List the disadvantages of the rule-based optimizer.
Disadvantages of rule-based SQL optimization
As we discussed, there are cases where the rule-based optimizer fails. This is most common in cases where a table has many indexes and the rule-based optimizer fails to choose the best index to service a query. This generally happens because the rule-based optimizer is not aware of the number of distinct values in an index and the distribution of values within the index. Let us illustrate this point with an example shown in the following series of images
optimization-fail-example
🔍 Image Analysis: EMPLOYEE Table Visualization
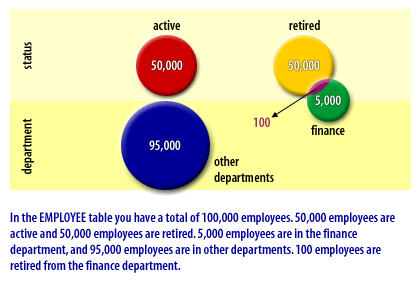
This diagram is a Venn-style data distribution illustration showing how employee records are segmented in an `EMPLOYEE` table based on status (`active`, `retired`) and department (`finance`, `other departments`).
🧩 Image Components: 1. Axes/Dimensions:
Vertical axis (Y-axis): status
active (top)
retired (bottom)
Horizontal axis (X-axis): department
finance (right)
other departments (left)
📊 Colored Circles Representing Subsets:
Circle
Label / Color
Quantity
Description
🔴 Red
active
50,000
All active employees
🟡 Yellow
retired
50,000
All retired employees
🔵 Blue
other departments
95,000
Employees in non-finance departments
🟢 Green
finance
5,000
Employees in the finance department
🟣 Overlap
retired ∩ finance
100
Retired employees who were in finance
📋 Transcribed Text Below Image:
> In the EMPLOYEE table you have a total of 100,000 employees.
>
> * 50,000 employees are active
> * 50,000 employees are retired
> * 5,000 employees are in the finance department
> * 95,000 employees are in other departments
> * 100 employees are retired from the finance department
💡 Data Insights:
This visual sets up a classic example where naive join order or filter placement can severely affect query performance:
Only 100 out of 100,000 rows match all filtering criteria (retired and finance).
If a query does not apply the most selective condition first, it could unnecessarily scan or join many rows.
CBO should use this cardinality to drive an optimal plan; RBO may fail without the right FROM order or indexes.
SELECT
Emp_name
FROM
employee
WHERE
department = 'FINANCE'
AND
status = 3 /*+ Retired employee */;
✅ Extracted SQL Code from Image: 🔍 Analysis:
This query retrieves the names of employees who:
Belong to the FINANCE department
Have a status = 3, which (according to the comment) means retired
Note: The comment `/*+ Retired employee */` is *not* an optimizer hint; it is just a regular inline comment. If this were meant as a hint, it would require proper syntax like `/*+ INDEX(emp_status_idx) */`.
⚠️ Potential Optimization Concern:
Based on the previous diagram:
Only 100 of 100,000 employees meet both conditions.
If Oracle evaluates department = 'FINANCE' first (5,000 rows), and only then filters status = 3 (yields just 100), it's better than starting from all rows.
But ideally, the most selective predicate (status = 3) should be applied first, especially if there's an index on status.
✅ Image Analysis: Index Selectivity and Access Paths
This image illustrates the concept of index selectivity in the context of optimizing SQL queries using the employee table.
🧩 Components in the Image: 🗂️ Main Object:
* A representation of the `employee` table, shown as a vertical file with rows.
🏷️ Indexed Columns Highlighted:
status field:
Annotated as: retired 50%
Implies: 50% of employees are retired (status = 3)
department field:
Annotated as: finance 5%
Implies: only 5% of employees are in the Finance department (department = 'FINANCE')
📘 Transcribed Text Below Image:
The most efficient way to access a table with an index is to scan the most selective index, in this case the DEPARTMENT index.
This is because you know that only 5% of the employees are in the Finance department, while the retired population constitutes 50% of the employees.
🔍 Key Insight:
Index selectivity = (number of matching rows) / (total rows)
Lower selectivity ratio → more efficient index
So:
department = 'FINANCE' → 5% match → more selective
status = 3 (retired) → 50% match → less selective
> Therefore, even though you may want to retrieve retired employees, using the department index first will drastically reduce the rows scanned and improve performance.
💡 Summary:
Use the most selective predicate first when designing execution paths.
In this scenario, the DEPARTMENT index is preferred for initial filtering over the STATUS column.
SELECT STATEMENT
SORT AGGREGATE
SELECT BY ROWID EMPLOYEE
NON-UNIQUE INDEX NON-SELECTIVE RANGE SCAN
status_ix(status)
📘 Transcribed Commentary Text:
When you EXPLAIN this SQL with the rule-based optimizer, you'll see this plan.
The rule-based optimizer is choosing to scan through all 50,000 retired employees looking for the 100 that belong to the Finance department.
Obviously, the rule-based optimizer has made a less than optimal choice of indexes.
🔍 Analysis:
The plan shows that Oracle is using the `status_ix` index on the `status` column.
This index access is labeled as:
NON-UNIQUE INDEX
NON-SELECTIVE RANGE SCAN
This means:
The `status` column (with 50% of employees marked `retired`) is not selective.
So the optimizer is scanning 50,000 rows for `status = 3` and then filtering by `department = 'FINANCE'`, resulting in just 100 matches.
This is inefficient compared to using an index on `department` (which would access only 5,000 rows).
💡 Key Optimization Lesson:
Rule-Based Optimizer (RBO) lacks the intelligence to choose the most selective index.
This example demonstrates why Oracle deprecated RBO—it does not consider data distribution (cardinality).
A Cost-Based Optimizer (CBO) would likely choose the department index first due to its higher selectivity (5% vs. 50%).
✅ Transcribed SQL Plan Output from Image:
SELECT STATEMENT
SORT AGGREGATE
SELECT BY ROWID EMPLOYEE
NON-UNIQUE INDEX NON-SELECTIVE RANGE SCAN
dept_ix(department)
📘 Transcribed Commentary Text:
Now EXPLAIN this SQL with the cost-based optimizer.
The cost-based optimizer will be aware of the selectivity of the indexes and choose the index on the DEPARTMENT column.
This is a case where the cost-based optimizer has made a better decision.
🔍 Analysis:
In this plan, Oracle’s Cost-Based Optimizer (CBO) chooses:
The dept_ix(department) index for access.
Though still labeled as a non-unique, non-selective range scan, it is in fact more selective than the status_ix(status) path (5% vs. 50%).
CBO uses statistics (like column cardinality and histogram data) to determine that using the DEPARTMENT index will retrieve fewer rows, improving performance.
💡 Summary Comparison:
Optimizer
Index Used
Rows Scanned
Selectivity
Efficiency
Rule-Based
status_ix(status)
50,000 (retired)
50%
❌ Less efficient
Cost-Based
dept_ix(department)
5,000 (finance)
5%
✅ More efficient
What can we do about the problem outlined in the series of images above?
Possible Solutions
There are several remedies:
Add an index hint:
SELECT /*+ INDEX dept_ix */
Add a cost-based hint:
SELECT /*+ ALL_ROWS */
Invalidate the STATUS index.
Invalidating an index is a common trick that is used when the rule-based optimizer makes a bad choice of indexes.
Disabling unwanted indexes
Unwanted indexes can be disabled by mixing data type on the index. For example, we know that the status field is a numeric index, so we could concatenate a null character value to the predicate to invalidate it. Oracle will see the data type mismatch, and bypass that index. In the example below, we have concatenated a null character “” to the status predicate:
SELECT
Emp_name
FROM
employee
WHERE
department = ‘FINANCE’
AND
status = 3||0;
Now let us look at tricks for repositioning items in the FROM clause to improve the speed of rule-based SQL queries.