| Lesson 5 | How do SQL dialects differ? |
| Objective | Understand the Various Dialects in SQL |
SQL Dialect Variations
SQL dialects are vendor-specific or platform-specific variations of SQL. Most database engines implement a shared “core” that resembles the ANSI/ISO SQL standard, but they diverge in the details—syntax, supported features, data types, indexing options, procedural extensions, and even default behaviors.
From a relational theory standpoint, SQL is the dominant practical language for relational databases, but it is not a pure expression of the relational model. SQL includes features that go beyond the model (NULLs, duplicate rows by default, non-relational data types, procedural extensions, vendor-specific optimizer hints, etc.). Dialects exist partly because vendors innovate at different speeds and partly because the standard leaves room for variation.
The practical takeaway: learning “SQL fundamentals” gives you portability, but real-world work always requires learning the dialect rules of your target platform (Oracle, PostgreSQL, SQL Server, MySQL/MariaDB, SQLite, and so on).
Capitalization and case rules
SQL keywords (SELECT, FROM, WHERE) are case-insensitive in mainstream engines.
That means select and SELECT are treated the same. Capitalization is primarily a style choice
that improves readability.
The major dialect differences show up with identifiers (table names, column names, aliases), especially when you use quoted or delimited identifiers:
- Unquoted identifiers: many engines fold names to a default case internally (often uppercase in Oracle, lowercase in PostgreSQL). This affects how the database stores and reports object names.
- Quoted identifiers: names inside quotes are typically treated as case-sensitive and must be referenced consistently. Quoted identifiers also allow spaces and reserved words, which can reduce portability and increase friction.
- Environment-specific behavior: some platforms have additional rules (for example, file system effects on MySQL table name casing on certain operating systems). When your code “looks right” but fails to resolve an object name, casing rules are a common culprit.
For portable SQL, prefer: unquoted identifiers, consistent naming conventions, and keyword capitalization that helps humans scan queries quickly.
How dialects differ in everyday SQL
Dialect differences show up in both small syntax choices and large feature areas. Here are common categories you’ll encounter as you move between platforms:
-
Bind variables and parameters:
Oracle commonly uses named bind variables (for example
:dept_id) in certain tools and APIs, while other engines use positional placeholders (often?) or different parameter markers depending on the driver and language. -
String concatenation and functions:
some dialects prefer
||, others preferCONCAT(), and function availability varies widely (date/time arithmetic, regex support, JSON functions, etc.). -
Pagination syntax:
limiting and paging results differs (
FETCH FIRST,LIMIT,TOP, and variations that evolved historically). - Data types: core types overlap, but details differ (boolean support, identity/sequence behavior, timestamp precision, JSON storage, large object handling).
- DDL and constraint syntax: tablespaces, storage options, clustering, partitioning, computed columns, and constraint features vary by vendor.
- Transactions and isolation: default isolation levels, locking strategies, and concurrency behavior differ—especially noticeable when moving between OLTP-oriented engines and analytics-optimized systems.
Although this course focuses on foundational SQL, a realistic workflow is: learn the relational concepts (relations, keys, functional dependencies, normalization), learn portable query patterns, then learn your platform’s dialect features and limitations.
Procedural extensions
SQL is a declarative language: you describe what result you want, not how to produce it. Many database applications also require procedural logic (loops, conditions, error handling, reusable routines). For that reason, most platforms provide a procedural extension or a tightly integrated runtime.
Examine the following diagram for common procedural and runtime extensions across SQL platforms:
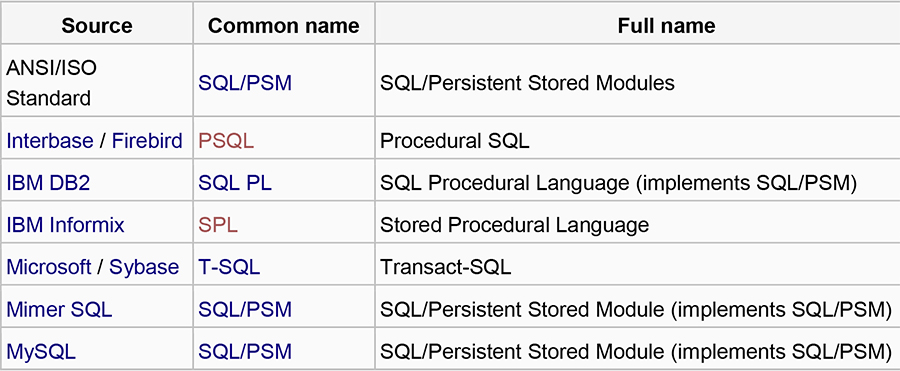
| Source | Common name | Full name |
|---|---|---|
| ANSI/ISO Standard | SQL/PSM | SQL/Persistent Stored Modules |
| Interbase / Firebird | PSQL | Procedural SQL |
| IBM DB2 | SQL PL | SQL Procedural Language (implements SQL/PSM) |
| IBM Informix | SPL | Stored Procedural Language |
| Microsoft / Sybase | T-SQL | Transact-SQL |
| Mimer SQL | SQL/PSM | SQL/Persistent Stored Module (implements SQL/PSM) |
| MySQL | SQL/PSM | SQL/Persistent Stored Module (implements SQL/PSM) |
The following table describes 1) Source, 2) Common Name, and 3) Full name
In addition to standard SQL/PSM concepts and vendor-specific procedural languages, many engines support integration with other runtimes:
- Oracle: PL/SQL for stored procedures, functions, packages, and triggers; Java integration exists historically, while modern architectures often keep application logic in services and keep database routines focused on data-centric logic.
- SQL Server: T-SQL as the primary procedural language; CLR integration exists for managed code scenarios, but it is typically used selectively due to operational complexity.
- PostgreSQL: PL/pgSQL plus optional procedural languages (for example PL/Python) depending on configuration and security posture.
- MySQL/MariaDB and SQLite: support stored program constructs to varying degrees; feature depth and syntax differ.
Neighboring topic to keep in mind: as SQL engines expand into JSON, text search, graph features, and distributed execution, dialect differences increase. That makes portability a design choice: you can write “lowest common denominator” SQL for maximum portability, or you can leverage platform strengths for performance and features.
In the next lesson, you’ll put SQL into practice by implementing a database and running queries against it.
SQL Approaches - Quiz
SQL Approaches - Quiz