Group by and having Clauses
You will want to find trends in your data that will require the database server to cook the data a
bit before you retrieve your result set. One such mechanism is the group by clause, which is used to group data by column values.
For example, rather than looking at a list of employees and the departments to which they are assigned, you might want to look at a list of departments along with the number of employees assigned to each department. When using the group by
clause, you may also use the having clause, which allows you to filter group data in the same
way the where clause lets you filter raw data.Here's a quick look at a query that counts all the employees in each department and returns thenames of those departments having more than two employees:
mysql> SELECT d.name, count(e.emp_id) num_employees -> FROM department d INNER JOIN employee e -> ON d.dept_id = e.dept_id -> GROUP BY d.name -> HAVING count(e.emp_id) > 2; +----------------+---------------+ | name | num_employees | +----------------+---------------+ | Administration | 3 | | Operations | 14 | +----------------+---------------+ 2 rows in set (0.00 sec)
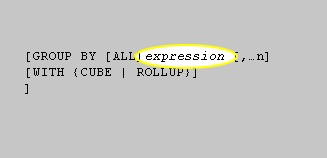
GROUP BY syntax