| Lesson 2 | What is an index-organized table? |
| Objective | Describe an index-organized table and explain when to use it. |
What is index-organized table?
There is nothing extraordinary about an index-organized table, namely the object is exactly what its name implies, it is a table structure organized like a B*-tree index.
Theory and Structure of an index-organized table
Question: Is an "index-organized table" a table structure organized like a B*-tree index?
Yes, an index-organized table (IOT) is a specialized type of table structure in a relational database management system (RDBMS) that is organized in a manner similar to a B*-tree index. This structure is primarily utilized for performance enhancements in certain types of database operations, especially those involving large amounts of data.
In a traditional table structure, the table's data is stored separately from the index data, which essentially functions as a map to locate the data within the table. In contrast, an index-organized table merges the index and the table's data into one structure. This is achieved by using the table's primary key as the search key for the B*-tree structure.
Index-organized tables have several key characteristics:
Index-organized tables can offer significant performance benefits for certain types of queries, especially those that perform range scans or full scans on large tables. However, they are not universally beneficial and should be used judiciously. Overuse of IOTs, especially on tables where they are not needed, can result in unnecessary storage overhead and potential performance degradation.
To sum up, an index-organized table is a type of table in an RDBMS that organizes data like a B*-tree index. It combines the data and the index into a single structure, providing potential benefits in data retrieval speed for certain types of database operations. However, it also brings specific constraints and considerations that must be taken into account when designing a database schema.
Yes, an index-organized table (IOT) is a specialized type of table structure in a relational database management system (RDBMS) that is organized in a manner similar to a B*-tree index. This structure is primarily utilized for performance enhancements in certain types of database operations, especially those involving large amounts of data.
In a traditional table structure, the table's data is stored separately from the index data, which essentially functions as a map to locate the data within the table. In contrast, an index-organized table merges the index and the table's data into one structure. This is achieved by using the table's primary key as the search key for the B*-tree structure.
Index-organized tables have several key characteristics:
- Primary Key Requirement: Every IOT must have a primary key, as this key provides the sorting mechanism for the B*-tree structure. The primary key becomes an integral part of the IOT's index.
- Physical Storage: The physical storage of an IOT is like a B*-tree index, where the leaf nodes contain the actual data rows (not just indexed values). This significantly reduces I/O operations for certain queries.
- Ordering: The rows in an IOT are stored in the order of the primary key. This is in contrast to a traditional heap-organized table, where the order of rows is not guaranteed.
- Overflow Segments: For IOTs with non-key columns (columns not part of the primary key), Oracle provides an optional feature called an overflow segment. When a row in an IOT has non-key columns that cause it to exceed a specified size, the row's non-key column values are stored in the overflow segment, allowing for more efficient use of the B*-tree index space.
Index-organized tables can offer significant performance benefits for certain types of queries, especially those that perform range scans or full scans on large tables. However, they are not universally beneficial and should be used judiciously. Overuse of IOTs, especially on tables where they are not needed, can result in unnecessary storage overhead and potential performance degradation.
To sum up, an index-organized table is a type of table in an RDBMS that organizes data like a B*-tree index. It combines the data and the index into a single structure, providing potential benefits in data retrieval speed for certain types of database operations. However, it also brings specific constraints and considerations that must be taken into account when designing a database schema.
Advantages of index-organized Table
As with all index structures, the advantages of an index-organized table relate to performance.
All the data in an index-organized table is stored in an index structure. Therefore, there is no need to use the index structure to first locate a value and then use the ROWID of the associated row in the table to fetch the data from the row as is normally done with regular tables and their indexes. This means that the I/O operations required to retrieve data are significantly reduced. In addition to reducing I/O for retrieval, index-organized tables also eliminate the need to store the ROWID in the leaf nodes of the index-structure. An index-organized table will require less space than an identical index on a standard table because of the lack of ROWIDs, which in turn leads to improved performance.
All the data in an index-organized table is stored in an index structure. Therefore, there is no need to use the index structure to first locate a value and then use the ROWID of the associated row in the table to fetch the data from the row as is normally done with regular tables and their indexes. This means that the I/O operations required to retrieve data are significantly reduced. In addition to reducing I/O for retrieval, index-organized tables also eliminate the need to store the ROWID in the leaf nodes of the index-structure. An index-organized table will require less space than an identical index on a standard table because of the lack of ROWIDs, which in turn leads to improved performance.
Limitations of an index-organized Table
One limitation of index-organized tables is that they can not be used all the time. Typically, an index contains a subset of the total data in a table. The reason for this stems from the way a B*-tree index is built. A B*-tree index depends, in part, on a small amount of data in the actual index, which in turn reduces the size of the leaf nodes and makes access efficient.
Oracle 12c Performance Tuning
When to use index-organized tables
The ideal time to use an index-organized table is when a relatively small amount of data is being accessed by an index entry. Typical applications that fit this profile include:
- Information retrieval: Where an index simply contains a pointer to an occurrence of a piece of information. Information retrieval applications are typically used to search for words and phrases in documents.
- Spatial data: Where the index contains a locating value, similar to the pointer in an information retrieval application. Spatial data is used in geographic systems.
- Online Analytical Processing (OLAP): These applications frequently have a fact table that contains a single numeric value. A data warehouse is a classic OLAP application.
Understanding the Structure
From a user or developer perspective, an index-organized table (IOT) appears like a normal table. IOTs are stored in a B-tree structure abdhere must be a primary key on an index-organized table, as the data is
stored in primary key order. Since there is no data segment, there is no physical ROWID values for indexorganized tables. See Figure 5 below for an example of an IOT.
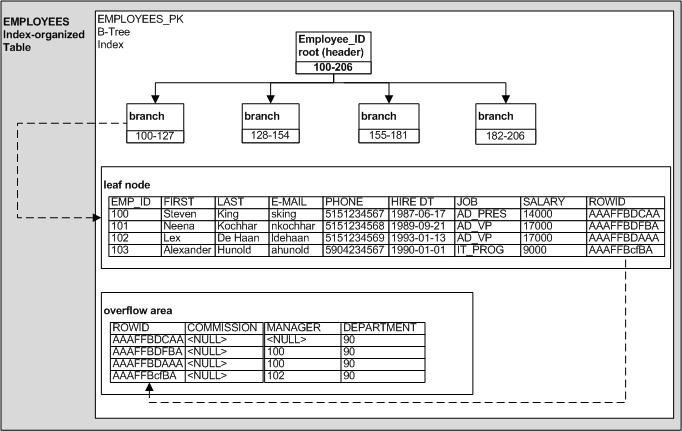
IOTs support many of the same features found in heap-organized tables, such as
- Constraints: A constraint is a database rule that you define within the database to enforce certain conditions regarding the data that is stored in the database tables
- Global hash-partitioned indexes: A global hash-partitioned index is an index that is partitioned across multiple partitions, but the index itself is not a child of any of the partitions. This means that the index can be used to access data from any of the partitions, regardless of which partition the data is actually stored in.
CREATE INDEX emp_idx ON employees (emp_id) PARTITION BY HASH (emp_id) PARTITIONS 4;
- Indexes (e.g. secondary indexes on IOTs):
A secondary index on an index-organized table is an index on a column or columns of the table that is not the primary key. Secondary indexes can be used to improve the performance of queries that access the table on columns other than the primary key.
CREATE INDEX dept_name_idx ON departments (dept_name);
- LOB columns:
A LOB column in Oracle is a column that can store large objects, such as images, audio, and video files. LOB columns are of four types:
- BLOB (Binary Large Object): Stores binary data, such as images and audio files.
- CLOB (Character Large Object): Stores character data, such as text files.
- NCLOB (National Character Large Object): Stores character data that can contain characters from multiple languages.
- BFILE (Binary File): Stores a reference to a file on the file system.
- Online reorganization
- Partitioning
- Parallelism
- Triggers