Define the steps associated with the tuning process
Objective
List the tuning steps.
Define Steps Associated with the Oracle Tuning Process
Oracle performance tuning is most effective when you follow a repeatable process instead of reacting randomly to symptoms.
In practice, tuning work falls into two categories:
Proactive tuning: monitoring, baselining, and continuously correcting problems before users notice them.
Reactive tuning: responding to a performance incident after users report slow response time, timeouts, or failed workloads.
Reactive tuning is often the most visible kind of tuning because it occurs under pressure. A structured workflow keeps you from “chasing noise” and helps you isolate whether the bottleneck is outside the database (network, host, storage) or inside the database (instance pressure, SQL, contention).
The figure below summarizes a practical incident-response tuning flow. The sub-tasks represent what you would typically confirm in each step.
(Your specific tooling will vary depending on whether you run Oracle on-premises or in OCI.)
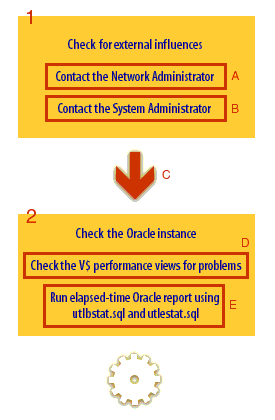
Step 1: Verify external influences (rule out false positives)
Confirm there are no network slowdowns, DNS issues, or routing bottlenecks impacting client connectivity.
Coordinate with the Network Administrator if connection latency or packet loss is suspected.
Coordinate with the System Administrator (or cloud ops) to confirm host health (CPU saturation, memory pressure, I/O latency).
Step 2: Verify database instance health (establish where time is going)
Confirm the database is the source of the slowdown (not the application tier).
Check key workload indicators: top wait classes/events, active sessions, load, and I/O profile.
Capture a performance “snapshot” using modern tooling (AWR/ASH/SQL Monitor) or lightweight V$ diagnostics.
Step 3: Identify the dominant bottleneck
Classify the problem as CPU-bound, I/O-bound, concurrency/locking, memory pressure, or inefficient SQL/execution plans.
Find top SQL (by elapsed time, CPU time, buffer gets, and I/O) during the incident window.
Step 4: Implement the smallest safe corrective action
Prefer SQL and schema-level fixes first (indexes, rewrites, plan stability) before instance-level changes.
If configuration changes are required, make them measurable, reversible, and aligned with Oracle 23ai best practices.
Step 5: Validate and prevent recurrence
Re-test response time and throughput; confirm the dominant wait/bottleneck has moved or disappeared.
Record the root cause, corrective action, and monitoring thresholds for early detection next time.
Steps in the tuning process
Steps in the Oracle Tuning Process
When a performance incident is reported, follow this order. The intent is to eliminate external causes first, then isolate the database bottleneck,
then apply a controlled fix.
Confirm host health: CPU utilization, run-queue depth, memory pressure/swapping, and disk I/O latency on the database server.
Confirm the database is the bottleneck: verify active sessions, waits, and the timeframe of degradation.
Collect diagnostics for the incident window: identify top SQL and top wait events/classes; capture evidence before making changes.
Apply corrective action: start with SQL/plan/schema fixes; use configuration changes only when justified by evidence.
Validate and document: confirm performance improved, and preserve the incident narrative (symptom → evidence → root cause → fix).
Important modernization note (Oracle 23ai): many historic “tuning scripts” and init.ora-era advice (for example, manually increasing
db_block_buffers, relying on simplistic hit ratios, or tuning freelists/rollback segments) does not align with modern Oracle defaults:
Memory is typically managed with Automatic Memory Management (or SGA/PGA targets) rather than hand-tuned cache parameters.
Undo management is automatic; “rollback segments” as a tuning target are largely historical.
ASSM-managed tablespaces remove most freelist tuning considerations.
Some waits such as SQL*Net message from client are commonly idle waits and are not performance problems.
Capturing a Performance Snapshot in Oracle 23ai
Earlier versions of this lesson included legacy snap.sql (and sample output) from decades ago. While a snapshot concept is still valid,
that output is not representative of modern Oracle workloads or modern diagnostic methods.
Recommendation: remove the legacy sample output and replace it with an Oracle 23ai-appropriate approach that teaches the same idea:
“capture evidence for the incident window, then diagnose based on where time is spent.”
There are two common paths, depending on licensing and environment:
AWR/ASH/SQL Monitor path (preferred in enterprise environments): best for incident windows and top-SQL analysis.
Note: AWR/ASH and related features generally require the appropriate Oracle management pack licensing.
Lightweight V$ diagnostics path (works everywhere): use dynamic performance views to quickly identify top waits, sessions, and SQL.
Option 1: AWR Snapshot and Report (Modern Baseline)
The goal is to capture “before” and “after” evidence around the incident window and then generate a report.
AWR is commonly used for this purpose because it summarizes workload, waits, and top SQL.
Create a snapshot:
-- Requires appropriate privileges (and licensing in many environments)
EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT;
Generate an AWR report for a snapshot range:
-- Example outline (IDs vary per system)
-- 1) Find DBID and instance number
SELECT dbid FROM v$database;
SELECT instance_number FROM v$instance;
-- 2) Identify snapshot IDs around the incident window
SELECT snap_id, begin_interval_time, end_interval_time
FROM dba_hist_snapshot
ORDER BY snap_id DESC;
-- 3) Produce a text report (example)
SELECT *
FROM TABLE(
DBMS_WORKLOAD_REPOSITORY.AWR_REPORT_TEXT(
l_dbid => (SELECT dbid FROM v$database),
l_inst_num => (SELECT instance_number FROM v$instance),
l_bid => :begin_snap,
l_eid => :end_snap
)
);
In the report, focus on:
Top wait events/classes (where session time is spent)
Top SQL by elapsed time, CPU time, buffer gets, and physical reads
I/O profile, latch/mutex contention indicators, and concurrency signals
Option 2: Lightweight Diagnostics with V$ Views (Universal)
If you cannot use AWR/ASH (or you want rapid triage first), the following checks are reliable and modern. These queries help you answer:
“Are we CPU-bound, I/O-bound, or waiting on concurrency?”
1) What are sessions waiting on right now?
SELECT wait_class, event, COUNT(*) AS sessions
FROM v$session
WHERE state = 'WAITING'
AND wait_class <> 'Idle'
GROUP BY wait_class, event
ORDER BY sessions DESC;
2) Which sessions are active, and what are they running?
SELECT s.sid, s.serial#, s.username, s.status, s.sql_id, s.event, s.wait_class
FROM v$session s
WHERE s.username IS NOT NULL
ORDER BY s.status DESC;
3) Top SQL by elapsed time (since cursor load):
SELECT sql_id,
executions,
elapsed_time/1e6 AS elapsed_seconds,
cpu_time/1e6 AS cpu_seconds,
buffer_gets,
disk_reads
FROM v$sql
ORDER BY elapsed_time DESC
FETCH FIRST 10 ROWS ONLY;
These checks do not replace a full incident report, but they provide rapid direction for Steps 3 and 4 of the tuning process.
Connectivity Modernization Note (Oracle Net Services)
Historic scripts and outputs often refer to “SQL*Net” as if it is an active tuning target. In modern Oracle, you will still see wait events with
SQL*Net message to client and SQL*Net message from client, but these are frequently idle waits that represent normal client/server messaging.
They should not be treated as bottlenecks unless the evidence clearly indicates network latency is driving response time.
For Oracle 23ai connectivity, favor modern connection methods such as Easy Connect Plus (service-based connections) and, in OCI contexts,
OCI-native connectivity patterns and wallet-based TLS where appropriate. The tuning workflow remains the same: first verify the network is healthy,
then prove the database is the bottleneck before tuning inside the instance.
Do not be concerned if you are not yet familiar with every view and metric referenced above. The purpose of this lesson is to define the tuning workflow.
Later lessons will revisit these diagnostics in depth and show how to build a repeatable tuning plan for your environment.
Tuning Process - Exercise
Before moving to the next lesson, click the Exercise link below and see if you can put the tuning steps in the correct order.
Tuning Process - Exercise