using a particular access path in the execution plan, which in turn results in a more accurate plan. Oracle has endorsed the cost-based optimizer, which means that new features, such as partitioning, are no longer considered by the rule-based optimizer.
By default, Oracle uses the cost-based optimizer. The
The link below contains some answers with regards to why calculate the cost.
OPTIMZER_MODE setting tells Oracle which type of optimizer to use from among the following:
RULEfor the rule-based optimizerCOSTfor the cost-based optimizerCHOOSEso that Oracle can choose which optimizer to use, based on the presence or absence of statistical information or stored outlines, both of which are described later in this course
Why calculate Cost?
The entire basis of a cost-based optimizer is the simple fact that different access paths can require dramatically different (I/O) input/output costs.
The nomenclature BIGTABLE and LITTLETABLE is specific to this example. To understand this better, assume that you have a simple query that joins two tables together
If you access
BIGTABLEwith 1,000 rows andLITTLETABLEwith 10 rows.
BIGTABLE that can be joined to each row in LITTLETABLE. If you access BIGTABLE first, the retrieval will first read a row in BIGTABLE and then read the associated row in LITTLETABLE. To clarify, that is one access for the BIGTABLE row and one access to retrieve the value of the join column in BIGTABLE with the value of the same column in LITTLE TABLE. Oracle will perform this action 1,000 times, resulting in 2,000 accesses overall.
If you access
LITTLETABLE first, the retrieval will read a row from LITTLETABLE and then the associated row in BIGTABLE, for a total of 20 accesses overall, or 100 times fewer rows than starting the query with BIGTABLE.
Although the caching mechanism in Oracle will help diminish the effect of this dramatic difference,
it is easy to see that the cost of starting the query access with BIGTABLE is much greater than the cost of using LITTLETABLE first.
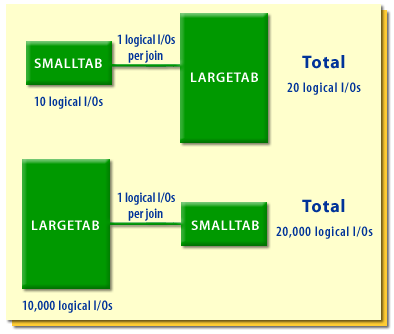
The diagram above illustrates logical I/O (LIO) costs when joining tables of different sizes in an Oracle database.
It highlights the impact of table size on logical I/O costs during a join operation.
Key Observations:
-
First Scenario: SMALLTAB → LARGETAB
-
SMALLTAB (Small Table)
- 10 logical I/Os (LIOs).
-
LARGETAB (Large Table)
- Each row in SMALLTAB requires 1 logical I/O per join.
- Total Logical I/Os = 10 (SMALLTAB) + 10 (JOIN with LARGETAB) = 20.
-
SMALLTAB (Small Table)
-
Second Scenario: LARGETAB → SMALLTAB
-
LARGETAB (Large Table)
- 10,000 logical I/Os.
-
SMALLTAB (Small Table)
- Each row in LARGETAB requires 1 logical I/O per join.
- Total Logical I/Os = 10,000 (LARGETAB) + 10,000 (JOIN with SMALLTAB) = 20,000.
-
LARGETAB (Large Table)
Performance Implications:
- Joins involving large tables require significantly more logical I/Os.
-
The order of table access matters:
- When joining a small table first, the total logical I/O cost is low.
- When joining a large table first, the cost is significantly higher.
- Indexing can help reduce logical I/O costs.
- Query optimization (e.g., choosing the right join order, using hash joins or nested loops properly) can significantly impact performance.
Conclusion
- Joining a small table with a large table is much more efficient than the reverse.
- Logical I/O cost grows significantly when the large table is accessed first.
- Optimizing execution plans by using indexes, reducing unnecessary joins, or restructuring queries can lead to performance improvements.
To a rule-based optimizer, an index is an index is an index. The Oracle rule-based optimizer will choose an index based on a somewhat arbitrary rule, such as which index is mentioned first. The inflexible nature of rule-based optimization means that the way a query is written could result in significantly different performance characteristics. Or, even worse, that the same query could deliver significantly different performance characteristics as the actual composition of the database changes.
When you upgrade to Oracle Database 11g, optimizer statistics are collected for dictionary tables that lack statistics.
This statistics collection can be time-consuming for databases with a large number of dictionary tables, but statistics gathering only occurs for those tables that lack statistics or are significantly changed during the upgrade. To decrease the amount of downtime incurred when collecting statistics, you can collect statistics prior to performing the actual database upgrade. As of Oracle Database 10g, Oracle recommends that you use the DBMS_STATS.GATHER_DICTIONARY_STATS procedure to gather these statistics.
In the next lesson, you will learn about the specific enhancements to Oracle8's query optimizer.
In the next lesson, you will learn about the specific enhancements to Oracle8's query optimizer.
[1] Execution Plan: A description of the steps the Oracle database will take to retrieve and select the data requested by a query.