| Lesson 7 | Normalize the example table |
| Objective | How do I know when a table is normalized. |
Table Normalization Example (Decomposing Customer Orders into Three Tables)
The Starting Point — The Unnormalized Customer Orders Table
| CustID | Name | City | Item_ID | Description | Qty | Total |
|---|---|---|---|---|---|---|
| 000001 | Smith | Tucson | 100101 | Green Widgets | 1 | $50.00 |
| 000001 | Smith | Tucson | 100102 | Blue Widgets | 2 | $100.00 |
| 000001 | Smith | Tucson | 100103 | Yellow Widgets | 1 | $50.00 |
| 000002 | Jones | L.A. | 100101 | Green Widgets | 2 | $100.00 |
| 000002 | Jones | L.A. | 100106 | Orange Widgets | 1 | $50.00 |
Every problem in this table traces back to the same root cause: it is trying to store facts about three distinct entities — customers, items, and order transactions — in a single flat structure. Normalization separates those entities into their own tables, each with its own primary key, and connects them through foreign key references.
The Decomposition Decision — Three Tables
Why Three Tables, Not Two or Four
The number of tables in the decomposition is determined by the number of distinct entities in the original table. A distinct entity is a real-world thing that has its own identity and its own set of attributes that describe it — independent of any other entity. In the Customer Orders table, three distinct entities are present: a customer (who has a name and a city), an item (which has a description and a price), and an order line (which records that a specific customer bought a specific item in a specific quantity).Two tables would not be enough — you cannot merge customers and items without reintroducing redundancy. Four tables would only be needed if one of the three entities had a sub-entity worth isolating — for example, if the city column were replaced with a full address requiring its own lookup table. With the data as given, three tables is the correct decomposition.
The Customer Table — One Row Per Customer
The Customer table extracts everything that describes a customer as an independent entity. CustID becomes the primary key — a value that uniquely identifies each customer across the entire system. Name and City are attributes of the customer; they belong here and nowhere else.After decomposition, Smith appears in exactly one row in the Customers table. Jones appears in exactly one row. Adding a new customer — Williams of Phoenix — requires one INSERT into this table, with no order data required. If Smith moves to Denver, one UPDATE to one row in this table corrects the city everywhere it is referenced, automatically and instantly.
The Item Table — One Row Per Product
The Item table extracts everything that describes a product as an independent entity. Item_ID becomes the primary key. Description is an attribute of the item. UnitPrice — the column that was missing from the original table — is added here, resolving the design flaw identified in lesson 6. The Total column in the original table was a derived value (Qty × UnitPrice) with no stored source. Placing UnitPrice in the Item table gives the database an authoritative source for the price, making Total calculable rather than stored.Green Widgets appear in exactly one row in the Items table. If the price of Green Widgets changes from $50.00 to $55.00, one UPDATE to one row in this table is all that is required. Every future order that references Item_ID 100101 will automatically use the current price.
The Order Table — One Row Per Transaction Line
The Order table records what happened: which customer bought which item, in what quantity. It stores no customer details and no item details — only the foreign key references that point to the rows in the Customer and Item tables where those details live. OrderLineID is a new surrogate primary key — a system-generated identifier that uniquely identifies each order line independent of the customer or item involved.CustID in the Order table is a foreign key referencing the Customers table. Item_ID in the Order table is a foreign key referencing the Items table. The database engine enforces referential integrity on both: no order line can reference a customer or item that does not exist, and the constraints can be configured to prevent orphaned order lines if a customer or item record is deleted.
SQL CREATE TABLE — Building the Normalized Schema
CREATE TABLE Customers
CREATE TABLE Customers (
CustID CHAR(6) NOT NULL,
Name VARCHAR(50) NOT NULL,
City VARCHAR(50) NOT NULL,
CONSTRAINT pk_customers PRIMARY KEY (CustID)
);CREATE TABLE Items
CREATE TABLE Items (
Item_ID CHAR(6) NOT NULL,
Description VARCHAR(100) NOT NULL,
UnitPrice DECIMAL(10,2) NOT NULL,
CONSTRAINT pk_items PRIMARY KEY (Item_ID)
);CREATE TABLE Orders
CREATE TABLE Orders (
OrderLineID INT NOT NULL AUTO_INCREMENT,
CustID CHAR(6) NOT NULL,
Item_ID CHAR(6) NOT NULL,
Qty INT NOT NULL,
CONSTRAINT pk_orders PRIMARY KEY (OrderLineID),
CONSTRAINT fk_cust FOREIGN KEY (CustID) REFERENCES Customers (CustID),
CONSTRAINT fk_item FOREIGN KEY (Item_ID) REFERENCES Items (Item_ID)
);Notice that Total is not in the Orders table. Total is a derived value — it can be calculated as Qty × UnitPrice at query time. Storing derived values creates a maintenance burden (the stored value must be updated whenever its inputs change) and a consistency risk (the stored value can diverge from its inputs if an update is missed). Omitting Total and calculating it in SQL is the correct normalized approach.
The Diagram — Visualizing the Decomposition
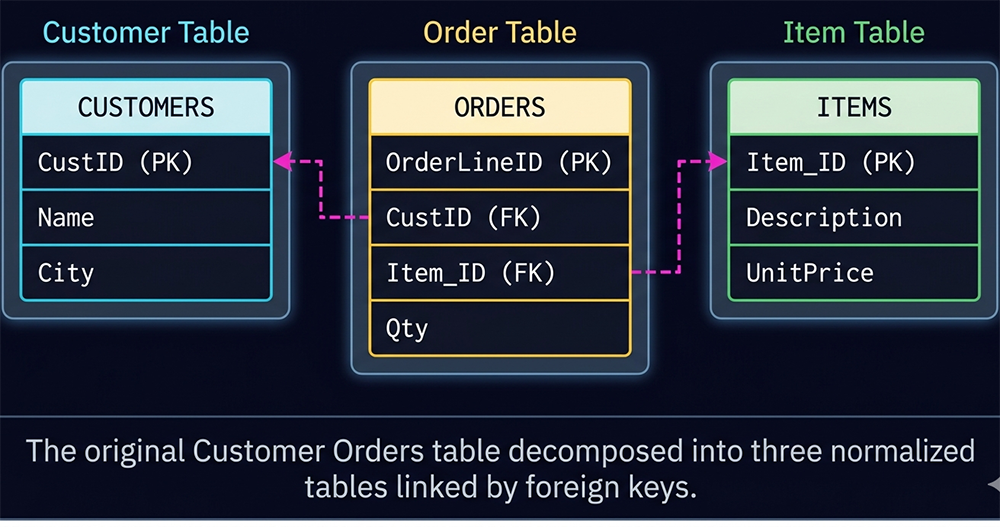
The Lossless JOIN — Proving the Decomposition Works
Reconstructing the Original Five Rows
SELECT
c.CustID,
c.Name,
c.City,
i.Item_ID,
i.Description,
o.Qty,
(o.Qty * i.UnitPrice) AS Total
FROM Orders o
JOIN Customers c ON o.CustID = c.CustID
JOIN Items i ON o.Item_ID = i.Item_ID
ORDER BY c.CustID, i.Item_ID;The Total column now has an authoritative source. If the unit price of Green Widgets changes in the Items table, this query immediately reflects the new price in every order that references Item_ID 100101. The original unnormalized table had no mechanism for this — the Total column was a stored value that could only be corrected by a manual UPDATE to every affected row.
This is the practical proof of lossless decomposition. The three normalized tables contain all the information that was in the original table — and they contain it in a form that is more reliable, more maintainable, and more queryable than the original flat structure.
The Single-Source Update Benefit
Changing Smith's City — Before and After
In the original unnormalized table, Smith's city "Tucson" appears in three rows. Updating it requires:-- Unnormalized: must touch three rows simultaneously
UPDATE CustomerOrders
SET City = 'Denver'
WHERE CustID = '000001';In the normalized schema, Smith's city exists in exactly one row in the Customers table:
-- Normalized: one row, one update, guaranteed consistency
UPDATE Customers
SET City = 'Denver'
WHERE CustID = '000001';What Propagates Systemwide and Why
The propagation is not a trigger or a cascading update — it is simpler than that. Because the Order table stores only the CustID foreign key and never stores Smith's city directly, every query that needs Smith's city retrieves it from the Customers table at query time via the JOIN. The moment the single Customers row is updated, every subsequent query automatically returns the new city. There is nothing to propagate because the city was never duplicated in the first place.This is the fundamental efficiency of the normalized schema: the database engine resolves references at query time rather than storing resolved values at write time. The cost is a JOIN operation on each read. The benefit is guaranteed consistency and single-point maintenance for every fact in the database.
Recognizing a Normalized Table
Applying the 1NF Check to the Three Tables
First Normal Form requires that every column contain atomic values — single, indivisible values of a consistent type — and that there are no repeating groups of columns. Check each of the three tables:
The Customers table has three columns: CustID (a single fixed-length identifier), Name (a single name string), and City (a single city name). Every cell contains one atomic value. No repeating groups. The Customers table satisfies 1NF.
The Items table has three columns: Item_ID (single identifier), Description (single product name), and UnitPrice (single decimal value). Every cell contains one atomic value. No repeating groups. The Items table satisfies 1NF.
The Orders table has four columns: OrderLineID (single auto-generated integer), CustID (single foreign key value), Item_ID (single foreign key value), and Qty (single integer). Every cell contains one atomic value. No repeating groups. The Orders table satisfies 1NF.
Applying the 2NF Check
Second Normal Form requires that every non-key attribute be fully functionally dependent on the entire primary key — no partial dependencies on part of a composite key. Check each table:
The Customers table has a single-column primary key (CustID). With a single-column key, partial dependency is impossible by definition — there is no "part of the key" to depend on partially. Name and City both depend fully on CustID. The Customers table satisfies 2NF.
The Items table has a single-column primary key (Item_ID). Description and UnitPrice both depend fully on Item_ID. The Items table satisfies 2NF.
The Orders table has a single-column primary key (OrderLineID). CustID, Item_ID, and Qty all depend fully on OrderLineID — knowing the order line ID tells you exactly which customer, which item, and what quantity. The Orders table satisfies 2NF.
Applying the 3NF Check
Third Normal Form requires that no non-key attribute be transitively dependent on the primary key through another non-key attribute. Check each table:
The Customers table: does City depend on Name rather than directly on CustID? No — two customers could share the same name but live in different cities. City depends directly on CustID, not transitively through Name. The Customers table satisfies 3NF.
The Items table: does UnitPrice depend on Description rather than directly on Item_ID? No — two items could have the same description at different price points. UnitPrice depends directly on Item_ID. The Items table satisfies 3NF.
The Orders table: does Qty depend on CustID or Item_ID rather than directly on OrderLineID? No — Qty is the quantity for this specific order line, identified by OrderLineID. It does not depend on the customer or the item independently. The Orders table satisfies 3NF.
The Practical Recognition Test
All three tables pass the 1NF, 2NF, and 3NF checks. The schema is normalized to the Third Normal Form — the standard target for transactional database design. The practical recognition test that confirms normalization is complete is this: can you change any single fact in the database by updating exactly one row in exactly one table? If yes, the schema is normalized. If changing a fact requires updating multiple rows, there is redundancy that normalization has not yet eliminated.
Apply this test to the three tables. Changing Smith's city: one row in Customers. Changing the price of Green Widgets: one row in Items. Recording a new order for Smith buying Blue Widgets: one INSERT into Orders. Recording a new customer: one INSERT into Customers. Each operation touches exactly one row in exactly one table. The schema passes the practical recognition test.
Table Normalization - Exercise
Table Normalization - Exercise
In the next several lessons, we will look at the different forms of normalization in detail — examining the specific rules for 1NF, 2NF, and 3NF and how to apply them to tables you encounter in real database design work.