Describe how the data buffer cache affects performance.
Tuning Considerations of data buffer cache
The buffer cache is the in-memory area of the SGA where incoming Oracle data blocks are kept.
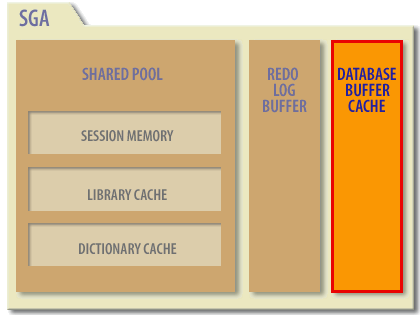
Oracle buffer cache located to the extreme right of the diagram.
Buffer Cache Size and Database Performance
On standard UNIX databases, the data is read from disk into the UNIX buffer where it is then transferred into the Oracle buffer. The size of the buffer cache can have a huge impact on Oracle system performance. The larger the buffer cache, the greater the likelihood that data from a prior transaction will reside in the buffer, thereby avoiding a physical disk I/O. When a request is made to Oracle to retrieve data, Oracle will first check the internal memory structures to see if the data is already in the buffer. In this fashion, Oracle avoids doing unnecessary I/O. It would be ideal if you could create one buffer for each database page, ensuring that Oracle would read each block only once. However, the cost of memory in the real world makes this prohibitive. At best, you can only allocate a small number of real-memory buffers, and Oracle will manage this memory for you by using a least-recently-used algorithm to determine which database blocks are to be flushed from memory.
Performance Problems in Data Buffer
Bad performance in the data buffer is always the result of data being flushed from the buffer because of high I/O activity.
The best remedy is to increase the db_block_buffer init.ora parameter. In this course, you will learn how to calculate the performance improvements that you would get from increasing data buffers and database block size.
Advantages of large database block size
Another related memory issue deals with the size of the database blocks. In most UNIX environments, database blocks are sized to only 2K. The cost of reading a 2K block is not significantly higher than the cost of reading an 8K block and the 8K block will be of no benefit if you only want a small row in a single table. However, if the tables are commonly read front-to-back, or if you make appropriate use of Oracle clusters you can reap dramatic performance improvements by switching to large block sizes. Remember, the marginal cost of reading a large block is quite small, and the more data that can be accessed in a single I/O, the more data will be placed into your data buffer. The only exception to this rule would be an OLTP database that always fetches a very small row, and does not use any adjacent row data in a block. Even in these cases, index node rows commonly reside on the same block. For batch-oriented reporting databases, very large block sizes are always recommended. The db_block_size parameter is used to control the block size. Unlike other relational databases, Oracle allocates the data files on your behalf when you use the CREATE TABLESPACE command. In this course, you will learn how to calculate the relative performance improvements that you would get from increasing data buffers and database block size. We will investigate the data buffer in great detail in a later module.
Large UNIX blocks
Unlike the mainframe ancestors that allowed blocks of up to 16,000 bytes, for Oracle, large UNIX blocks are not always desirable because of the way UNIX handles its page I/O. Remember, I/O is the single most important slowdown in a client/server system, and the more relevant the data that can be grabbed in a single I/O, the better the performance. As UNIX systems have become increasingly powerful, a number of system vendors and UNIX independent software vendors have developed a requirement to access files that contain more information than can be addressed using a signed long integer. A number of major system vendors and users met at the "Large File Summit" (LFS) to develop a set of changes to the existing Single UNIX Specification (SUS) that allow both new and converted programs to address files of arbitrary sizes.
March 20, 1996
This set of changes was provided to X/Open for inclusion into the next version of the SUS.
In addition, a set of transitional extensions intended to permit users to immediately implement large file support on typical 32-bit UNIX operating systems was proposed.
Buffer Cache and SGA
The buffer cache is the in-memory area of the SGA where incoming Oracle data blocks are kept. On standard Unix databases, the data is read from disk into the Unix buffer where it is then transferred into the Oracle buffer. The size of the buffer cache can have an impact on Oracle system performance. The larger the buffer cache, the greater the likelihood that data from a prior transaction will reside in the buffer, thereby avoiding a physical disk I/O. When a request is made to Oracle to retrieve data, Oracle will first check the internal memory structures to see if the data is already in the buffer. Using this technique, Oracle avoids performing any unnecessary I/O. It would be ideal if you could create one buffer for each database page, ensuring that Oracle would read each block only once.
Real-memory Buffers
Oracle Database utilizes an intelligent and comprehensive mechanism for memory management. Post allocation of real-memory buffers, the management is broadly done across three key components:
System Global Area (SGA), Program Global Area (PGA), and memory utilized by Oracle processes.
System Global Area (SGA):
The SGA is a group of shared memory structures that contain data and control information for an Oracle database instance. Oracle automatically manages the size of the SGA and its components, such as the database buffer cache, shared pool, and large pool.
Database Buffer Cache: This is Oracle's memory area that holds copies of data blocks read from data files. Oracle manages this cache and uses a complex algorithm (LRU algorithm) to decide which blocks should be kept in memory and which should be written to disk.
Shared Pool: This is where Oracle caches many data structures such as SQL statements, parameters, and dictionary data. Oracle uses complex algorithms to decide what to keep and what to discard from the shared pool.
Large Pool: An optional memory component intended for large memory allocations. Oracle decides on its size depending on factors such as the type of operations (for instance, backup and recovery operations) performed on the database.
Program Global Area (PGA): The PGA is a memory region containing data and control information for a single server process. Its size and usage depend on the Oracle server's configuration. Oracle introduced Automatic Memory Management (AMM) and Automatic Shared Memory Management (ASMM) to handle PGA. Oracle dynamically adjusts the size of the PGA as per the requirements of the operations being performed.
Oracle Processes: Oracle processes such as database writer processes, log writer process, checkpoint processes, etc., consume some memory, which is typically allocated at the process startup and remains constant throughout the process's lifetime. Oracle uses several techniques for memory management, including:
Automatic Memory Management (AMM): Oracle uses AMM to automatically manage both the SGA and the PGA memory, ensuring optimal distribution of memory resources.
Automatic Shared Memory Management (ASMM): ASMM automates the sizing of the SGA components, including the shared pool, large pool, and buffer cache.
Automatic PGA Memory Management: This management technique automates the sizing of SQL work areas.
Oracle also provides parameters such as MEMORY_TARGET and MEMORY_MAX_TARGET to provide upper limits on the memory consumed by Oracle Database. By adjusting these parameters, DBAs can control the system's memory usage. In conclusion, Oracle uses an intelligent, adaptive, and automatic strategy for managing memory post allocation of real-memory buffers, leveraging a combination of algorithms, automatic management techniques, and adjustable parameters. This strategy ensures optimal performance and efficient use of system resources.
One can only allocate a small number of real-memory buffers, and Oracle will manage this memory for you.
Oracle utilizes a (LRU) Least recently used algorithm to determine which database pages are to be flushed from memory.
Data Block Size
Another related memory issue emerges that deals with the size of the database blocks. In most Unix environments, database blocks are sized to only 4K. The cost of reading a 2K block is not significantly higher than the cost of reading an 8K block. However, the 8K block read will be of no benefit if you only want a small row in a single table. On the other hand, if the tables are commonly read front-to-back, or if you make appropriate use of Oracle clusters, you can reap performance improvements by switching to large block sizes. For batch-oriented reporting databases, very large block sizes are always recommended. However, many databases are used for online transaction processing during the day, while the batch reports are run in the evenings. As a general rule, 8K block sizes will benefit most systems. Fortunately, Oracle allows for large block sizes, and the db_block_size parameter is used to control the physical block size of the data files. Unlike other relational databases, Oracle allocates the data files on your behalf when the CREATE TABLESPACE command is issued. Avoid running a full-table scan on a large table, since this is one of the worst things that can happen to a buffer cache .
In the next lesson, we will examine tuning considerations of the third important area of the SGA, the redo log buffer.