CREATE INDEX for a cluster
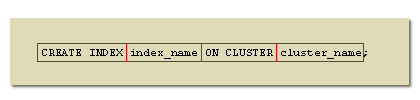
CREATE INDEX index_name ON CLUSTER cluster_name
| CREATE INDEX | Required keywords. |
| index_name | The name of the index. |
| ON CLUSTER | Required keywords. |
| cluster_name | The name of a pre-existing cluster. |
Create Indexes After Inserting Table Data
Data is often inserted or loaded into a table using either the SQL*Loader or an import utility. It is more efficient to create an index for a table after inserting or loading the data. If you create one or more indexes before loading data, the database then must update every index as each row is inserted. Creating an index on a table that already has data requires sort space. Some sort space comes from memory allocated for the index creator. The amount for each user is determined by the initialization parameter SORT_AREA_SIZE.
The database also swaps sort information to and from temporary segments that are only allocated during the index creation in the users temporary tablespace. Under certain conditions, data can be loaded into a table with SQL*Loader direct-path load and an index can be created as data is loaded.
The database also swaps sort information to and from temporary segments that are only allocated during the index creation in the users temporary tablespace. Under certain conditions, data can be loaded into a table with SQL*Loader direct-path load and an index can be created as data is loaded.
Indexes
An index is a data structure that speeds up access to particular rows in a database. An index is associated with a particular table and contains the data from one or more
columns in the table.
The basic SQL syntax for creating an index is shown in this example
The Oracle database server automatically modifies the values in the index when the values in the corresponding columns are modified. Because the index contains less data than the complete row in the table and since indexes are stored in a special structure that makes them faster to read, it takes fewer I/O operations to retrieve the data in the table. Selecting rows based on an index value can be faster than selecting rows based on values in the table rows. In addition, most indexes are stored in sorted order (either ascending or descending, depending on the declaration made when you created the index). Because of this storage scheme, selecting rows based on a range of values or returning rows in sorted order is much faster when the range or sort order is contained in the presorted indexes.
In addition to the data for an index, an index entry stores the ROWID for its associated row. The ROWID is the fastest way to retrieve any row in a database, so the subsequent retrieval of a database row is performed in the most optimal way. An index can be either unique (which means that no two rows in the table or view can have the same index value) or nonunique. If the column or columns on which an index is based contain NULL values, the row isn’t included in an index. An index in Oracle refers to the physical structure used within the database. A key is a term for a logical entity, typically the value stored within the index. In most places in the Oracle documentation, the two terms are used interchangeably, with the notable exception of the foreign key constraint.
The basic SQL syntax for creating an index is shown in this example
CREATE INDEX emp_idx1 ON emp (ename, job);in which emp_idx1 is the name of the index, emp is the table on which the index is created, and ename and job are the column values that make up the index.
The Oracle database server automatically modifies the values in the index when the values in the corresponding columns are modified. Because the index contains less data than the complete row in the table and since indexes are stored in a special structure that makes them faster to read, it takes fewer I/O operations to retrieve the data in the table. Selecting rows based on an index value can be faster than selecting rows based on values in the table rows. In addition, most indexes are stored in sorted order (either ascending or descending, depending on the declaration made when you created the index). Because of this storage scheme, selecting rows based on a range of values or returning rows in sorted order is much faster when the range or sort order is contained in the presorted indexes.
In addition to the data for an index, an index entry stores the ROWID for its associated row. The ROWID is the fastest way to retrieve any row in a database, so the subsequent retrieval of a database row is performed in the most optimal way. An index can be either unique (which means that no two rows in the table or view can have the same index value) or nonunique. If the column or columns on which an index is based contain NULL values, the row isn’t included in an index. An index in Oracle refers to the physical structure used within the database. A key is a term for a logical entity, typically the value stored within the index. In most places in the Oracle documentation, the two terms are used interchangeably, with the notable exception of the foreign key constraint.