Identifying implications of instance failure with an ARCHIVELOG database
Objective
Describe what happens if the instance fails.
Identifying Implications of instance failure with an ARCHIVELOG Database
Question: How do I identify implications of instance failure with an ARCHIVELOG database in Oracle?
An instance failure in Oracle refers to an abrupt termination of an Oracle instance, which can result from various reasons including a power failure, hardware failure, or a shutdown abort command. When an instance failure occurs in an Oracle database that's running in ARCHIVELOG mode, there are several implications that you need to be aware of. This guide will highlight these implications and provide key insights for database administrators.
Incomplete Transactions: One of the most immediate implications of instance failure is the presence of incomplete transactions. These are transactions that were in progress at the time of the failure but did not commit. Upon restarting the Oracle instance, the system will automatically roll back these incomplete transactions to maintain the ACID properties of the database.
Recovery Time: If your database is running in ARCHIVELOG mode, the instance recovery process can be more time-consuming compared to NOARCHIVELOG mode. This is because the system has to apply both online redo logs and archived redo logs to recover the database to its most recent state. However, this also means that you can recover all committed transactions up to the point of the failure, which is not possible in NOARCHIVELOG mode.
Data Consistency: Even with an instance failure, an Oracle database in ARCHIVELOG mode guarantees data consistency. After the instance restarts, Oracle will automatically initiate an instance recovery process, which involves two main steps: cache recovery (rolling forward) and transaction recovery (rolling back). Oracle uses the online redo logs and archived redo logs to reapply all changes made to the database, ensuring that all committed transactions are preserved and the database remains consistent.
Space Usage: Running a database in ARCHIVELOG mode requires sufficient disk space to store the archived redo logs. If your system experiences frequent instance failures, it might result in a large number of archived redo logs, which can quickly consume available disk space. It's essential to regularly monitor and manage the archived redo logs to avoid potential storage issues.
Impact on Database Performance: Instance recovery in ARCHIVELOG mode can affect the database's performance. Although this process is optimized to be as fast as possible, applying a large number of redo logs during recovery might temporarily degrade the database performance. It is crucial to consider this when planning for high-availability architectures.
Backup and Restore: In ARCHIVELOG mode, the database remains online and fully accessible during backup operations. However, an instance failure during a backup operation could potentially impact the backup's consistency. Nonetheless, you can still perform a complete recovery from such backups by applying the necessary redo logs.
Remember, although an instance failure can have significant implications, the ARCHIVELOG mode provides greater data protection and complete recovery capabilities. It is always recommended to run production databases in ARCHIVELOG mode despite the potential overheads, as the benefits of data safety and complete recovery far outweigh the costs. By understanding these implications, database administrators can better manage and respond to instance failures in an Oracle database.
Implications of Instance failure
Instance failure means an abrupt end to an Oracle instance due to either hardware or software problems.
The (SGA) system global area and background processes cease to function. Therefore, any data in the buffer that had not already been written to a datafile at the time of the instance failure will be lost. Complete recovery recovers the damaged datafiles as well as all data that had been committed prior to the moment of instance failure.
Before you can completely recover the datafiles up to the time of failure, you must have the following in place:
A valid backup after the database was set in ARCHIVELOG mode. This backup must include the datafiles needing recovery.
All archive logs from the last backup up to the time the instance failure occurred.
To perform a complete recovery, you must follow the steps below:
For an open database recovery, place the damaged datafiles offline.
A closed database recovery can be performed with the files online.
Advantages and disadvantages of Complete Recovery
Advantages
Disadvantages
Only lost or damaged files need to be restored.
All data is recovered to the time of failure, so no committed data is lost. Applying archived and redo logs to the restored file brings the database to the current point in time.
The total recovery time is equal to the time your disk can restore the required files plus apply all archived and redo logs.
Recovery can be performed while the database is open for access. However, the database cannot be recovered in open mode if the SYSTEM tablespace or datafiles containing online rollback segments need to be recovered.
All archived logs from the time of your last backup to the current time must be available because all archives need to be applied in sequence.
If one log is missing, a complete recovery becomes impossible.
You can recover only up to the point of the missing archive log.
Routine closed whole database backups of the ARCHIVELOG database are recommended.
Recovering from Failures
Despite the prevalence of redundant or protected disk storage, media failures can and do occur. In cases in which one or more Oracle datafiles are lost due to disk failure, you must use database backups to recover the lost data. There are times when simple human or machine error can also lead to the loss of data, just as a media failure can. For example, an administrator may accidentally delete a datafile, or an I/O subsystem may malfunction, corrupting data on the disks. The key to being prepared to handle these types of failures is implementing a good backup-and-recovery strategy and understanding the power of Oracle's newer features such as Flashback.
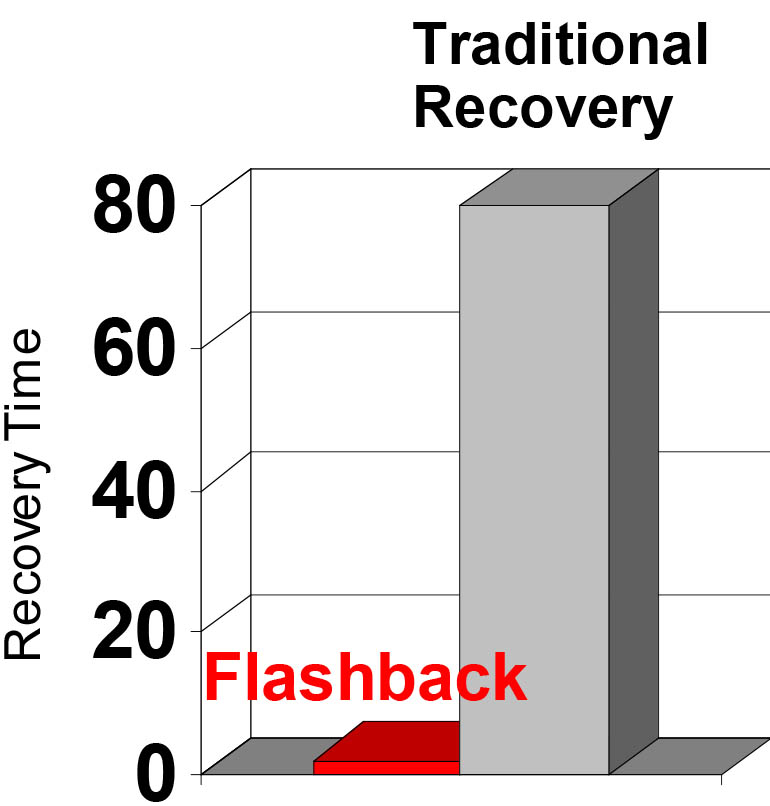
This diagram shows the recovery time for 1) Flashback versus 2) Traditional Recovery
Flashback revolutionizes error recovery
View "good" data as of a past point-in-time
Simply rewind data changes
Time to correct error equals time to make error
Correction Time = Error Time
Low impact
Excellent tool for configuring QA, Dev and Training databases
Flashback is easy – simple commands, no complex procedure
Developing a Backup-and-Recovery Strategy
Proper development, documentation, and testing of your backup-and-recovery strategy is one of the most important activities in implementing an Oracle database. You must test every phase of the backup-and-recovery process to ensure that the entire process works, because once a disaster hits, the complete recovery process must work flawlessly. Some companies test the backup procedure but fail to actually test recovery using the backups taken. Only when a failure requires the use of the backups do companies discover that the backups in place were unusable for some reason. It is critical to test the entire cycle from backup through restore and recovery.
To ascertain datafile online/offline status, you can query the V$DATAFILE and V$TABLESPACE views.
Restore the damaged or lost datafiles.
Place the database in either mount or open mode.
Recover the datafiles using the RECOVER command.
Restoring all files, including control files, redo logs, the parameter file, and the password file, brings your data back in time. However, for complete recovery, you do not want to restore the database to a previous point in time or restore the online redo log files. Instead, you want to restore to the last committed transaction. To do this, you must synchronize the datafiles with the most recent time recorded in the control file. It is easy to perform this recovery if the latest control file has survived the media failure. You can ensure control file survival by maintaining multiple copies on different disks. The next lesson describes different methods of recovery.