Flat File vs. Relational Database (Key Differences and SQL Advantages)
The Same Data, Two Different Approaches
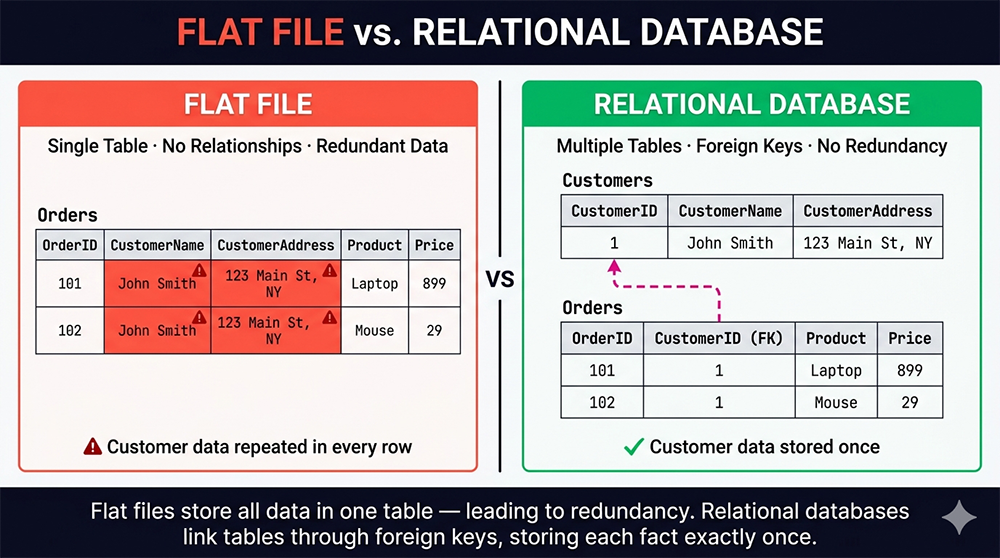
The Flat File Version — One Table, All Data
In a flat file, all information about every entity — the customer, the product, and the transaction — lives in a single table. Every row must carry the full context for that record, even when that context is identical to another row:| OrderID | CustomerName | CustomerAddress | Product | Price |
|---|---|---|---|---|
| 101 | John Smith | 123 Main St, NY | Laptop | $899 |
| 102 | John Smith | 123 Main St, NY | Mouse | $29 |
John Smith's name and address appear twice — once for each order. In a two-row example this looks harmless. In a real system where John Smith has placed fifty orders over three years, his name and address appear fifty times. If John moves, fifty rows must be updated simultaneously or the database becomes inconsistent. If his name is misspelled in one row during a data entry error, queries that search by name will return different results depending on which rows they encounter. These are the update anomaly and the data inconsistency risk introduced in lesson 5 — visible here in their simplest form.
The Relational Version — Two Tables, One Source of Truth
The relational approach separates the customer data from the order data, storing each in its own table with its own primary key:
Customers Table:
| CustomerID | CustomerName | CustomerAddress |
|---|---|---|
| 1 | John Smith | 123 Main St, NY |
Orders Table:
| OrderID | CustomerID (FK) | Product | Price |
|---|---|---|---|
| 101 | 1 | Laptop | $899 |
| 102 | 1 | Mouse | $29 |
John Smith's name and address now appear in exactly one row in the Customers table. The Orders table stores only the CustomerID foreign key — the integer 1 — to reference that customer. If John moves, one UPDATE to one row in the Customers table corrects his address everywhere, instantly and automatically. If the database adds a third order for John, only the Orders table gains a new row; the Customers table is unchanged.
What the JOIN Produces
The relational structure retrieves the same combined view as the flat file — without storing any redundant data — through a JOIN query:
SELECT
o.OrderID,
c.CustomerName,
c.CustomerAddress,
o.Product,
o.Price
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
ORDER BY o.OrderID;For any dataset beyond trivial size, the relational approach wins: the JOIN cost is measurable in milliseconds for indexed tables, while the redundancy cost compounds with every inserted row, every address change, and every data quality audit.
Characteristics of a Flat File Database
Single Table Structure
A flat file database stores all data in a single two-dimensional structure — rows and columns — with no separation between entity types. Every row represents one record, and every column represents one field that applies to every record. This works adequately when the data genuinely describes a single entity with no relationships to other entities. A simple contact list — name, phone number, email — is a legitimate flat file use case: each row describes one person, no row needs to reference another row, and the structure is complete.
The single-table structure breaks down the moment the data describes multiple entities that have relationships to each other. Customers who place orders, employees who belong to departments, students who enroll in courses — all of these involve relationships, and the flat file has no mechanism for representing relationships other than duplicating the related data into every row that needs it.
Plain Text Storage — CSV, TXT, and Fixed-Width Formats
In CSV and TSV files, fields are delimited by a separator character — a comma or a tab — and records are separated by newline characters. The delimiter approach requires careful handling of fields that contain the delimiter character itself — a customer address containing a comma must be quoted or escaped to prevent the parser from treating the comma as a field separator. This is called delimiter collision, and it is a practical source of data corruption in flat file systems.
Fixed-width format avoids delimiter collision by assigning each field a predetermined byte length. The customer name occupies bytes 1–40, the address occupies bytes 41–100, and so on. A name shorter than 40 characters is padded with spaces; a name longer than 40 characters is truncated. Fixed-width files are faster to parse than delimited files because each field's location is known in advance without scanning for a delimiter character — but they are inflexible when field lengths need to change and wasteful of storage when most values are shorter than their maximum length.
Well-known examples of flat files in active use on Unix-like operating systems include `/etc/passwd` — which stores user account information one record per line — and `/etc/group`, which stores group membership. These files have remained in flat file format for decades because their content genuinely describes simple, non-relational lists with no join requirements.
No Relationships Between Data
The defining characteristic of a flat file database is the absence of any mechanism for defining or enforcing relationships between records. There are no primary key constraints, no foreign key references, and no referential integrity enforcement. Two records can contain contradictory information about the same real-world entity — different spellings of the same customer name, different addresses for the same person — and the flat file system has no way to detect or prevent the contradiction.
Any relationship between data sets must be managed entirely by application code. If a program needs to find all orders for a given customer in a flat file system, it must open the orders file, read through every record sequentially, compare the customer name field to the target name, and collect the matching records. There is no JOIN operation, no indexed lookup, and no engine to optimize the search. The application programmer implements the relationship logic from scratch for every query that needs it.
Limited Data Management and Querying
Flat file databases have no built-in query language. SQL — the declarative query model that allows a developer to describe what data they want without specifying how to retrieve it — does not apply to a flat file. Every data retrieval operation requires procedural code that opens the file, reads records, applies filters, and closes the file. Every data modification requires reading the entire file into memory, making the change, and writing the entire file back to disk.
This architecture also provides no built-in security model. There is no concept of a database user with defined permissions — any process with file system access to the flat file can read or modify its entire contents. Data integrity constraints — NOT NULL, UNIQUE, CHECK — do not exist. The flat file accepts any value in any field without validation.
File Access Methods — Sequential and Direct
Flat files support two physical access methods: sequential access and direct access. Sequential access reads records one at a time from the beginning of the file until the target record is found or the end of the file is reached. For a file with one million records, finding the last record requires reading all one million records. Direct access uses a record number or byte offset to jump to a specific record's location without reading preceding records — but this requires knowing the record's position in advance, which is only practical for fixed-width files where positions are predictable.
Neither access method provides anything comparable to a database index. A relational database index allows the engine to locate rows matching a specific column value in O(log n) time regardless of table size. A flat file sequential scan is O(n) — its cost grows linearly with the number of records. For small files the difference is imperceptible; for files with hundreds of thousands of records, the difference is the distinction between a query that returns in milliseconds and one that takes minutes.
Flat Files in 2026 — Still Relevant, Different Role
CSV remains the universal data exchange format because every system can read and write it. When a relational database needs to export data to a reporting tool, a spreadsheet, or another database system, CSV is the lowest common denominator that requires no specialized reader. It carries no schema, no data types, and no compression — but its simplicity is its universal currency.
Parquet is a columnar binary format used extensively in data lakes built on cloud object storage. Unlike CSV, Parquet stores column values contiguously, encodes data types explicitly, and applies per-column compression. Analytical query engines like Apache Spark and Amazon Athena can read only the columns they need from a Parquet file without reading the entire file — an optimization impossible with CSV.
JSON Lines stores one JSON object per line, making it streamable and appendable without loading the entire file. It is the standard format for log data, event streams, and machine learning training datasets where records arrive continuously and the schema may vary between records.
The distinction between these modern flat file formats and the relational database they feed into is the same distinction that has always existed: flat files are simple, portable, and schema-free data containers; relational databases are structured, queryable, integrity-enforced data stores. The two coexist because they serve different purposes in the data stack — flat files move data between systems, relational databases manage data within systems.
Characteristics of a Relational Database
Multiple Related Tables
A relational database organizes data into multiple tables, each representing a single entity type with its own primary key. Tables are connected through shared key values — a foreign key in one table references the primary key in another. This separation of entities into their own tables is normalization: the process of ensuring that each fact is stored exactly once and that every column in a table depends directly on that table's primary key.
Primary Keys and Foreign Keys
A primary key is a column or combination of columns that uniquely identifies each row in a table. No two rows in the same table can share a primary key value, and a primary key column cannot contain NULL. Every table in a well-designed relational database has a primary key.A foreign key is a column in one table that contains the primary key value of a row in another table, establishing a reference between the two records. The database engine enforces referential integrity on foreign key relationships: a foreign key value must match an existing primary key value in the referenced table, and primary key rows cannot be deleted while foreign key rows reference them — unless a CASCADE option is specified.
Together, primary keys and foreign keys replace the flat file's data duplication with a system of references. Instead of storing John Smith's address in every order row, the Orders table stores the integer 1 — a reference to the one Customers row where John Smith's address lives.
SQL — The Query Language of Relational Databases
SQL (Structured Query Language) is the declarative query interface that defines what distinguishes a relational database from any other data storage system. With SQL, a developer states what data they want — the columns to retrieve, the tables to query, the conditions to filter on, the tables to join — and the database engine determines how to retrieve it efficiently. The engine's query planner evaluates indexes, table statistics, and available join algorithms to produce the most efficient execution plan for the stated query.
This declarative model means that improvements to the database engine's query optimizer benefit all existing queries automatically. A query written in 2010 against a table with one million rows may execute significantly faster in 2026 against the same table with ten million rows, not because the query changed but because the engine's optimization capabilities improved. No equivalent mechanism exists for flat file access code — each program must implement its own optimization logic.
Data Integrity Enforcement
Relational databases enforce data integrity through a system of constraints defined at the schema level. NOT NULL constraints prevent columns from accepting missing values. UNIQUE constraints prevent duplicate values in a column. CHECK constraints validate that column values satisfy a business rule. PRIMARY KEY constraints enforce row uniqueness. FOREIGN KEY constraints enforce referential integrity between tables.
These constraints are enforced by the database engine on every INSERT, UPDATE, and DELETE operation — regardless of which application submitted the statement. Application code does not need to implement validation logic for constraints that the database enforces. A flat file system has none of these guarantees; data quality depends entirely on the application code that writes to the file.
Normalization as the Design Discipline
Normalization — covered in lessons 5 through 8 of this module — is the design process that produces a relational schema where every table has a clear single subject, every column depends directly on that table's primary key, and every relationship between entities is represented through foreign keys rather than duplicated data. A normalized schema is the direct application of the relational model's principles to a specific data domain.
The Customer Orders table from lessons 6 and 7 is the canonical example: the unnormalized flat structure was decomposed into Customers, Items, and Orders tables — each with its own primary key, each storing only the facts that belong to its entity, and each connected to the others through foreign key references. That decomposition is normalization producing a relational schema from flat data.
Key Differences — Flat File vs. Relational Database
| Feature | Flat File | Relational Database |
|---|---|---|
| Structure | Single table / file | Multiple related tables |
| Data Redundancy | High — data duplicated across rows | Low — normalized, each fact stored once |
| Relationships | None — no mechanism for linking records | Yes — primary keys and foreign keys |
| Data Integrity | Poor — no constraints, easy inconsistencies | High — enforced by database constraints |
| Querying | Limited — procedural code, sequential scan | Powerful — SQL with joins, indexes, optimization |
| Scalability | Poor — performance degrades linearly with size | Excellent — indexed access, distributed options |
| Complexity | Very simple to create and understand | More complex to design; requires schema planning |
| Best For | Small, simple, single-entity data; interchange | Medium to large applications with relationships |
| Examples | CSV, TSV, /etc/passwd, Excel, Parquet, JSON-L | MySQL, PostgreSQL, SQL Server, Oracle, SQLite |
When to Use Each
Flat Files Are Best For...
Flat files remain the right choice when the data is simple, the volume is modest, and relationships between entities are not required. A configuration file that stores application settings is a legitimate flat file — each key-value pair is independent, no joins are needed, and the simplicity of the format makes it human-readable and easy to edit in any text editor. Log files that record timestamped events are another appropriate flat file use case: records are appended sequentially, no record references another, and the primary operation is bulk reading rather than selective querying.Data interchange is where flat files remain indispensable in 2026. When two systems need to exchange data — a relational database exporting to a reporting tool, a data pipeline moving records between cloud services, a machine learning training set being assembled from multiple sources — CSV, Parquet, and JSON-L are the standard interchange formats precisely because they require no specialized reader and no shared schema agreement beyond the column headers.
Relational Databases Are Best For...
Relational databases are the right choice whenever the data involves multiple entity types with relationships between them, whenever multiple users or applications need to access and modify the data concurrently, or whenever data integrity and consistency must be guaranteed rather than trusted to application code.Any application that stores customers, orders, products, employees, invoices, schedules, or any other domain where one entity references another is a relational database application. The SQL you are learning in this course is the query language for these systems — the tool that lets you express what data you need and let the database engine retrieve it efficiently, correctly, and consistently, from a schema designed using the normalization principles this module has covered.