| Lesson 6 | Hash clusters |
| Objective | Know When to use Oracle Hash Cluster |
Understanding and Using Oracle Hash Clusters
A hash cluster in Oracle Database is a data storage structure that organizes rows in data blocks based on the result of a hashing function applied to a key value. It provides an alternative to traditional indexed tables or indexed clusters by allowing direct access to rows through hash values - eliminating the need for a separate cluster index.
How Hash Clusters Work
In a conventional cluster, Oracle uses the cluster key value to locate data, typically involving two I/O operations: one for the index lookup and another for the actual data retrieval. In a hash cluster, this lookup is replaced by a hash function that maps the key value directly to a specific data block. As a result, a single I/O operation is often sufficient to access the desired row.
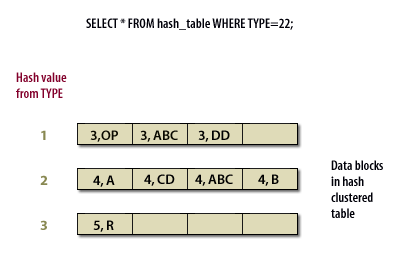
SELECT statement using a hash key to retrieve rows directly from the hashed cluster.
SELECT * FROM hash_table WHERE TYPE = 22;
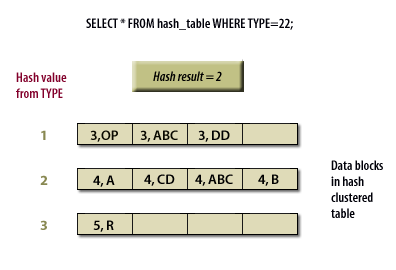
SELECT * FROM hash_table WHERE TYPE = 22;
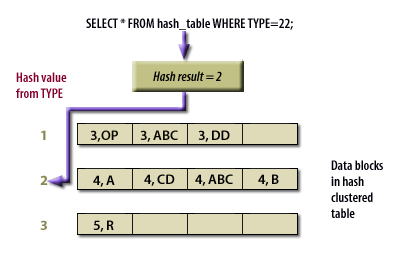
SELECT * FROM hash_table WHERE TYPE = 22;
Expert Oracle Indexing and Access Paths
Key Characteristics of Hash Clusters
- Hash clusters store rows based on the hash value derived from a cluster key, rather than maintaining a separate index structure.
- Because the index lookup is removed, I/O operations are reduced by half compared to indexed clusters or tables.
- All values in the cluster key must be numeric, since hashing functions operate on numeric inputs.
- The cluster can use Oracle’s internal hash function or a user-defined one to distribute rows evenly across data blocks.
When to Use a Hash Cluster
A hash cluster can significantly improve query performance when:
- The table is read frequently but modified infrequently.
- Most queries use equality conditions on the hash key, such as:
WHERE department_id = 20; - You can estimate the number of unique hash key values and the average size of data associated with each key.
Hashing Functions and Data Distribution
The hashing function determines how data rows are distributed among blocks. Oracle applies the hash function to the key value, and the resulting hash determines the data block that stores the row. This process ensures predictable access patterns, which can provide faster retrieval for equality searches.
However, the performance of hash clusters depends on choosing an appropriate number of hash keys and sizing the cluster correctly. Uneven data distribution can lead to wasted space or block contention. Proper sizing and understanding of data access patterns are crucial for realizing performance gains.
Practical Use Case
Consider a table where employee data is frequently queried by department number but rarely updated. Creating a hash cluster on the department_id column allows Oracle to hash the department key directly to the corresponding data block, returning results with minimal disk I/O.
Summary
A hash cluster is an advanced Oracle feature that stores data rows based on the results of a hash function rather than relying on traditional indexing. It is ideal for workloads dominated by equality-based lookups and stable datasets. By using hash clusters appropriately, database administrators can reduce I/O overhead, improve response time, and maintain efficient access patterns for high-performance systems.