| Lesson 3 | Key differences between relational and flat file databases |
| Objective | Understand the key differences between relational and flat file databases. |
Evolution of Database Models (Flat Files to AI-Integrated Knowledge Graphs)
Every database system you will encounter as a SQL developer sits somewhere on a long evolutionary timeline. That timeline begins before structured databases existed at all — with raw file systems and flat files — and extends forward into the AI-integrated knowledge graphs and vector stores that are reshaping data retrieval in 2026. Understanding where relational databases sit on that timeline, and what problems each preceding model failed to solve, gives you a much clearer picture of why SQL is designed the way it is and why the relational model has remained dominant for more than fifty years.
Key Differences Between Relational and Flat File Databases
Before tracing the full evolutionary arc, it is worth stating clearly what separates relational databases from the flat file systems that preceded them. Three distinctions define the divide.
First, relational databases store data without regard to the order in which it will be retrieved. Information is written to the database in whatever order it arrives, and the database engine organizes it dynamically at query time based on the structure defined in the schema. Flat file systems, by contrast, impose physical storage order directly onto the data — to find a record, you often have to know where it sits in the file. This difference is fundamental: relational databases separate the logical view of data from its physical storage, while flat files conflate the two.
Second, flat file and older non-relational databases typically rely on proprietary, hard-coded query approaches. An application written against a flat file database does not submit a query to an engine; it contains explicit code that opens the file, reads through it sequentially or by known position offsets, extracts the values it needs, and closes the file. Relational databases replaced this with a declarative query model — SQL — where the application states what data it wants and the database engine determines how to retrieve it. This separation of what from how is one of the most consequential design decisions in the history of computing.
Third, SQL compatibility is not a capability that can be assumed of older database engines. The SQL standard defines a specific set of query semantics, data types, and transaction behaviors. A flat file system or a hierarchical database engine does not implement those semantics natively. While some older systems have added SQL-like query interfaces over the decades, that compatibility is a retrofit — not a native architectural property. When you write SQL, you are depending on a relational engine that understands and enforces the full relational model.
First, relational databases store data without regard to the order in which it will be retrieved. Information is written to the database in whatever order it arrives, and the database engine organizes it dynamically at query time based on the structure defined in the schema. Flat file systems, by contrast, impose physical storage order directly onto the data — to find a record, you often have to know where it sits in the file. This difference is fundamental: relational databases separate the logical view of data from its physical storage, while flat files conflate the two.
Second, flat file and older non-relational databases typically rely on proprietary, hard-coded query approaches. An application written against a flat file database does not submit a query to an engine; it contains explicit code that opens the file, reads through it sequentially or by known position offsets, extracts the values it needs, and closes the file. Relational databases replaced this with a declarative query model — SQL — where the application states what data it wants and the database engine determines how to retrieve it. This separation of what from how is one of the most consequential design decisions in the history of computing.
Third, SQL compatibility is not a capability that can be assumed of older database engines. The SQL standard defines a specific set of query semantics, data types, and transaction behaviors. A flat file system or a hierarchical database engine does not implement those semantics natively. While some older systems have added SQL-like query interfaces over the decades, that compatibility is a retrofit — not a native architectural property. When you write SQL, you are depending on a relational engine that understands and enforces the full relational model.
The Evolution of Database Modeling
Database modeling did not arrive fully formed. Each generation of database technology emerged to solve problems that the previous generation could not adequately address, and each model introduced trade-offs that motivated the next generation's design. The diagram on this page maps that evolution across ten distinct model categories, from pre-1950 file systems through the AI-integrated knowledge graphs emerging at the 2026 frontier.
This was workable when programs were small and data volumes were modest. It became unmanageable as organizations grew and discovered that dozens of different programs needed to share and cross-reference the same data. The hierarchical model emerged in the 1960s to impose structure on that data for the first time. The network model followed in the late 1960s to address the hierarchical model's limitations. The relational model arrived in 1970 and eventually displaced both. Object, object-relational, cloud-native, NoSQL, NewSQL, and AI-integrated models followed as new classes of workloads created demands that the relational model alone could not satisfy.
Why Each Model Emerged
The earliest data storage was no model at all. Programs stored their data in files managed by the operating system — files that you could examine today by runningdir in a Windows command prompt, ls in a Unix or Linux shell, or browsing through Windows Explorer. The file system provided a naming structure and a location on disk, but nothing more. All organization, searching, and relationship management had to be programmed explicitly into every application that touched the data.
This was workable when programs were small and data volumes were modest. It became unmanageable as organizations grew and discovered that dozens of different programs needed to share and cross-reference the same data. The hierarchical model emerged in the 1960s to impose structure on that data for the first time. The network model followed in the late 1960s to address the hierarchical model's limitations. The relational model arrived in 1970 and eventually displaced both. Object, object-relational, cloud-native, NoSQL, NewSQL, and AI-integrated models followed as new classes of workloads created demands that the relational model alone could not satisfy.
The Next-Gen Convergence Trajectory
The diagonal trend line running through the diagram from the lower-left to the upper-right corner represents something important: the models on the right side of the chart did not replace the models on the left. They layered on top of them. Relational databases still handle the majority of transactional workloads in production systems worldwide. Flat files persist as the primary interchange format for data pipelines. Hierarchical structures appear inside JSON documents stored in document databases. Graph traversal has been added as an extension to PostgreSQL. The label in the upper-right corner of the diagram — "Next-Gen Convergence" — captures this reality: the future of data management is not a single dominant model but a converging ecosystem where capabilities from every prior era are available within integrated platforms.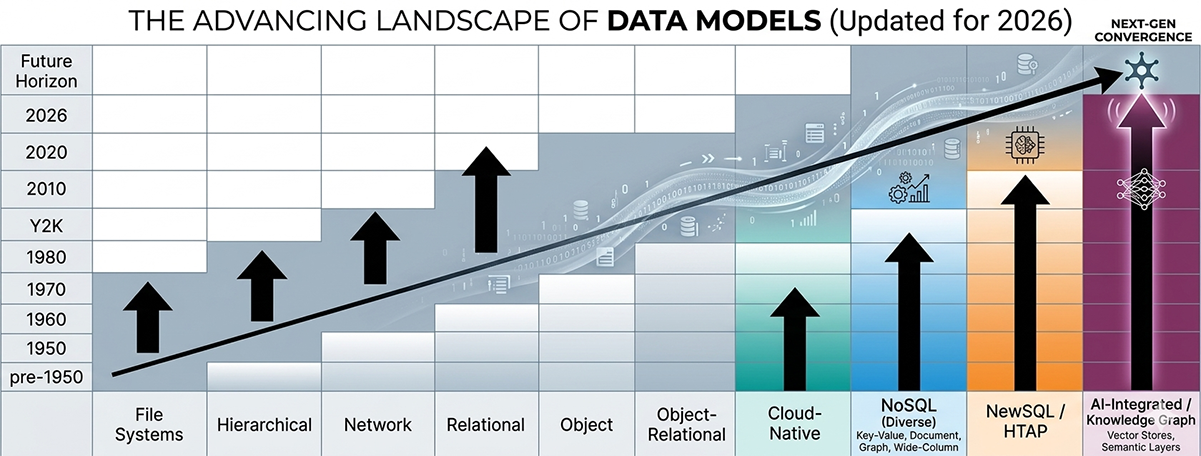
File Systems and Flat File Databases
Using a file system database model[1] implies that no modeling techniques are applied and that data is stored in flat files within the operating system's file hierarchy, with no database engine mediating access. The entire burden of organizing, searching, validating, and relating data falls on the application code.
A common point of confusion is whether CSV files qualify as flat files. By definition, a comma-delimited file contains structure — the commas delimit fields, and newlines delimit records. Classic flat file databases, however, used fixed-width fields with no delimiters whatsoever. A record might be 256 bytes long, with the customer name occupying bytes 1 through 40, the account number occupying bytes 41 through 50, and the balance occupying bytes 51 through 62. Finding the balance for a given customer meant scanning the entire file byte by byte until you found the right account number at the right offset, then reading the balance from its fixed position. A CSV file used with a spreadsheet application is not a flat file in this classical sense, though it shares the flat file characteristic of having no database engine managing access.
As computer memory became cheaper and more abundant over the 1980s and 1990s, it became technically feasible to hold larger and larger flat file databases entirely in memory for faster access. But this did not make flat files more capable as a database technology — it simply deferred the fundamental problems of structure, indexing, and concurrency to a larger scale.
xBase used a file-per-table architecture: one file contained the data, a separate header file described the column layout, and one or more additional index files tracked sorted orderings for faster lookups. A modest xBase application might have tens of database files on disk, and a large one might have hundreds. Managing these file collections — keeping the index files synchronized with the data files, handling file locking for concurrent access, and maintaining referential integrity across files — required explicit application code for every operation. When relational database systems became available on personal computers, the ability to consolidate those hundreds of xBase files into a single structured database with engine-managed indexes and constraints was immediately compelling.
CSV remains the most universally supported data exchange format precisely because it is the simplest. Every spreadsheet application, every database system, and every programming language can read and write CSV. It carries no schema, no data types beyond what the reading application infers, and no compression — but its simplicity is its strength for one-time data transfers and human-readable exports.
Parquet is a columnar binary format designed for analytical workloads at scale. Unlike CSV, Parquet stores each column's values contiguously, encodes data types explicitly, and applies compression per column using algorithms matched to the data distribution. A query engine reading a Parquet file can skip entire column groups that are not needed by the query, making Parquet far more efficient than CSV for large analytical datasets. Parquet is the storage format of choice for data lakes built on object storage systems like Amazon S3 and Google Cloud Storage.
JSON-L (JSON Lines) stores one JSON object per line, making it streamable and appendable without loading the entire file. It is the preferred format for log data, event streams, and machine learning training datasets, where records arrive continuously and the schema may vary between records. Flat files, in their modern forms, are not a relic — they are the connective tissue of the modern data stack.
What Is a Flat File?
The term flat file describes a simple text file that contains no inherent structure. Data is written sequentially, and the only way to find a specific value is to know its position in the file — either a byte offset or a line number — or to read the entire file from beginning to end and search for the value programmatically. There is no index, no query engine, and no schema enforcement. If two different programs write to the same flat file with different assumptions about the data format, the result is corruption.A common point of confusion is whether CSV files qualify as flat files. By definition, a comma-delimited file contains structure — the commas delimit fields, and newlines delimit records. Classic flat file databases, however, used fixed-width fields with no delimiters whatsoever. A record might be 256 bytes long, with the customer name occupying bytes 1 through 40, the account number occupying bytes 41 through 50, and the balance occupying bytes 51 through 62. Finding the balance for a given customer meant scanning the entire file byte by byte until you found the right account number at the right offset, then reading the balance from its fixed position. A CSV file used with a spreadsheet application is not a flat file in this classical sense, though it shares the flat file characteristic of having no database engine managing access.
Flat File Database — Technical Definition
A flat file database is stored on disk as an ordinary, non-indexed file. To read or modify any data, the application must load the entire file into memory, perform its operations in memory, and write the entire file back to disk when finished. There is no partial read, no random access by key, and no concurrent write safety — if two processes attempt to write the file simultaneously, the results are undefined. The database has no externally visible structure; from the perspective of the operating system, it is simply a blob of bytes with a filename.As computer memory became cheaper and more abundant over the 1980s and 1990s, it became technically feasible to hold larger and larger flat file databases entirely in memory for faster access. But this did not make flat files more capable as a database technology — it simply deferred the fundamental problems of structure, indexing, and concurrency to a larger scale.
xBase, dBase, and Btrieve — Legacy Flat File Systems
The most widely encountered flat file database systems in the history of personal computing were xBase, dBase, and Btrieve[2]. These systems were enormously popular in the 1980s and early 1990s, powering small business applications across industries before relational databases became affordable on personal computer hardware.xBase used a file-per-table architecture: one file contained the data, a separate header file described the column layout, and one or more additional index files tracked sorted orderings for faster lookups. A modest xBase application might have tens of database files on disk, and a large one might have hundreds. Managing these file collections — keeping the index files synchronized with the data files, handling file locking for concurrent access, and maintaining referential integrity across files — required explicit application code for every operation. When relational database systems became available on personal computers, the ability to consolidate those hundreds of xBase files into a single structured database with engine-managed indexes and constraints was immediately compelling.
Flat Files in 2026 — CSV, Parquet, and JSON-L
Flat files did not disappear when relational databases became dominant. They evolved and found a permanent niche as the lingua franca of data interchange and pipeline I/O. In 2026, three flat file formats dominate data engineering workflows: CSV, Parquet, and JSON Lines (JSON-L).CSV remains the most universally supported data exchange format precisely because it is the simplest. Every spreadsheet application, every database system, and every programming language can read and write CSV. It carries no schema, no data types beyond what the reading application infers, and no compression — but its simplicity is its strength for one-time data transfers and human-readable exports.
Parquet is a columnar binary format designed for analytical workloads at scale. Unlike CSV, Parquet stores each column's values contiguously, encodes data types explicitly, and applies compression per column using algorithms matched to the data distribution. A query engine reading a Parquet file can skip entire column groups that are not needed by the query, making Parquet far more efficient than CSV for large analytical datasets. Parquet is the storage format of choice for data lakes built on object storage systems like Amazon S3 and Google Cloud Storage.
JSON-L (JSON Lines) stores one JSON object per line, making it streamable and appendable without loading the entire file. It is the preferred format for log data, event streams, and machine learning training datasets, where records arrive continuously and the schema may vary between records. Flat files, in their modern forms, are not a relic — they are the connective tissue of the modern data stack.
The Hierarchical Database Model
The hierarchical database model, which emerged in the 1960s, imposed tree structure on data for the first time. Every record in a hierarchical database has exactly one parent, and a parent can have many children — forming a strict one-to-many hierarchy from a single root node down through all the data. IBM's Information Management System (IMS), originally developed for the Apollo program's manufacturing bill of materials, is the canonical hierarchical database and remains in production use at major financial institutions and government agencies today.
The hierarchical model solved the flat file's complete lack of structure, but introduced a rigidity of its own. Real-world data frequently involves many-to-many relationships — a student enrolled in multiple courses, a product sold by multiple suppliers — that a strict tree structure cannot represent without duplicating data. Navigating to a record required traversing the tree from the root, following a predefined path through parent-child links. Queries that did not follow the tree's structure were expensive or impossible. These limitations motivated the network model.
The hierarchical model solved the flat file's complete lack of structure, but introduced a rigidity of its own. Real-world data frequently involves many-to-many relationships — a student enrolled in multiple courses, a product sold by multiple suppliers — that a strict tree structure cannot represent without duplicating data. Navigating to a record required traversing the tree from the root, following a predefined path through parent-child links. Queries that did not follow the tree's structure were expensive or impossible. These limitations motivated the network model.
The Network Database Model
The network database model, standardized by the CODASYL committee in 1969, extended the hierarchical model by allowing records to have multiple parents. Where a hierarchical database is a tree, a network database is a general graph — records are connected by explicit pointer-based links called sets, and a single record can participate in multiple sets as both a parent and a child. This flexibility allowed many-to-many relationships to be represented directly in the database structure without data duplication.
Navigating a network database required procedural code that explicitly followed pointers from record to record. A program retrieving all orders placed by a specific customer in a given date range would start at the customer record, follow the pointer to the first order in the customer's order set, check the order date, follow the pointer to the next order, and repeat until all orders had been examined. There was no declarative query language; the navigation path was written explicitly in COBOL or another procedural language.
The model also handled complex, interconnected data naturally. Manufacturing bill-of-materials structures, telecommunications network topologies, and organizational reporting hierarchies all mapped cleanly onto network database schemas. These use cases drove adoption of network databases throughout the 1970s.
When the relational model offered declarative SQL queries that could answer arbitrary questions without schema restructuring, the network model's dominance ended quickly. However, the core insight of the network model — that relationships between entities are as important as the entities themselves, and deserve first-class representation in the data structure — survived and re-emerged in modern graph databases. Neo4j, Amazon Neptune, and Apache TinkerPop are direct intellectual descendants of the CODASYL network model, applying its graph structure with modern query languages (Cypher, Gremlin) and storage engines designed for the scale of contemporary workloads.
Core Concepts — Nodes, Edges, and Graph Structure
In the network model, the fundamental units are records (equivalent to rows in a relational table) and sets (the named relationships between record types). A set defines an owner record type and one or more member record types. An instance of a set connects one owner record to zero or more member records. Because a member record can participate in multiple sets with different owners, the overall structure forms a graph rather than a tree.Navigating a network database required procedural code that explicitly followed pointers from record to record. A program retrieving all orders placed by a specific customer in a given date range would start at the customer record, follow the pointer to the first order in the customer's order set, check the order date, follow the pointer to the next order, and repeat until all orders had been examined. There was no declarative query language; the navigation path was written explicitly in COBOL or another procedural language.
Strengths of the Network Model
The network model's primary strength was performance on relationship-traversal queries. Because relationships were stored as physical pointers between records, following a link from a customer to its orders required a single pointer dereference — essentially a direct memory address lookup — rather than a join operation across indexed columns. For applications where the query patterns were known in advance and relationships were dense, network databases could outperform relational databases on raw traversal speed.The model also handled complex, interconnected data naturally. Manufacturing bill-of-materials structures, telecommunications network topologies, and organizational reporting hierarchies all mapped cleanly onto network database schemas. These use cases drove adoption of network databases throughout the 1970s.
Historical Use Cases and Modern Descendants
Network databases powered critical infrastructure throughout the 1970s and into the 1980s: airline reservation systems, banking transaction processors, and telecommunications switching systems. The explicit pointer-based navigation that made network databases fast for known query patterns made them brittle for ad-hoc queries — adding a new query type often required restructuring the database schema and rewriting application code.When the relational model offered declarative SQL queries that could answer arbitrary questions without schema restructuring, the network model's dominance ended quickly. However, the core insight of the network model — that relationships between entities are as important as the entities themselves, and deserve first-class representation in the data structure — survived and re-emerged in modern graph databases. Neo4j, Amazon Neptune, and Apache TinkerPop are direct intellectual descendants of the CODASYL network model, applying its graph structure with modern query languages (Cypher, Gremlin) and storage engines designed for the scale of contemporary workloads.
The Relational Database Model
Edgar F. Codd's 1970 paper "A Relational Model of Data for Large Shared Data Banks" proposed a radical simplification: discard the physical pointer structures of hierarchical and network databases entirely, and represent all relationships through shared values in tables. A customer's orders are linked to the customer not by a pointer embedded in the database structure, but by the presence of a customer identifier column in the orders table that matches the primary key in the customers table. Any query that needs to connect these records can do so by specifying the matching condition in SQL — without knowing or caring about how the data is physically stored.
This declarative query model, combined with the mathematical rigor of relational algebra and the commercial accessibility of the table-and-column representation, made the relational model commercially dominant by the mid-1980s and globally dominant by the 1990s. The diagram shows relational databases reaching their peak adoption plateau around 2020 — not because they are declining, but because the ecosystem has matured to the point where relational databases are the assumed baseline for transactional data management, and new workloads are increasingly handled by the specialized models that have grown up alongside them.
This declarative query model, combined with the mathematical rigor of relational algebra and the commercial accessibility of the table-and-column representation, made the relational model commercially dominant by the mid-1980s and globally dominant by the 1990s. The diagram shows relational databases reaching their peak adoption plateau around 2020 — not because they are declining, but because the ecosystem has matured to the point where relational databases are the assumed baseline for transactional data management, and new workloads are increasingly handled by the specialized models that have grown up alongside them.
Object and Object-Relational Models
The object database model emerged in the 1980s alongside the rise of object-oriented programming languages. As developers built increasingly complex applications in C++ and later Java, they encountered the impedance mismatch — the friction between the object-oriented structure of application code and the table-and-row structure of relational databases. Object databases proposed eliminating this mismatch by storing data as programming objects directly, with inheritance, encapsulation, and method dispatch preserved in the database layer.
Object databases never achieved broad commercial adoption. The relational model's mathematical foundations, its SQL query standard, and its established ecosystem of tools and expertise proved too entrenched to displace. The response from the relational database community was the object-relational model — extending relational databases with user-defined types, array columns, inheritance hierarchies, and stored procedures, while preserving SQL compatibility and relational query semantics. PostgreSQL is the most significant object-relational database in production use today; its support for custom data types, JSON columns, array operators, and inheritance allows it to handle workloads that pure relational systems handle awkwardly, without abandoning the relational foundation.
Object databases never achieved broad commercial adoption. The relational model's mathematical foundations, its SQL query standard, and its established ecosystem of tools and expertise proved too entrenched to displace. The response from the relational database community was the object-relational model — extending relational databases with user-defined types, array columns, inheritance hierarchies, and stored procedures, while preserving SQL compatibility and relational query semantics. PostgreSQL is the most significant object-relational database in production use today; its support for custom data types, JSON columns, array operators, and inheritance allows it to handle workloads that pure relational systems handle awkwardly, without abandoning the relational foundation.
Cloud-Native Databases
The cloud-native database category, which took shape between 2010 and 2015, represents a architectural shift rather than a data model shift. Cloud-native databases are designed from the ground up to run in containerized, distributed environments — where the assumption is not a single powerful server but a fleet of commodity machines that can be provisioned and deprovisioned elastically in response to workload demand. Amazon Aurora, Google Cloud Spanner, CockroachDB, and PlanetScale exemplify this category.
The defining characteristics of cloud-native databases are elastic scalability (adding capacity without downtime), multi-region replication (data available close to users anywhere in the world), managed operations (the database vendor handles patching, backups, and failover), and consumption-based pricing (you pay for what you use rather than for a fixed server allocation). For SQL developers, cloud-native databases are largely transparent — you connect with the same tools, write the same SQL, and observe the same query semantics as you would with a traditional relational database. The differences are in operational behavior, not in the query interface.
The defining characteristics of cloud-native databases are elastic scalability (adding capacity without downtime), multi-region replication (data available close to users anywhere in the world), managed operations (the database vendor handles patching, backups, and failover), and consumption-based pricing (you pay for what you use rather than for a fixed server allocation). For SQL developers, cloud-native databases are largely transparent — you connect with the same tools, write the same SQL, and observe the same query semantics as you would with a traditional relational database. The differences are in operational behavior, not in the query interface.
NoSQL — Diverse Models for Diverse Workloads
The NoSQL category is not a single data model but a collection of data models united by one characteristic: they do not use SQL as their primary query interface and do not enforce the relational model's tabular structure. NoSQL systems emerged around 2009–2010 in response to workloads — primarily web-scale applications at companies like Google, Amazon, and Facebook — that required horizontal scalability and flexible schemas that the relational model handled poorly. The diagram categorizes NoSQL into four major subtypes: key-value, document, graph, and wide-column.
Key-Value Stores
Key-value stores are the simplest NoSQL model: every piece of data is stored as a value associated with a unique key. There is no schema, no column structure, and no query language — you retrieve data by providing its key, and you store data by providing a key and a value. Redis and Amazon DynamoDB are the most widely deployed key-value stores. Redis holds its data entirely in memory, making it extremely fast for caching, session management, and real-time leaderboards. DynamoDB is a fully managed key-value and document store optimized for single-digit millisecond response times at any scale.Document Databases
Document databases store data as self-describing documents — typically JSON or BSON objects — where each document can have a different structure. There is no requirement that all documents in a collection share the same fields. MongoDB is the most widely used document database; it allows you to store complex, nested data structures directly and query them using a rich expression language without defining a schema in advance. Document databases are well-suited for content management systems, user profiles, product catalogs, and any domain where entities have variable attributes that would require nullable columns or separate tables in a relational schema.Graph Databases
Graph databases store data as nodes and edges, where both nodes and edges can carry properties. Unlike the historical network model's physical pointer approach, modern graph databases store the graph structure in optimized index-free adjacency structures that allow constant-time traversal regardless of graph size. Neo4j is the most widely deployed graph database; its Cypher query language expresses graph traversal patterns declaratively in a way that SQL cannot match for relationship-centric queries. Graph databases are used for social network analysis, recommendation engines, fraud detection, and knowledge graphs — the same use cases that motivated the historical network model, now served with modern query languages and distributed storage.Wide-Column Stores
Wide-column stores organize data into tables with rows and columns, but allow different rows to have entirely different sets of columns — and allow the column set to be defined per-row at write time rather than at schema definition time. Apache Cassandra and HBase are the leading wide-column stores. Cassandra is optimized for write-heavy workloads with linear horizontal scalability; it is widely used for time-series data, IoT event streams, and messaging systems where write throughput and availability are more important than complex query flexibility. HBase, built on top of the Hadoop Distributed File System, provides random read/write access to very large datasets stored in HDFS — the bridge between the Hadoop batch processing ecosystem and interactive query workloads.NewSQL and HTAP — Bridging Transactions and Analytics
NewSQL databases emerged around 2020 to address a limitation that neither traditional relational databases nor NoSQL systems solved cleanly: the need to handle high-volume transactional workloads (OLTP — Online Transaction Processing) and complex analytical queries (OLAP — Online Analytical Processing) within the same system, with full ACID transaction guarantees and SQL compatibility. This combined capability is called HTAP — Hybrid Transactional/Analytical Processing.
CockroachDB distributes a PostgreSQL-compatible SQL interface across multiple nodes with automatic sharding and consensus-based replication, providing the horizontal scalability of NoSQL with the ACID guarantees and SQL query model of relational databases. Google Cloud Spanner achieves global consistency across geographic regions using TrueTime, Google's globally synchronized clock infrastructure, allowing it to provide serializable isolation across data centers on different continents. TiDB, an open-source HTAP database from PingCAP, combines a row-oriented transactional storage engine with a columnar analytical storage engine in a single system, routing queries to the appropriate engine based on their access pattern.
For SQL developers, HTAP systems mean that the same database can serve both the application's transactional queries (inserting orders, updating account balances, looking up customer records) and the business's analytical queries (calculating monthly revenue by region, identifying top customers by lifetime value) without the operational overhead of maintaining a separate data warehouse and ETL pipeline.
CockroachDB distributes a PostgreSQL-compatible SQL interface across multiple nodes with automatic sharding and consensus-based replication, providing the horizontal scalability of NoSQL with the ACID guarantees and SQL query model of relational databases. Google Cloud Spanner achieves global consistency across geographic regions using TrueTime, Google's globally synchronized clock infrastructure, allowing it to provide serializable isolation across data centers on different continents. TiDB, an open-source HTAP database from PingCAP, combines a row-oriented transactional storage engine with a columnar analytical storage engine in a single system, routing queries to the appropriate engine based on their access pattern.
For SQL developers, HTAP systems mean that the same database can serve both the application's transactional queries (inserting orders, updating account balances, looking up customer records) and the business's analytical queries (calculating monthly revenue by region, identifying top customers by lifetime value) without the operational overhead of maintaining a separate data warehouse and ETL pipeline.
AI-Integrated Databases and Knowledge Graphs
The rightmost column of the diagram — AI-Integrated / Knowledge Graph — represents the convergence endpoint that the diagonal trend line points toward. This category is not fully mature in 2026; it is actively being defined by the intersection of large language models, vector search, and semantic data representation.
Dedicated vector stores — Pinecone, Weaviate, and Qdrant — are purpose-built for approximate nearest-neighbor search at scale. PostgreSQL has added vector search capability through the pgvector extension, making it possible to store embeddings alongside structured relational data and query both in the same SQL statement. This hybrid approach — relational structure combined with semantic search — is a practical example of the next-gen convergence the diagram depicts.
The convergence of relational storage, graph traversal, vector search, and semantic reasoning within integrated platforms is the direction the data management industry is moving. For a SQL developer learning the relational model today, this trajectory is context worth understanding: the SQL you are learning is not a legacy technology heading toward obsolescence. It is the query foundation that every subsequent model has either adopted directly (NewSQL), extended (object-relational), or built compatibility layers for (NoSQL systems with SQL interfaces). The relational model sits at the center of the data ecosystem — not at its edge.
Vector Stores and Semantic Layers
Vector stores are databases optimized for storing and searching high-dimensional numerical vectors — the embedding representations that machine learning models produce when they encode text, images, audio, or structured data into a latent space. When a large language model processes a sentence, it produces a vector of hundreds or thousands of floating-point numbers that encode the semantic meaning of that sentence. Finding the most semantically similar sentences in a large corpus means finding the vectors nearest to a query vector in that high-dimensional space — a nearest-neighbor search problem that traditional relational indexes handle poorly.Dedicated vector stores — Pinecone, Weaviate, and Qdrant — are purpose-built for approximate nearest-neighbor search at scale. PostgreSQL has added vector search capability through the pgvector extension, making it possible to store embeddings alongside structured relational data and query both in the same SQL statement. This hybrid approach — relational structure combined with semantic search — is a practical example of the next-gen convergence the diagram depicts.
The Convergence Endpoint
Knowledge graphs combine the graph database model with formal ontology — structured vocabularies that define the meaning of nodes and edges in terms that both humans and machines can reason about. The semantic web technologies (RDF, SPARQL, OWL) that underpin knowledge graphs have been developed since the early 2000s, but they have gained new relevance as large language models create demand for structured factual knowledge that can ground AI-generated responses in verified data. Enterprise knowledge graphs at companies like Google, Microsoft, and LinkedIn connect billions of entities and relationships, powering search results, recommendation systems, and AI assistants that need to answer questions about the real world.The convergence of relational storage, graph traversal, vector search, and semantic reasoning within integrated platforms is the direction the data management industry is moving. For a SQL developer learning the relational model today, this trajectory is context worth understanding: the SQL you are learning is not a legacy technology heading toward obsolescence. It is the query foundation that every subsequent model has either adopted directly (NewSQL), extended (object-relational), or built compatibility layers for (NoSQL systems with SQL interfaces). The relational model sits at the center of the data ecosystem — not at its edge.
Database Flat File - Quiz
Take a brief quiz to make sure you understand these flat file and relational database concepts.
Database Flat File - Quiz
In the next lesson, we will use an analogy to drive the relational database point home.
Database Flat File - Quiz
In the next lesson, we will use an analogy to drive the relational database point home.
[1]file system database model: A DBMS creates and defines the constraints for a database. A file system allows access to a single file at a time and addresses each file individually. Because of this, functions such as redundancy are performed on an individual level, not by the file system itself.
[2]Btrieve: The original developer, Pervasive Software, integrated Btrieve technology into their flagship product, Pervasive.SQL. This modern database retains some elements of Btrieve but offers additional features and functionality.