| Lesson 5 | Normalization |
| Objective | Gain an overview of normalization. |
Database Normalization (1NF, 2NF, 3NF, and Projection-Join Overview)
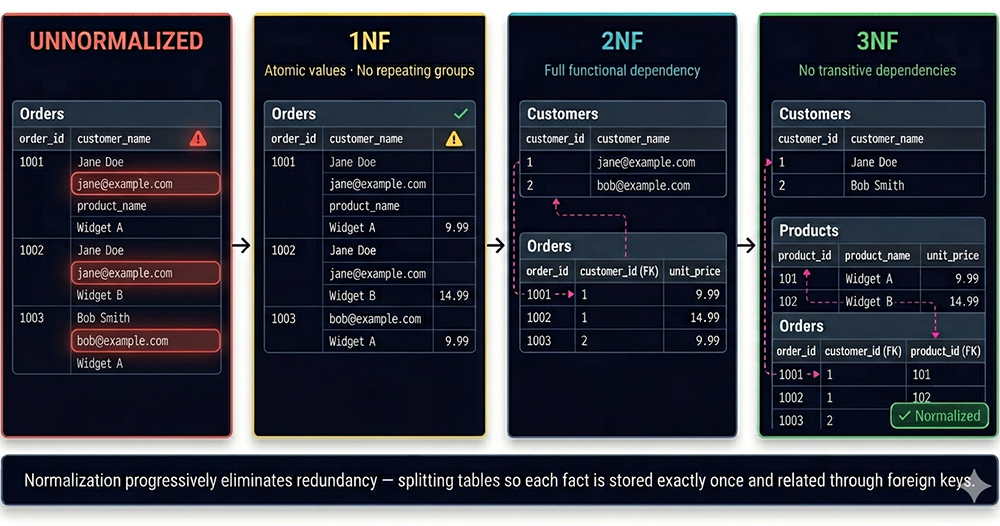
The diagram below shows the complete progression in a single image: an unnormalized Orders table on the left, moving through First, Second, and Third Normal Form as redundancy is progressively eliminated and each fact is isolated into exactly one place.
What Is Database Normalization?
Edgar F. Codd, the inventor of the relational model, introduced the concept of normalization and the First Normal Form (1NF) in 1970. Codd defined the Second Normal Form (2NF) and Third Normal Form (3NF) in 1971. Codd and Raymond F. Boyce together defined the Boyce-Codd Normal Form (BCNF) in 1974. Informally, a relational database table is considered normalized when it reaches the Third Normal Form. Most 3NF tables are free of the insertion, update, and deletion anomalies that make unnormalized schemas unreliable.
Two Approaches to Normalization
There are two practical ways to approach normalization when designing a database schema.
The first is to work from an Entity-Relationship (ER) diagram. If the diagram is drawn correctly, straightforward rules exist for translating it into table definitions that avoid most relational design problems. The drawback is that it can be difficult to verify whether your ER diagram itself is correct — a flawed diagram produces a flawed schema regardless of how faithfully you follow the translation rules.
The second approach is to apply the theoretical concepts of normalization directly to your data. This requires a deeper understanding of functional dependencies and the normal form rules, but it often produces a more rigorous design because it forces you to reason about the data itself rather than the diagram representing it.
In practice, the most reliable approach combines both. Start with an ER diagram to establish the broad structure, then validate each resulting table against the theoretical normalization rules and revise where necessary. The diagram provides the high-level view; the theory provides the correctness check.
Why Normalization Matters for SQL Developers
As a SQL developer, you will spend most of your time writing queries against schemas that already exist. Understanding normalization helps you in two ways. First, it helps you read and reason about a schema quickly — a normalized schema has a predictable structure where each table has a clear, single subject and foreign keys make relationships explicit. Second, it helps you diagnose query problems: many performance issues and unexpected query results trace back to unnormalized schema decisions that cause data duplication, ambiguous joins, or missing rows.
A normalized schema also produces simpler SQL. When each fact lives in exactly one table, your SELECT statements are straightforward — join the tables that hold the data you need, filter by the conditions you care about, and the result is correct. An unnormalized schema forces you to work around its redundancies with GROUP BY clauses, DISTINCT keywords, and subqueries that compensate for data that should never have been duplicated in the first place.
Relational Database Design
Requirements, Constraints, and Design Independence
Independence from physical implementation means that your table structure should not be designed around how the database engine happens to store data on disk. The engine's job is to store and retrieve data efficiently regardless of the physical layout; your job is to design a logical structure that correctly represents the domain. A design that is entangled with physical storage assumptions will break or become inefficient every time the storage engine changes.Independence from specific applications means that your schema should be able to answer questions that were not anticipated at design time. It is generally not the case that all uses of a database are known when the schema is first defined. A schema designed to serve only the application queries that exist today will become a liability as new reporting requirements, new features, and new integrations emerge. A normalized schema, precisely because it stores each fact exactly once and makes relationships explicit, is far more adaptable to unanticipated queries than a denormalized schema optimized for a specific set of known access patterns.
Business Rules and the Entity-Relationship Model
A precise and complete requirements statement for a database design typically takes the form of two inputs: a set of
business rules and an
entity relationship model.
Business rules describe the constraints and behaviors of the domain in plain language: "Each order belongs to exactly one customer." "A customer may have zero or more orders." "Each order line references exactly one product." These rules define the cardinality and participation constraints that will become foreign key definitions and NOT NULL constraints in the schema.
The entity-relationship model formalizes these rules into a diagram showing entities (which become tables), attributes (which become columns), and relationships (which become foreign keys). Together, business rules and the ER model provide the raw material from which a normalized schema is constructed.
When Requirements Are Clear, Design Choices Remain
Even when the requirements are fully specified, there are usually multiple valid schema designs that satisfy them. Some will be more normalized than others. Some will optimize for write performance at the cost of read complexity. Some will be simpler to implement but harder to extend. Relational database theory has very little science to offer regarding these higher-level design choices — what little formal guidance it provides is almost entirely within the domain of projection-join normalization, which defines precise rules for decomposing tables to eliminate specific classes of redundancy.
The Three Anomalies Normalization Prevents
Consider a table that stores order_id, customer_name, customer_email, product_name, and unit_price in a single flat structure — exactly the structure shown in the diagram's red UNNORMALIZED panel. Jane Doe's email address appears in every row for every order she has ever placed. Widget A's price of $9.99 appears in every row for every order that included Widget A.
Insertion Anomalies
An insertion anomaly occurs when you cannot add a valid piece of information to the database without also adding unrelated information that you do not yet have. In the unnormalized Orders table, you cannot record a new customer — say, Alice Brown — until Alice places her first order. There is no way to store Alice's name and email address without an order_id to anchor the row. The customer exists in the real world, but the schema has no place for her until she generates a transaction. This is an insertion anomaly: the structure of the table prevents you from recording legitimate data.Update Anomalies
An update anomaly occurs when changing a single real-world fact requires updating multiple rows, and any partial update leaves the database in an inconsistent state. In the unnormalized Orders table, if Jane Doe changes her email address, every row associated with Jane must be updated simultaneously. If the UPDATE statement runs successfully on some rows but fails partway through — due to a timeout, a transaction rollback, or an application bug — the database will contain two different email addresses for the same customer. The data is now inconsistent, and any query that relies on Jane's email will produce different results depending on which rows it encounters first.Deletion Anomalies
A deletion anomaly occurs when deleting one piece of information unintentionally destroys other information that should be preserved. In the unnormalized Orders table, if order 1003 is the only order that Bob Smith has ever placed, deleting that order also deletes all knowledge that Bob Smith exists as a customer — his name and email address disappear from the database entirely. The business may need to retain customer records for compliance, marketing, or history purposes, but the schema makes it impossible to delete an order without potentially losing customer data.All three anomalies share a common root cause: the table is storing facts about multiple distinct entities — customers, products, and orders — in the same rows. Normalization eliminates these anomalies by separating those entities into their own tables, so that each fact about a customer lives only in the Customers table, each fact about a product lives only in the Products table, and the Orders table records only the transaction itself.
Functional Dependency — The Theory Behind Normalization
In the unnormalized Orders table, customer_email is functionally dependent on customer_name — knowing the customer's name tells you their email address. unit_price is functionally dependent on product_name — knowing the product name tells you its price. But neither customer_email nor unit_price is functionally dependent on order_id — the order identifier alone does not tell you the customer's email or the product's price without also knowing the customer name or product name. This mismatch between what determines what is precisely what the normal forms are designed to detect and eliminate.
Understanding functional dependencies is the key to applying 2NF and 3NF correctly. 2NF requires that every non-key attribute be fully functionally dependent on the entire primary key, not just part of it. 3NF requires that every non-key attribute be directly dependent on the primary key, with no transitive dependencies passing through other non-key attributes. Both rules are direct applications of functional dependency analysis to table structure.
The Normal Forms — An Overview
First Normal Form (1NF) — Codd, 1970
A table is in First Normal Form when every column contains atomic values — values that cannot be further decomposed — and there are no repeating groups of columns. A cell that contains a comma-separated list of values ("Widget A, Widget B, Widget C") violates 1NF because those values are not atomic. A table that stores multiple phone numbers by creating phone_number_1, phone_number_2, and phone_number_3 columns violates 1NF because those columns are a repeating group.The 1NF panel in the diagram shows the Orders table with each cell containing a single value and a checkmark confirming atomicity. The warning indicator remains because 1NF alone does not eliminate the redundancy of repeated customer emails and product prices — it only ensures that each individual cell is atomic. 1NF is the entry requirement for applying any further normalization.
Second Normal Form (2NF) — Codd, 1971
A table is in Second Normal Form when it is in 1NF and every non-key attribute is fully functionally dependent on the entire primary key. 2NF violations only occur in tables with composite primary keys — keys made up of more than one column. If a non-key attribute depends on only part of the composite key rather than the whole key, it belongs in a separate table.The 2NF panel in the diagram shows the split into a Customers table and an Orders table. Customer email now lives in the Customers table, where it is fully dependent on customer_id — its natural primary key. The Orders table retains order_id as its primary key and references Customers via a customer_id foreign key. The dashed arrow between them represents the relationship that replaced the embedded, redundant email address.
Third Normal Form (3NF) — Codd, 1971
A table is in Third Normal Form when it is in 2NF and no non-key attribute is transitively dependent on the primary key through another non-key attribute. A transitive dependency exists when A → B and B → C, meaning C depends on A only indirectly, through B. In the Orders table, order_id → product_name and product_name → unit_price, so unit_price is transitively dependent on order_id through product_name. The price belongs to the product, not to the order.The 3NF panel in the diagram shows the further split into three tables: Customers, Products, and Orders. unit_price now lives in the Products table, where it is directly dependent on product_id. The Orders table becomes a pure transaction record — it stores only order_id, customer_id (FK), and product_id (FK). The "✓ Normalized" badge in the diagram's 3NF panel marks the completion of the standard normalization process.
Boyce-Codd Normal Form (BCNF) — Codd and Boyce, 1974
Boyce-Codd Normal Form is a slightly stronger version of 3NF that addresses a narrow class of anomaly that can remain in 3NF tables when a table has multiple overlapping candidate keys. BCNF requires that for every non-trivial functional dependency A → B, A must be a superkey — a column or combination of columns that uniquely identifies each row. Most tables that satisfy 3NF also satisfy BCNF; the distinction matters only in specific multi-key scenarios that arise in complex schemas.Why 3NF Is the Practical Target
Higher normal forms exist beyond BCNF — Fourth Normal Form (4NF) addresses multi-valued dependencies, and Fifth Normal Form (5NF) addresses join dependencies — but they are rarely pursued in practice. The anomalies they address are uncommon in typical business data models, and the schema decompositions they require can produce tables so fine-grained that query complexity increases significantly without a commensurate benefit in data integrity. The industry consensus is that 3NF is the right stopping point for most schemas: it eliminates the three anomalies that cause real-world data corruption problems, while keeping the schema comprehensible and the SQL reasonably straightforward.Projection-Join Normalization
Projections as Vertical Table Subsets
A projection is a unary relational operation that returns a vertical subset of a table — a new table containing only the columns specified in the projection, with duplicate rows removed. When you normalize the Orders table into Customers, Products, and Orders, you are creating projections of the original table: the Customers projection contains customer_id, customer_name, and customer_email; the Products projection contains product_id, product_name, and unit_price; the Orders projection contains order_id, customer_id, and product_id.Each projection contains only the columns that are functionally related to its primary key. This is the operational definition of normalization: a normalized table is one where every column is a projection of a meaningful, well-defined entity.
Joins as the Reconstruction Operation
A join is a binary relational operation that combines two tables into one based on a matching condition between their columns. When you write a SQL JOIN between the Orders table and the Customers table on customer_id, you are performing the reconstruction operation that projection-join normalization guarantees is safe. The join retrieves exactly the data that would have been stored redundantly in the unnormalized table — but it retrieves it dynamically, from a single authoritative source, without any risk of inconsistency.The Lossless Join Property
A decomposition is lossless when joining the projected tables back together produces exactly the original table — no rows are lost, no spurious rows are introduced. This property is what makes normalization safe: you are not discarding data when you decompose a table, you are reorganizing it. The lossless join guarantee ensures that every query result you could have produced from the original unnormalized table can still be produced from the normalized tables, by joining them on their foreign key relationships.A decomposition that is not lossless — where the join produces extra rows that were not in the original table — is called a lossy decomposition, and it indicates a design error. The functional dependency analysis that underlies normalization is precisely the tool for ensuring that decompositions are lossless.
Normalization Is a Rule — And Rules Can Be Broken
When Denormalization Makes Sense
Denormalization is the intentional violation of normalization rules in order to achieve a specific performance or simplicity goal. The most common motivation for denormalization is read performance: a normalized schema requires joins, and joins have a cost. For tables that are queried millions of times per second and rarely updated, storing redundant data to avoid a join can be a justified trade-off.Data warehouses and analytical systems are the canonical example of intentional denormalization. A data warehouse is typically organized into star schemas or snowflake schemas — structures that deliberately denormalize dimension data into wide, flat tables to minimize the number of joins required for reporting queries. This is acceptable because data warehouse tables are loaded in bulk on a scheduled basis, not updated row-by-row by application transactions, so the update and deletion anomalies that normalization prevents are not a concern.
In transactional systems — the kind you are learning to work with in this course — normalization should be the default. The anomaly risks are real, the performance cost of joins is manageable with proper indexing, and the long-term maintainability of a normalized schema is significantly higher than that of a denormalized one.
Using Judgment in Real-World Database Design
The practical skill that normalization teaches is not the mechanical application of the 1NF, 2NF, and 3NF rules. It is the habit of asking, for every column in every table: does this value belong here? Is it describing this table's primary entity, or is it describing something else that has its own identity and should live in its own table? When you ask that question consistently, you will catch most normalization violations before they become anomaly problems — regardless of whether you can formally name the normal form they violate.Normalization Methodology — Two Goals
The first goal is eliminating redundant data. Redundancy occurs when the same fact is stored in more than one place. Jane Doe's email address stored in fifty order rows is redundant — the fact that Jane's email is jane@example.com is a single piece of information about Jane, and it should be stored in exactly one row in a Customers table. Eliminating redundancy reduces storage consumption, but more importantly, it eliminates the possibility of the update anomaly: if Jane's email changes, exactly one row must be updated, and the change is immediately consistent everywhere the email is referenced.
The second goal is ensuring that data dependencies make sense — storing only related data in a table. This means that each table should describe exactly one kind of thing: one entity, one relationship, one concept. A table that describes both customer contact information and order transaction history and product pricing is describing three different things, and its columns have dependencies that cross entity boundaries. Separating those concerns into distinct tables produces a schema where every column is clearly in the right place, every relationship is explicit, and every query is straightforward to write.
Both goals reduce the space a database consumes and ensure that data is stored logically and consistently. The next lesson examines a concrete data table example that demonstrates these principles in practice.