| Lesson 4 | SQL Standards |
| Objective | Discuss the evolution of SQL from SQL:2003 to SQL:2023 |
SQL Standards SQL:2003 to SQL:2023
SQL became the dominant database language because it gives you a portable, declarative way to retrieve and modify data stored in a relational database. Very early on, vendors recognized that SQL needed a standard so developers could carry core skills across products and so tools could interoperate with multiple database engines.
That is the role of the ANSI/ISO SQL standard: define the language concepts, grammar, and baseline behaviors. Vendors then implement a subset of the standard and often add extensions (features outside the standard) to differentiate their platforms. This is why you can learn “core SQL” once, but still need to understand dialect differences (covered in the next lesson).
This lesson focuses on how SQL evolved from SQL:2003 through SQL:2023. The goal is not to memorize version numbers, but to understand the major capability areas that matured in modern SQL.
Relational theory connection
In relational theory, a relation is a mathematical set of tuples (rows) described by attributes (columns). Query languages based on the relational model are designed to be closed: a query takes relations as input and produces a relation as output. This closure property is what makes SQL composable: you can nest queries, join results, and treat derived tables like base tables.
SQL is not a perfect, pure expression of the relational model (for example, SQL allows duplicates unless you remove them, and SQL uses NULL), but its declarative and set-based nature still aligns strongly with the intent of relational algebra and relational calculus: specify the result set, then let the database compute an efficient plan.
Short timeline through SQL:2003
Before we focus on SQL:2003 onward, it helps to see the early milestones that established the core language. Examine the following diagram and table for a compact view of early standard evolution.
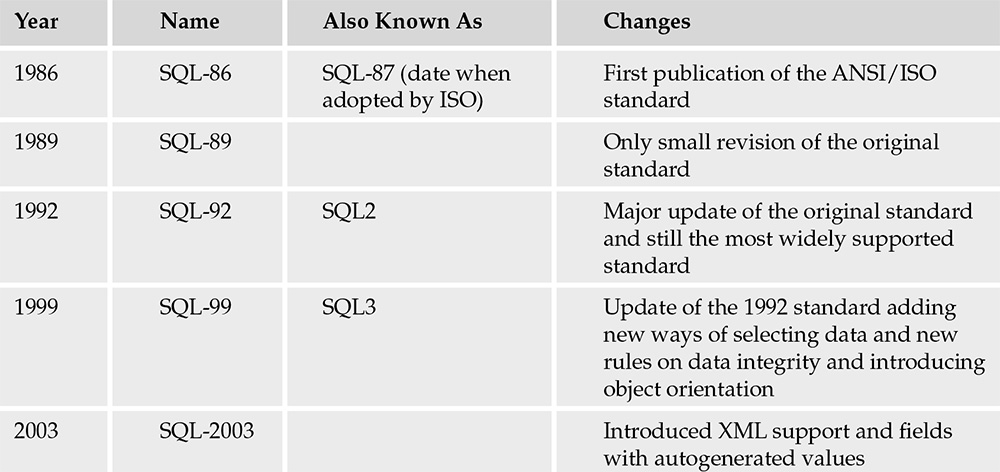
| Year | Name | Also Known As | Changes |
|---|---|---|---|
| 1986 | SQL-86 | SQL-87 (ISO adoption) | First publication of the ANSI/ISO SQL standard |
| 1989 | SQL-89 | Small revision of the original standard | |
| 1992 | SQL-92 | SQL2 | Major expansion: joins, constraints, richer data types, metadata views, more complete DDL |
| 1999 | SQL:1999 | SQL3 | Expanded integrity and programmability concepts; groundwork for richer query capabilities |
| 2003 | SQL:2003 | Major modernization era: stronger query expressiveness and new feature areas |
What “SQL standard” means in real systems
The SQL standard is large and modular. Real database engines do not implement “all of SQL.” Instead, they implement a practical subset plus vendor extensions. This creates two important realities:
- Core SQL stays portable: SELECT/FROM/WHERE, joins, grouping, subqueries, basic constraints, and transaction concepts transfer well across platforms.
- Advanced features vary: analytic functions, JSON, graph queries, temporal features, and procedural extensions may exist everywhere, but the syntax and completeness vary by vendor.
A good learning strategy is to master the core patterns first, then learn platform-specific features once you know which engine you are targeting. That is why the next lesson discusses SQL dialect variations.
SQL:2003 to SQL:2023 key developments
From SQL:2003 onward, SQL evolved to support new application patterns (analytics, web data formats, time-oriented auditing, and richer schema behavior) while keeping the core relational query model intact. The most useful way to understand these changes is by capability area.
1) Analytic querying and “report-style” SQL
Modern SQL grew stronger at answering questions like “top N per group,” “running totals,” “rank within category,” and "moving averages." These patterns are common in reporting and analytics, and they are far more efficient when expressed as set-based SQL than when coded as loops in an application.
-- Example analytic pattern (rank within a category)
SELECT
dept_id,
emp_id,
salary,
ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS salary_rank
FROM employees;2) Better composition and readability
As SQL grew, query readability became a first-class concern. Modern SQL encourages composing queries in layers: a query can be written as a series of named steps, then reused as derived relations. This fits the relational idea of closure: each step produces a relation that can feed another step.
-- Example compositional pattern using a CTE
WITH high_value_orders AS (
SELECT order_id, customer_id, total_amount
FROM orders
WHERE total_amount > 10000
)
SELECT customer_id, COUNT(*) AS order_count
FROM high_value_orders
GROUP BY customer_id;3) Time-aware data modeling
Modern systems increasingly need to answer time-based questions: “What did we believe to be true last month?” and “What changed, when, and why?” SQL standards and database platforms evolved features and patterns for temporal data and auditing. Even when a platform does not implement the full temporal feature set, the concept influences how modern schemas are designed.
4) Semi-structured data without abandoning relational design
As web and event data became common, SQL evolved to work with semi-structured formats (especially JSON) while still supporting relational querying, constraints, and joins. This is a major reason SQL stayed central even as “NoSQL” systems emerged: organizations still need reliable querying, consistency, and integration with relational data.
Neighboring topic: semi-structured storage can help with flexibility, but relational modeling is still the best tool for enforcing correctness, reducing redundancy, and supporting long-lived operational systems.
5) Richer schema behavior and safer change
Schema evolution and application delivery became faster. SQL standards and vendor tooling improved the ability to change schema, enforce integrity rules, and introspect metadata. The standard’s metadata views are often associated with INFORMATION_SCHEMA concepts, though each vendor exposes metadata in its own way.
-- Standard-style metadata idea (availability varies by vendor)
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_type = 'BASE TABLE';6) Ongoing standardization through SQL:2023
By SQL:2023, SQL is no longer “just” a query language for tables. It is a standardized family of features that supports: set-based querying, strong integrity rules, modern analytics, and integration with newer data representations. The details are extensive, but the big lesson is simple: SQL continues to evolve while preserving the core relational query model.
The practical impact for you as a learner: the fundamentals you learn in this course remain durable, and the modern features you encounter later (window functions, JSON querying, temporal patterns) are best understood as extensions of the same set-based, declarative foundation.
Why dialects still exist
If SQL has a standard, why do dialect differences exist at all? Because: vendors implement different subsets of the standard, vendors ship features before the standard absorbs them, and database engines optimize for different workloads (OLTP vs analytics vs distributed systems).
In the next lesson, you will look at SQL dialect variations and learn how to write SQL that is both readable and portable while still taking advantage of a platform’s strengths when necessary.