| Lesson 2 | Advantages of clusters |
| Objective | Know when to use clustered tables. |
Purpose of a Clustered Table
A clustered table in an Oracle database is used to store rows from multiple tables that are related by a common key in the same data block. This setup is especially useful for queries that join these tables frequently on that key, as it allows Oracle to retrieve related rows together, improving the efficiency of certain read operations.
The key purposes of creating a clustered table are:
Clusters are particularly effective in cases where there's a high degree of data retrieval involving multiple tables and where storage efficiency and query performance are high priorities.
The key purposes of creating a clustered table are:
- Optimized Query Performance for Joins: When tables are clustered, rows with the same key value are stored together, making joins and retrievals of related data faster. This is particularly beneficial in OLTP (Online Transaction Processing) environments where frequent joins on a common key are needed.
- Reduced I/O: Clustering reduces the number of data blocks Oracle needs to access for joins on the clustered columns, leading to reduced I/O, which can improve performance, especially for disk-bound operations.
- Efficient Use of Storage: Clustered tables can make more efficient use of storage by reducing duplication of the cluster key and related values across multiple rows, saving space compared to traditional non-clustered table storage.
- Logical Data Grouping: Clustered tables are also useful for grouping logically related data together, which can simplify maintenance and make data retrieval more intuitive based on the organization of stored data.
Clusters are particularly effective in cases where there's a high degree of data retrieval involving multiple tables and where storage efficiency and query performance are high priorities.
- Advantages of Oracle Clustered Tables:
In theory, each data object within an Oracle database is a totally separate entity. In practice, certain tables are frequently used together, especially when using a normalized database design. A cluster is a way of organizing data to leverage the related nature of data stored in different locations.
What is a cluster?
Simply put, a cluster ties data values to disk location. A cluster key is used to group data together. All rows of all tables with the same value of the cluster key are stored in the same data block. The following series of images shows the difference between a normal table and a clustered table.
Table Index versus Cluster Key (Oracle Access)
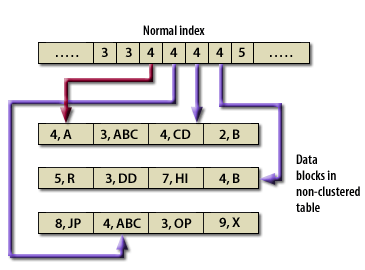
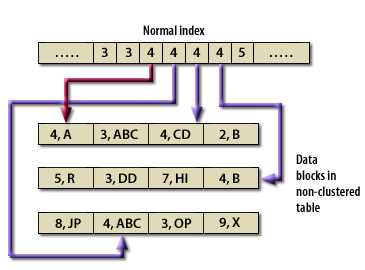
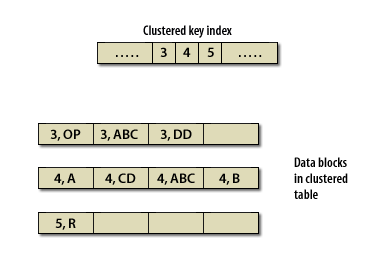
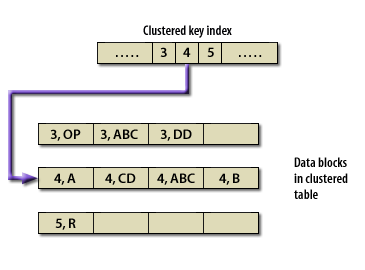
Advantages of a Cluster
Since related data is stored together, the related data can be accessed with fewer data block reads. With a cluster, Oracle reads the cluster key, which directly points to the disk area that contains the data for that value of the key. The cluster delivers two advantages:
- First of all, a query can retrieve all the related data with usually no more than 2 logical reads:
- one to get the cluster key and
- another to retrieve a data block that contains only the relevant data.
For instance, if an employee table is clustered on the department number, a query for employees in a department would first retrieve the relevant cluster key for the department and then the employee rows for that department. If an order header table and an order detail table were clustered together, one read would retrieve the order cluster key and one more read would retrieve both the order header and detail rows for that order. - The second advantage is that the value for the cluster key is only stored once, and this reduces the amount of space required for storage.
- When to use a cluster: The ideal places to use a cluster are when you have a group of tables that are frequently queried together, or when you have a single table that is frequently accessed by an index value. For example, you might cluster an order header table and an order detail table together. If you frequently accessed employees by department, you may want to cluster an employee table by department.
- When not to use a cluster: In some situations, a cluster is definitely not appropriate. You should not use a cluster in the following situations:
- If the value for a cluster key is updated frequently.
- If the data for the values of the cluster key takes up more than one or two Oracle data blocks.
- If you frequently require full table scans on the clustered data.
When is Clustering bad?
Clustering does not work well for all tables. For instance, clustering is inadvisable in the following three scenarios:
- Frequent updates of the cluster key-Remember that data is stored in a data block based on the value of the cluster key. If a user updates that value, the actual data row will have to be moved to a different data block, which is more resource intensive than a simple in-place update of a non-clustered row.
- Data takes up more than one or two blocks-The big advantage of clusters comes from the ability to read a data block that contains all the rows for a particular value for the cluster key. However, the cluster is set up so that the cluster key points to the first data block for the cluster. If there are multiple data blocks for a value, and you are trying to retrieve a specific row that is in a later block, you will actually increase the number of database reads with a cluster. This is because Oracle has to read through the values for the cluster from the beginning.
- Frequent table scans required-In a cluster, the data is stored according to a value in the cluster key. Because you may have a cluster that includes data from more than one table, the overall size of the cluster will be the combined size of the data in all the tables in the cluster. This combination means that a table scan of a single table in the cluster will take longer, and possiblymuch longer, than scanning the data for a single table.
- Database Clustering Architecture:
To achieve horizontal scalability or scale-out of a database, multiple database servers are grouped together to form a cluster infrastructure. These servers are linked by a private interconnect network and work together as a single virtual server that is capable of handling large application workloads. This cluster can be easily expanded or shrunk by adding or removing servers from the cluster to adapt to the dynamics of the workload. This architecture is not limited by the maximum capacity of a single server, as the vertical scalability (scale-up) method is.
There are two types of clustering architecture:
- Shared Nothing Architecture
- Shared Everything Architecture
Shared nothing architecture also does not work well with a large set of database applications such as OLTP (Online transaction processing), which need to access the entire database; this architecture will require frequent data redistribution across the nodes and will not work well. Shared nothing also does not provide high availability. Since each partition is dedicated to a piece of the data and workload which is not duplicated by any other server, each server can be a single point of failure. In case of the failure of any server, the data and workload cannot be failed over to other servers in the cluster.
Clustering Summary
In the context of an Oracle RDBMS, the term "clustering" usually refers to **1) table clustering**. This is a technique used to physically store related rows from one or more tables together on disk to improve query performance.
Oracle provides different types of table clustering, including:
While "database clustering" is a valid concept in general (referring to multiple interconnected database instances working together), it's less commonly discussed in the context of Oracle RDBMS itself. Oracle offers features like Real Application Clusters (RAC) for high availability and scalability, but this is usually considered a separate topic from table clustering. Therefore, when you encounter "clustering" in an Oracle RDBMS discussion, it's safe to assume it refers to table clustering techniques.
The next lesson shows how to create a cluster.
Oracle provides different types of table clustering, including:
- Indexed clustering: Rows from different tables that share a common column (the cluster key) are stored together.
- Hash clustering: Rows with the same hash key value are stored together.
- Attribute clustering: Rows are clustered based on the values in one or more columns of a table.
While "database clustering" is a valid concept in general (referring to multiple interconnected database instances working together), it's less commonly discussed in the context of Oracle RDBMS itself. Oracle offers features like Real Application Clusters (RAC) for high availability and scalability, but this is usually considered a separate topic from table clustering. Therefore, when you encounter "clustering" in an Oracle RDBMS discussion, it's safe to assume it refers to table clustering techniques.
The next lesson shows how to create a cluster.