| Lesson 7 | Indexes and engines |
| Objective | Describe how Indexes are used by the Database Engine. |
How Database Indexes Work (SQL Engine and Query Optimizer)
How the Database Engine Uses an Index
Index Structure — Key Values and Row Locators
An index is a separate data structure maintained by the database engine alongside the base table. It stores two things for each indexed row: the key value — the value of the indexed column or columns — and a row locator — a pointer to the physical location of the corresponding row in the base table. The key values are stored in sorted order, organized into a B-tree structure that supports fast lookup, range traversal, and ordered access.When the engine uses an index to answer a query, it navigates the B-tree to find the matching key values, retrieves the row locators for those keys, and then fetches the corresponding rows from the base table using those locators. This two-step process — index lookup followed by row fetch — is faster than a full table scan for selective queries, because the index navigation eliminates the need to examine every row in the table.
An Index Is Not Automatically Used
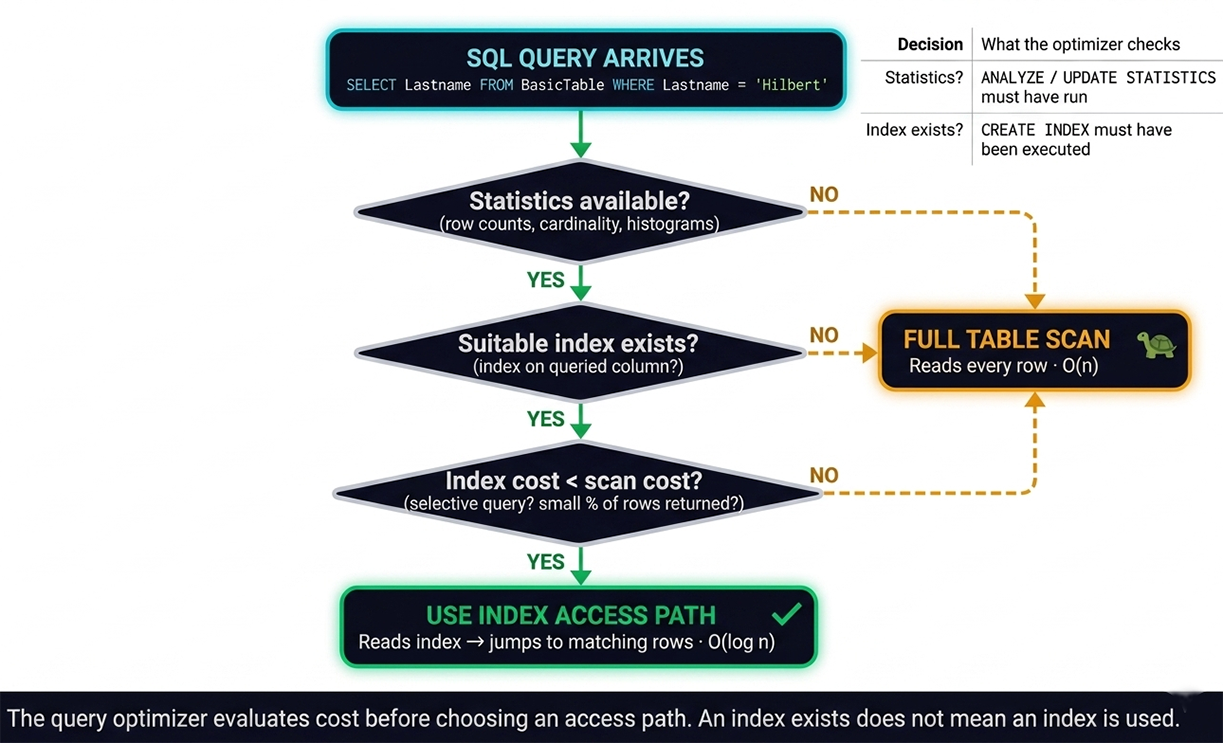
A common assumption among developers new to database performance is that creating an index guarantees it will be used. This is incorrect. Whether an index is used for a given query depends on three conditions, all of which must be true: current statistics must be available, a suitable index must exist for the query's access pattern, and the optimizer must estimate that using the index costs less than a full table scan.
If any of these conditions is not met, the optimizer chooses a full table scan. The index may exist, may be correctly defined, and may be perfectly suited to the query — but if statistics are stale or the query returns a large fraction of the table's rows, the optimizer still chooses the scan.
The Cost-Based Optimizer
Modern relational databases use a cost-based optimizer — a component of the query engine that estimates the execution cost of candidate query plans and selects the lowest-cost plan. Cost is measured in units of I/O operations, CPU cycles, and memory usage, weighted according to the engine's configuration. For each candidate plan, the optimizer estimates how many rows will be processed, how many pages will be read from storage, and how much memory the operation requires.
The optimizer does not execute candidate plans to measure their cost — it estimates cost using statistics stored in the database's system catalog. These statistics include the number of rows in each table, the number of distinct values in each column (cardinality), and histogram data showing how values are distributed. The quality of the optimizer's decisions is directly proportional to the accuracy of these statistics.
Query Optimizer Decision Logic
Query Shape and Available Statistics
The optimizer examines the query's shape — its predicates, join conditions, ORDER BY clauses, and the columns referenced in SELECT — and matches that shape against the available indexes and statistics. A query with a selective WHERE clause on an indexed column is a strong candidate for index access. A query that selects all columns from a table without any WHERE clause is a candidate for a full table scan regardless of what indexes exist.The diagram below (Figure 4-7.1) shows the three sequential decisions the optimizer makes. All three conditions must evaluate to YES for the optimizer to choose the index access path. A NO at any decision point routes execution to a full table scan.
Index Selectivity — High vs Low Cardinality
Selectivity is the fraction of rows that match a given predicate. A highly selective predicate matches a small fraction of rows — WHERE email = 'gauss@example.com' on a users table with one million rows might match exactly one row, a selectivity of 0.0001%. A low-selectivity predicate matches a large fraction — WHERE status = 'ACTIVE' on the same table might match 80% of rows.
The optimizer strongly favors index access for highly selective queries and strongly favors full table scans for low-selectivity queries. The reason is physical I/O: an index lookup that finds one matching row reads only a handful of pages — the index pages traversed during B-tree navigation plus one data page for the matching row. A low-selectivity query that matches 80% of rows must read 80% of the table's data pages regardless — at that point, a sequential scan of all pages is often faster than the overhead of consulting the index for each of the 800,000 matching rows.
The Selectivity Tipping Point
There is a threshold — typically somewhere between 5% and 30% of the table's rows, depending on the engine, the storage system, and the table's physical organization — below which the optimizer prefers index access and above which it prefers a full scan. This threshold is not fixed; it is recalculated for each query based on the current statistics.
A practical implication: an index on a column with low cardinality — a boolean column, a status column with three possible values, a gender column — will rarely be used by the optimizer, because even a query for one specific value is likely to match enough rows to push the selectivity above the tipping point. High-cardinality columns — email addresses, unique identifiers, timestamps — are the best index candidates because their predicates are naturally selective.
Index Access Types
Index Unique Scan
An index unique scan occurs when the query predicate references a column with a unique index — a primary key or a column defined with CREATE UNIQUE INDEX — using an equality condition. Because the index guarantees at most one matching entry, the engine traverses the B-tree to the single matching leaf node and retrieves exactly one row locator. This is the fastest index access pattern: O(log n) tree traversal, one row fetch, done.-- Triggers an index unique scan on ContactID (primary key)
SELECT Firstname, Lastname
FROM Contacts
WHERE ContactID = 4;Index Range Scan
An index range scan occurs when the predicate specifies a range of values — using BETWEEN, greater-than, less-than, or LIKE with a leading non-wildcard prefix. The engine traverses the B-tree to the first matching entry and then reads forward through the sorted index entries until the range is exhausted.
-- Triggers an index range scan on idx_contacts_lastname
SELECT Firstname, Lastname
FROM Contacts
WHERE Lastname BETWEEN 'G' AND 'K';
-- Also a range scan — LIKE with leading literal
SELECT Firstname, Lastname
FROM Contacts
WHERE Lastname LIKE 'H%';WHERE Lastname LIKE '%ilbert' — a leading wildcard — cannot use the index, because the index is sorted by the first character of Lastname. A leading wildcard makes the predicate non-sargable (not Search ARGument ABLE), forcing a full table scan.
Full Index Scan
A full index scan reads all entries in the index in sorted order. It is used when the query needs all or most rows from the table but requires them in the index's sort order — for example, an ORDER BY on an indexed column with no selective WHERE clause. A full index scan is faster than a full table scan plus sort when the table's data pages are not in memory, because the index pages are smaller and may be cached more efficiently.
Full Table Scan — When the Optimizer Prefers It
A full table scan reads every data page in the table sequentially. The optimizer chooses a full table scan when: no suitable index exists; the query is not selective enough for index access to be faster; the table is small enough that the index overhead exceeds the scan cost; or the statistics indicate that the index is not selective for the specific values in the query predicate.
A full table scan is not always bad. On a small reference table with a few hundred rows, a sequential scan is faster than B-tree traversal. On a query that genuinely needs most of the table's rows, sequential I/O through the data pages is more efficient than the random I/O pattern of an index lookup followed by individual row fetches. The optimizer chooses full table scans when they are the correct choice — understanding when and why this happens is more useful than assuming every full scan is a performance problem.
ORDER BY and Index Order
Results Are Unordered Without ORDER BY
A common misconception is that SQL queries return rows in a predictable order. In ANSI SQL, the result set is an unordered relation unless an ordering is explicitly requested. Without an ORDER BY clause, the database engine is free to return rows in any order that is efficient for the chosen execution plan — the order of rows in the result is undefined and may change between executions as data is added, deleted, or the execution plan changes.This query returns all last names from BasicTable, but makes no guarantee about the order in which they appear:
SELECT Lastname
FROM BasicTable;How an Index Can Eliminate a Sort Operation
When you add ORDER BY, you are asking the engine to return rows in a defined sequence. If an index exists on the ORDER BY column, the optimizer may be able to satisfy the sort requirement by reading the index entries in key order rather than reading rows in physical storage order and sorting them afterward. Avoiding the sort operation reduces CPU and memory usage — particularly significant for large result sets.
-- With an index on Lastname, the engine may use ordered index access
-- to avoid an explicit sort — the result arrives in sorted order
-- directly from the index traversal
SELECT Lastname
FROM BasicTable
ORDER BY Lastname;Covering Indexes
What a Covering Index Is
A covering index is an index that contains all the columns needed to satisfy a query — the columns in the SELECT clause, the WHERE clause, and the ORDER BY clause — so that the engine can answer the query entirely from the index without ever accessing the base table. This is the most efficient index access pattern: the engine reads only the compact, sorted index pages and returns the result directly, eliminating the row-fetch step entirely.Consider a query that retrieves contact names filtered by last name:
SELECT Firstname, Lastname
FROM Contacts
WHERE Lastname = 'Hilbert';(Lastname, Firstname), this index covers the query: Lastname is the filter column (in the WHERE clause) and Firstname is the output column (in the SELECT clause). Both columns are in the index. The engine finds the matching Lastname entries in the index, reads the Firstname values from the same index entries, and returns the result without touching the Contacts base table data pages.
How to Design a Covering Index
To design a covering index, identify all columns referenced in the query's WHERE, SELECT, ORDER BY, and JOIN clauses. Include the most selective filter columns first (they are the leading index columns), followed by the additional columns needed to cover the SELECT list. For the query above, the index (Lastname, Firstname) covers the query efficiently — Lastname filters, Firstname is returned.
Covering indexes trade index size for query speed. A covering index that includes many columns is larger than a single-column index, requiring more storage and more memory in the buffer pool. The trade-off is worthwhile for queries that run frequently and return small result sets from large tables.
Statistics and Their Role
What Statistics the Optimizer Uses
The optimizer's cost estimates depend entirely on the accuracy of the statistics stored in the database's system catalog. The key statistics used for index decisions are: the total row count of each table; the number of distinct values (cardinality) in each indexed column; histogram data showing how values are distributed across the column's range; and the average row size and page count for each table.Cardinality is particularly important: a column with 1,000,000 distinct values in a 1,000,000-row table has cardinality of 1.0 — every value is unique, every predicate is maximally selective, indexes are almost always beneficial. A column with 3 distinct values in the same table has cardinality of 0.000003 — indexes on this column will rarely be used.
Stale Statistics and Their Effect
Statistics reflect the state of the table at the time they were last collected. After large data loads, bulk deletes, or significant updates to indexed column values, the statistics may no longer accurately represent the current data distribution. Stale statistics cause the optimizer to make decisions based on the old data state — it may underestimate or overestimate the selectivity of a predicate, leading to wrong access path choices: using a full scan when an index would be faster, or using an index when a full scan would be faster.
Refreshing Statistics
Most database systems update statistics automatically in the background — PostgreSQL's autovacuum, MySQL InnoDB's background statistics collection, SQL Server's auto update statistics. After major data changes, manually triggering a statistics refresh ensures the optimizer has current information:
-- PostgreSQL
ANALYZE Contacts;
-- MySQL
ANALYZE TABLE Contacts;
-- SQL Server
UPDATE STATISTICS Contacts;Using EXPLAIN to See the Optimizer's Decision
Index Scan vs Sequential Scan in EXPLAIN Output
The EXPLAIN statement, introduced in lesson 5, shows the execution plan the optimizer chose. The access method labels in EXPLAIN output correspond directly to the index access types covered in this lesson. In PostgreSQL,Index Scan means the optimizer used B-tree index navigation followed by row fetches; Seq Scan means a full sequential table scan; Index Only Scan means a covering index was used and the base table was never accessed.
-- PostgreSQL EXPLAIN output for a selective query on an indexed column
EXPLAIN SELECT Firstname, Lastname
FROM Contacts
WHERE Lastname = 'Hilbert';
-- Expected output with idx_contacts_lastname in place:
-- Index Scan using idx_contacts_lastname on contacts
-- Index Cond: ((lastname)::text = 'Hilbert'::text)
-- Expected output WITHOUT the index:
-- Seq Scan on contacts
-- Filter: ((lastname)::text = 'Hilbert'::text)-- EXPLAIN ANALYZE adds actual execution time and row counts
EXPLAIN ANALYZE SELECT Firstname, Lastname
FROM Contacts
WHERE Lastname = 'Hilbert';Speeding Up Searches — Common Index Use Cases
Selective WHERE predicates benefit most directly from indexes. A predicate like
WHERE Lastname = 'Hilbert' or WHERE ContactID = 4 returns a small fraction of the table's rows — exactly the condition under which index access is faster than a full scan. The more selective the predicate, the greater the performance benefit.
JOIN conditions between tables are the second major use case. When two tables are joined on
ON Orders.ContactID = Contacts.ContactID, an index on Contacts.ContactID allows the engine to look up each ContactID from the Orders table in the Contacts index rather than scanning the entire Contacts table for each Orders row. Without the index, the join requires O(n×m) comparisons; with it, O(n log m).
ORDER BY and GROUP BY operations are the third use case. When the ORDER BY column matches the index's leading column, the optimizer can read rows in sorted order from the index rather than reading rows in physical order and sorting them in memory. This eliminates the sort step entirely, reducing CPU and memory usage on large result sets.
Write Overhead — The Cost of Maintaining Indexes
This write overhead is the reason the best practice is to create indexes strategically — supporting the predicates, joins, and access patterns of the most important and most frequent queries — rather than indexing every column. Indexes improve read performance at the cost of write performance. The correct balance depends on the table's read-to-write ratio and the performance requirements of the application.
Lesson 8 moves from table structure and indexing to data manipulation — the SQL INSERT statement and how rows are added to the tables and indexes you have built in this module.
Database-Foundations - Quiz
Database-Foundations - Quiz
In the next lesson, we will look at how you insert information into the database.