You need to know that the data in your database is good and that the instance
is giving you all the information you need. This is why checkpoints were created.
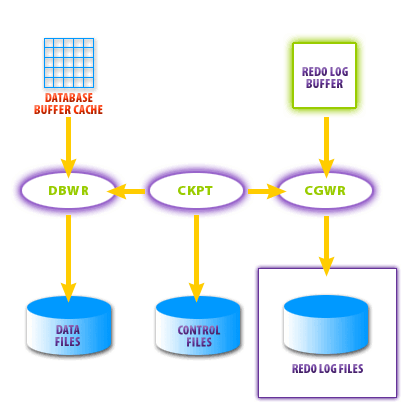
The CKPT process is a coordinator process. CKPT works with the DBWR and LGWR processes to make sure that all the modified database buffers are written to disk and that the headers of the control files and redo log files are marked as current. At the end of a checkpoint, you know that all the modified buffers in the data buffer cache and the redo log buffer have been written to disk. This coordination is diagrammed below.
Checkpoint process
What causes a checkpoint?
You can force a checkpoint by issuing commands from SQL*Plus or Oracle SQL Developer, for example:
> alter system checkpoint local
> alter system checkpoint global
In other cases checkpoint events are automatically processed by normal events such as:
When a redo log file fills, the LGWR switches to another redo log file
If you have set LOG_CHECKPOINT_TIMEOUT (an init.ora parameter) and the specified interval has lapsed
If you have set LOG_CHECKPOINT_INTERVAL (an init.ora parameter) and the specified number of disk block have been written to the redo log files
During a normal instance shutdown
If you take a tablespace off line
If an online backup is started
Checkpoint
Checkpoints are database synchronization events. At every checkpoint, all dirty buffers in the database buffer cache are written to the data files by DBWn. The CKPT background process updates the header of all data files and the control files to reflect the completion of the checkpoint. All files are now synchronized. If an instance failure occurs, Oracle only needs to recover the transactions that have
occurred since the last checkpoint. Checkpoints occur for all data files or for individual files. Checkpoints on individual files occur only when data files are taken offline.
The DBWn process is always writing out dirty buffers from the database buffer cache, therefore, the number of dirty buffers that need to written out during a checkpoint depends on how active the DBWn process has been since the last checkpoint.
Many of the dirty buffers will have already been written out prior to the checkpoint event being triggered. The response delay for a checkpoint is typically one to two seconds but depends on the number of blocks that need to be written out. If the
response delay is larger than two seconds it is usually an indication that checkpoints are not happening frequently enough.
Checkpoints can be forced manually by the ALTER SYSTEM CHECKPOINT command or automatically when one of the following events occurs:
At every log switch
When the instance is shutdown using the normal, immediate, or transactional options
When forced by one of the following database initialization parameters:
LOG_CHECKPOINT_INTERVAL, LOG_CHECKPOINT_TIMEOUT or FAST_START_IO_TARGET.
Note: If a SHUTDOWN ABORT is required, you should always attempt to perform a manual
checkpoint using the ALTER SYSTEM CHECKPOINT command. If this succeeds,
then instance recovery will not be required when the database is restarted.
lgwr ckpt - Quiz
Click the Quiz link below to test your understanding of LGWR, ARCH, and DBWR.
lgwr ckpt - Quiz
The next lesson explores database physical files.