| Lesson 5 | Reverse indexing |
| Objective | Create a reverse index in Oracle |
Create Reverse Key Index in Oracle
A reverse key index (often called a “reverse index”) is a specialized form of Oracle B-tree index that helps in a very specific scenario:
high-concurrency inserts into a sequentially increasing key, such as a primary key populated from a sequence.
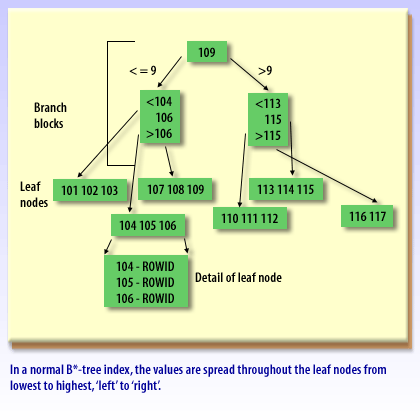
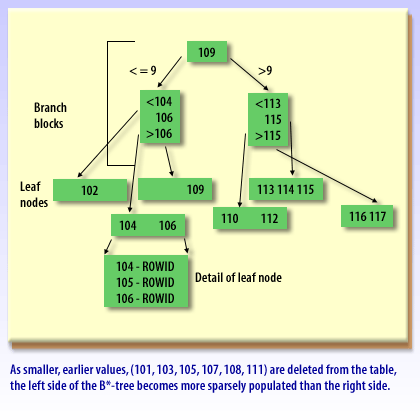
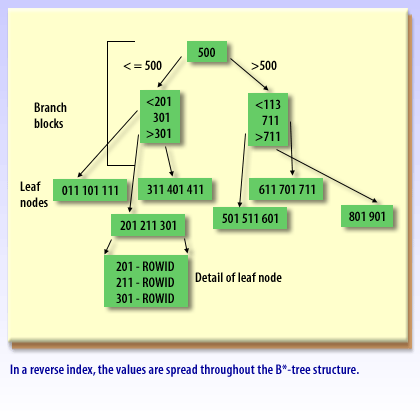
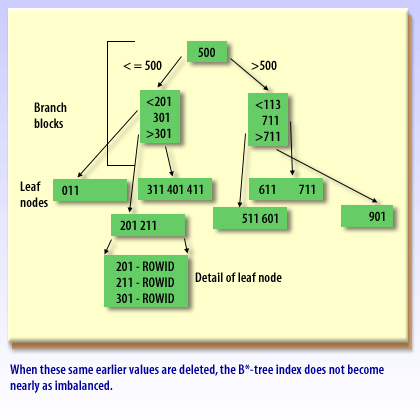
In a standard B-tree, new, higher key values tend to land on the “right edge” of the index. Under heavy insert load—especially in Oracle RAC—many sessions can contend for the same rightmost leaf blocks, producing a hot spot that slows inserts. A reverse key index mitigates this by reversing the bytes of the indexed key before storing it, which spreads inserts across many leaf blocks instead of concentrating them at the right edge.
Oracle handles the reversal transparently: your SQL still uses the original key value. The reversal is only an internal storage and access mechanism.
Problem and Solution delivered by Reverse Key Indexes
In a standard B-tree, new, higher key values tend to land on the “right edge” of the index. Under heavy insert load—especially in Oracle RAC—many sessions can contend for the same rightmost leaf blocks, producing a hot spot that slows inserts. A reverse key index mitigates this by reversing the bytes of the indexed key before storing it, which spreads inserts across many leaf blocks instead of concentrating them at the right edge.
Oracle handles the reversal transparently: your SQL still uses the original key value. The reversal is only an internal storage and access mechanism.
When to Use a Reverse Key Index
Reverse key indexes are not a general-purpose tuning feature. Consider them when:
- Your indexed key is sequentially increasing (sequence-based numeric keys are the classic case).
- You have high insert concurrency and evidence of index hot-block contention (particularly in RAC).
- Your access pattern is primarily equality lookups on the indexed column(s).
Oracle Index Types Summary
Oracle supports many index types and features. Several “types” are actually variations on the B-tree theme.
The table below highlights a small subset relevant to this lesson:
| Index Type | Usage |
|---|---|
| B-tree | Default balanced tree index; best for high-cardinality columns, equality predicates, and selective range predicates. |
| Index-organized table | Table data is stored in a B-tree structure organized by the primary key; efficient when most access is by primary key. |
| Unique | Enforces uniqueness; commonly created implicitly by PRIMARY KEY or UNIQUE constraints, but can be created explicitly. |
| Reverse key | B-tree variant; spreads inserts for sequential keys to reduce right-edge contention. Best for equality lookups, not ranges. |
Syntax to Create a Reverse Key Index
The syntax is the standard
CREATE INDEX statement with the addition of the REVERSE keyword.
The REVERSE keyword applies to the entire index (not to individual columns).
CREATE INDEX index_name
ON table_name (column_list)
REVERSE;
Example:
CREATE INDEX cust_rev_idx
ON cust (cust_id)
REVERSE;| CREATE INDEX | Required keywords. |
| index_name | Unique name for the index. |
| ON | Required keyword. |
| table_name | Name of the table the index will be based on. |
| column_list | List of indexed columns whose combined key will be stored as a reversed byte sequence. |
| REVERSE | Creates the index as a reverse key index to spread insert activity for sequential keys. |
How to Confirm an Index Is Reverse Key
You can confirm whether an index is reverse key by checking the
REVERSE attribute in the data dictionary:
SELECT index_name, reverse
FROM user_indexes
WHERE index_name = 'CUST_REV_IDX';Disadvantages of Reverse Key Index
The primary trade-off is that a reverse key index generally cannot support efficient range scans.
Because stored keys are reversed, adjacent logical key values are not stored adjacent in the index. As a result:
If your root problem is “hot index blocks,” other strategies may be viable, including partitioning approaches that distribute activity across multiple logical index structures rather than reversing keys.
In the next lesson, you will learn about computing statistics for indexes.
- Good fit: equality predicates such as
WHERE cust_id = :b1(unique scans or equality-based range scans). - Poor fit: range predicates such as
WHERE cust_id BETWEEN :a AND :bor queries that rely on index order for sorting.
If your root problem is “hot index blocks,” other strategies may be viable, including partitioning approaches that distribute activity across multiple logical index structures rather than reversing keys.
In the next lesson, you will learn about computing statistics for indexes.
[1]fast full scan: Reads the index using multiblock I/O (similar to a full scan) and can be efficient when the index contains all columns needed by the query, but it does not preserve key order like an ordered index range scan.