| Lesson 2 | Overview of the rule-based optimizer |
| Objective | Describe major features of the rule-based optimizer. |
Overview of Rule-based optimizer
The Oracle Rule-Based Optimizer (RBO) has been deprecated since Oracle 11g.
Here's a breakdown of what this means:
Deprecation vs. Removal
Status of Oracle RBO
Why Deprecate the RBO?
What Should I Do?
Deprecation vs. Removal
- Deprecation: A feature is marked as deprecated when the vendor intends to remove it entirely in future versions. Deprecation is a way to signal to users that they should stop relying on the feature and migrate to alternatives.
- Removal: Features are actually removed from the software in a later release.
Status of Oracle RBO
- Deprecated: From Oracle 11g, Oracle strongly discourages using the RBO and recommends switching to the superior Cost-Based Optimizer (CBO).
- Still Technically Present: While deprecated, Oracle hasn't completely removed code for RBO in recent versions. This is done for compatibility with very old applications. However, you won't find any support or future development of the RBO.
- Default Optimizer: The CBO is the default optimizer and the way forward in modern Oracle database versions.
Why Deprecate the RBO?
- Predictability: RBO decisions were based on a fixed set of rules, making its behavior predictable but often suboptimal for complex queries.
- CBO Advantages: The CBO considers database statistics, providing more sophisticated analysis of available data to generate much more efficient execution plans.
What Should I Do?
- New Development: Always use the CBO and the default settings for your Oracle database version.
- Legacy Applications: If you have very old applications still relying on RBO, create a migration plan to upgrade them for CBO compatibility. This will ensure better performance and long-term support.
Theory of rule-based Optimization
When we use rule-based optimization, we do not have any information about the nature of the data in our table or indexes. Specifically, we do not know important information such as the number of rows in the tables or the distribution of values within an index. However, we do know the types of indexes that are defined for the table, and all of the metadata in the Oracle dictionary. Using this metadata, the rule-based optimizer will choose an execution plan that uses an index whenever one is appropriate.
- Hierarchy of rules:
In addition, the rule-based optimizer will formulate the execution plan according to the following hierarchy of rules.

Single row by rowid Single row by cluster join Single row by hash cluster key with unique or primary key Single row by unique or primary key Cluster join Hash cluster key Indexed cluster key Composite key Single-column indexes Bounded range search on indexed columns Unbounded range search on indexed columns Sort-merge join MAX or MIN of indexed column ORDER BY on indexed columns Full table scan
Hierarchy of rulesEfficiency Rank Access Method Notes 1 Single row by rowid Fastest access: direct lookup via known ROWID. 2 Single row by cluster join Fetch single row through a cluster join — very fast. 3 Single row by hash cluster key with unique or primary key Hash-based lookup using unique/primary keys. 4 Single row by unique or primary key Direct index lookup via unique constraint. 5 Cluster join Join operation within a clustered table. 6 Hash cluster key Access via hash cluster's key without primary/unique constraints. 7 Indexed cluster key Access via index on cluster key. 8 Composite key Access using multiple columns in an index (composite). 9 Single-column indexes Simple indexes on single columns, relatively efficient. 10 Bounded range search on indexed columns Searching within a defined range (BETWEEN, >=, <=) using indexes. 11 Unbounded range search on indexed columns Open-ended range search, less efficient (> or < without a limit). 12 Sort-merge join Costlier than index lookups; used when indexed joins are not feasible. 13 MAX or MIN of indexed column, ORDER BY on indexed columns Sorting operations even if using indexes can be moderately expensive. 14 Full table scan Least efficient; scanning every row in the table sequentially. - Hierarchy is used by Oracle: This hierarchy is used by Oracle's rule-based optimizer (which is no longer supported and exists only for backward compatibility) to speed access times. Note that the full-table scan is at the bottom if this list. In most cases, this is correct, but we know that there are specific instances when a full-table scan can be faster than in index range scan. (Such as when we access more than 70 percent of the table rows, or when there are very few rows in the table.) Let us examine the actual steps used by the rule-based optimizer. The following series of images will illustrate the process.
Rule-based Optimizer Process
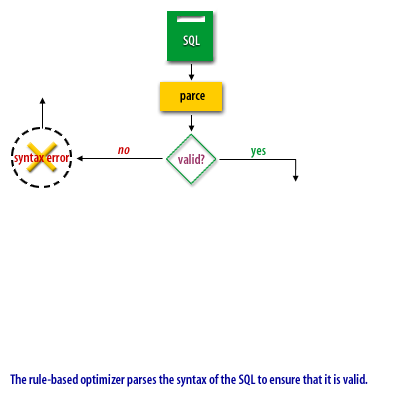
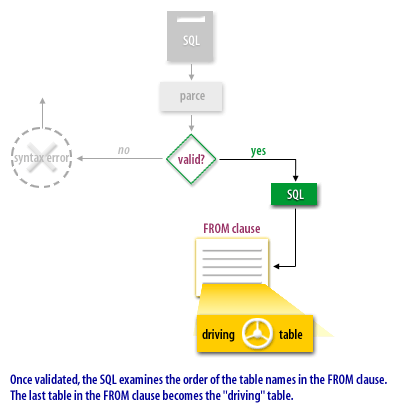
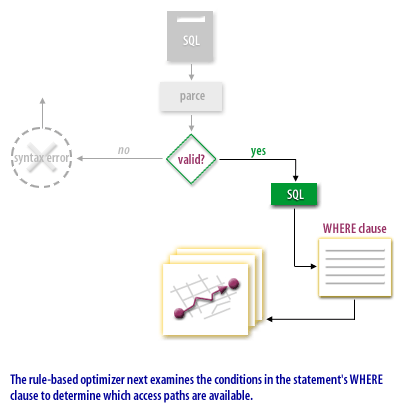
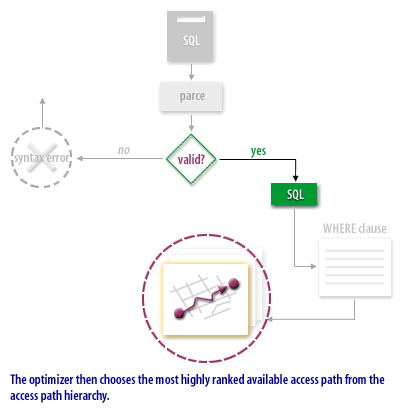
Now that we see the overall flow, let us turn our attention to some of the benefits of rule-based optimization.