| Lesson 3 | Normal ARCH processing |
| Objective | Discuss the flow of events in normal ARCH archive processing. |
Normal ARCH Processing
In Oracle 23ai, archived redo logs are still created the same fundamental way they were in earlier releases: when a redo log group becomes inactive after a log switch, Oracle’s ARCn archiver processes copy the contents of that redo log group to one or more archive destinations. What has improved over time is the operational tooling (better monitoring, more flexible destinations, more integrated recovery workflows), but the core flow of events remains recognizable.
This lesson walks through normal archive processing at the redo-log-member level: how ARCn opens log members, validates headers against control-file metadata, reads redo blocks, and writes them out as archived logs. The emphasis is on what happens when everything is healthy—and what Oracle does when a member is missing or corrupt.
Flow of events in normal ARCH archive processing
-
Log switch occurs.
The database writes redo into the current online redo log group until it fills. Oracle then performs a log switch and begins writing to the next available redo log group. The filled group becomes eligible for archiving once it is inactive (and once any required conditions are met).
-
ARCn selects the redo log group to archive.
ARCn identifies the group that must be archived based on the control file’s redo log metadata and the configured archive destinations. If the database is not in ARCHIVELOG mode, this archiving step does not occur.
-
ARCn attempts to open the redo log members.
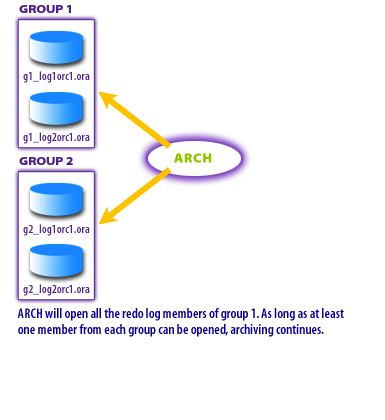
Each redo log group can contain multiple members (multiplexed copies). ARCn tries to open the members of the group. If at least one member can be opened, archiving continues. If no members can be opened, ARCn raises an error and the database cannot safely reuse the log group.
-
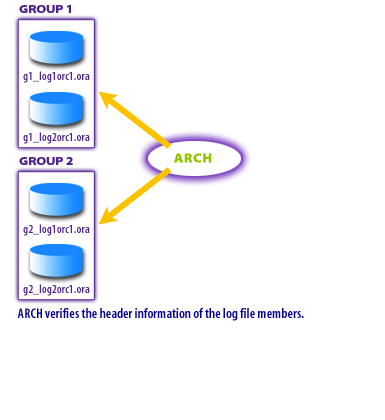
Header validation against the control file.
ARCn reads redo log file headers and verifies that the member metadata matches what Oracle expects (thread, sequence, log identifiers) as recorded in the control file. This reduces the risk of archiving from the wrong file or a stale/copy mismatch.
-
Block reads + basic verification.
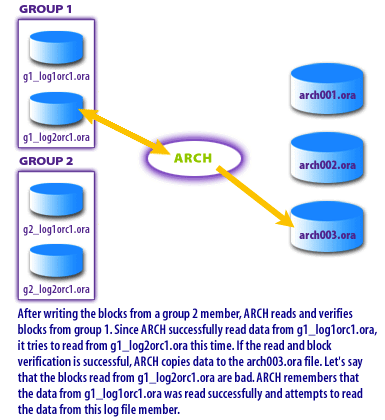
ARCn reads redo blocks from a redo log member, performs verification checks (integrity/consistency checks appropriate for redo blocks), and then writes those blocks out as an archived log file in the configured destination (for example,
arch003.orain the diagrams). ARCn is not “interpreting transactions” here; it is copying redo content as a recoverable stream. -
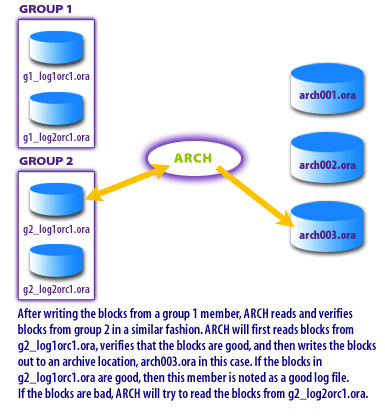
Member rotation and failover behavior.
When multiple members exist, ARCn can rotate reads across members. If ARCn successfully reads from a member, that member is noted as a “good” source for subsequent reads. If a read fails on a member, ARCn attempts to read the same block range from a member previously known to be good. Members that repeatedly fail are treated as bad and avoided for subsequent operations.
-
Control file update: archived status recorded.
After ARCn successfully writes the archived log(s), Oracle records the archived status in the control file. At that point, the corresponding online redo log group becomes eligible for reuse when Oracle needs it for a future log switch.
-
Backpressure safety: why databases “hang” when archiving fails.
In ARCHIVELOG mode, Oracle cannot reuse (overwrite) a redo log group until it has been archived. If archive destinations are full or ARCn cannot complete archiving, the database may stall at log switches. This is a safety mechanism that prevents loss of recoverability.
The diagrams below show this flow using a system with two redo log groups and two members per group. Pay attention to the “good member” tracking: it’s the reason multiplexing redo log members on separate disks historically improved resilience and distributed read I/O during archiving.
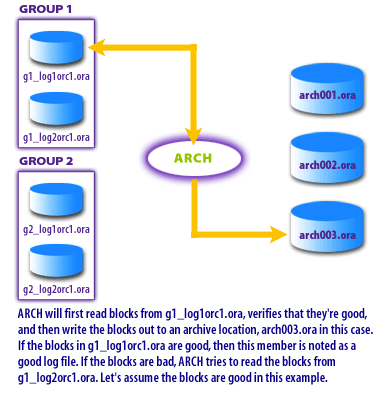
g1_log1orc1.ora), verifies the blocks, then writes them to the archive
destination (for example, arch003.ora). If a block read fails, ARCn retries from another member (for example, g1_log2orc1.ora).
The next lesson demonstrates how to manually archive online redo log files.