| Lesson 10 | Tuning redo log checkpoints |
| Objective | Set log_checkpoint_interval to maximize performance. |
Maximize Performance by Setting log_checkpoint_interval
To tune the `log_checkpoint_interval` parameter in Oracle 11g for optimal performance, follow these guidelines:
-
Understand What It Controls:
log_checkpoint_intervalspecifies the maximum number of operating system blocks (not Oracle blocks) that can be written to the redo logs before a checkpoint occurs.- This parameter indirectly influences the frequency of checkpoints, affecting database recovery time and performance.
-
Optimal Tuning Strategy:
- Set the Value High for High-Throughput Environments: If you prioritize performance over recovery time, increase the
log_checkpoint_intervalvalue. This reduces the frequency of checkpoints, lowering the overhead of writing checkpoint data. - Set the Value Lower for Faster Recovery: In environments where fast recovery is crucial, decrease the value so that checkpoints happen more frequently. This reduces recovery time in the event of a crash but can affect performance.
- Set the Value High for High-Throughput Environments: If you prioritize performance over recovery time, increase the
-
Consider Other Checkpoint Parameters:
log_checkpoint_timeout: Defines the maximum time interval (in seconds) between automatic checkpoints, independent oflog_checkpoint_interval.fast_start_mttr_target: Specifies the time (in seconds) that the database should aim to recover from an instance failure. If set, it overrideslog_checkpoint_interval.
-
Implementation Example:
ALTER SYSTEM SET log_checkpoint_interval = <value> SCOPE = BOTH;- Replace
<value>with the appropriate number of blocks based on your performance needs.
- Replace
-
Monitoring Performance:
- Use the
V$INSTANCE_RECOVERYview to monitor how checkpoint parameters affect the estimated mean time to recover (MTTR). - Check the redo logs and system performance metrics to ensure that the frequency of checkpoints is balanced with your recovery requirements.
- Use the
-
Testing and Adjustment:
- Implement changes in a test environment and observe the impact on performance and recovery time.
- Fine-tune based on workload patterns and ensure that the database is meeting both performance and recovery goals.
Checkpoint pros and cons
Checkpoints are used to commit data from the Oracle buffers. A checkpoint occurs at every redo log switch. If a previous checkpoint is already in progress, the checkpoint forced by the log switch will override the current checkpoint. This necessitates well-sized redo logs to avoid unnecessary checkpoints because of frequent log switches. Frequent checkpoints will enable faster recovery after a crash, but can cause performance degradation during regular processing. A checkpoint can be a highly resource-intensive operation because all datafile headers are frozen during the checkpoint.
Hence, frequent checkpointing for a large database with hundreds of data files will mean that the entire database must pause each time a checkpoint is issued.
The following series of images illustrates the checkpoint process.
The following series of images illustrates the checkpoint process.

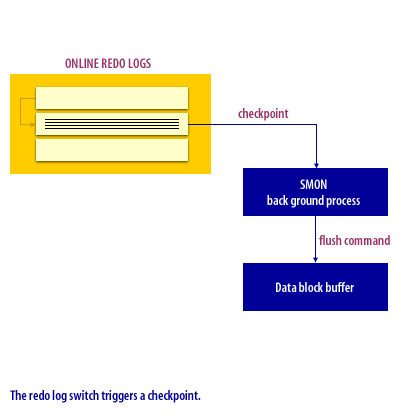
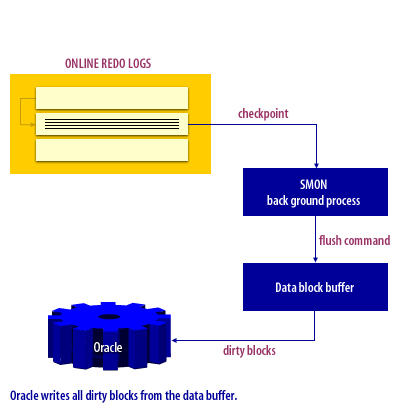
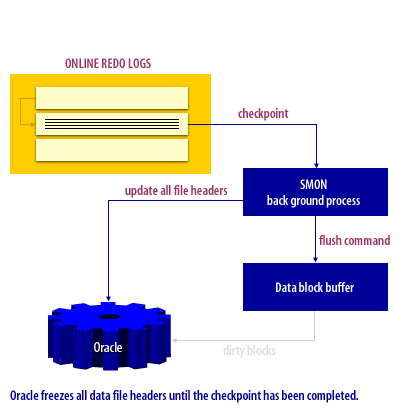
Checkpoint
Online redo log setup problems:
Many sites run with too few online redo log files and files that are too small. Small redo log files cause system checkpoints to continuously put a high load on the buffer cache and I/O system. If too few redo log files exist, then the archive cannot keep up, and the database must wait for the archiver to catch up.
- Sizing Redo Log Files:
The size of the redo log files can influence performance, because the behavior of the database writer and archiver processes depend on the redo log sizes. Generally, larger redo log files provide better performance. Undersized log files increase checkpoint activity and reduce performance. Although the size of the redo log files does not affect LGWR performance, it can affect DBWR and checkpoint behavior. Checkpoint frequency is affected by several factors, including log file size and the setting of the FAST_START_MTTR_TARGET initialization parameter. If the FAST_START_MTTR_TARGET parameter is set to limit the instance recovery time, Oracle Database automatically tries to checkpoint as frequently as necessary. Under this condition, the size of the log files should be large enough to avoid additional checkpointing due to under sized log files. The optimal size can be obtained by querying the OPTIMAL_LOGFILE_SIZE column from the V$INSTANCE_RECOVERY view. You can also obtain sizing advice on the Redo Log Groups page of Oracle Enterprise Manager.It may not always be possible to provide a specific size recommendation for redo log files, but redo log files in the range of 100 MB to a few gigabytes are considered reasonable. Size online redo log files according to the amount of redo your system generates. A rough guide is to switch log files at most once every 20 minutes.
Checkpoint frequency
The init.ora parameter log_checkpoint_interval controls how often a checkpoint operation will be performed. This interval is based upon the number of operating system blocks that have been written to the redo log. If the log_checkpoint_interval is larger than the size of the redo log, then the checkpoint will only occur when Oracle performs a log switch from one group to another, which is ideal. For example, in UNIX systems the OS block size is 512 bytes. If the log_checkpoint_interval is set to 100,000, that a checkpoint will occur after 50MB (512*100,000) has been written to the redo log. If the size of your redo log is 50MB, you are taking one checkpoint for each log. The next lesson wraps up this module.
- Parameter changes between Oracle 11g and "cloud-enabled" databases Oracle 12c to Oracle 19c:
The `log_checkpoint_interval` parameter has seen some changes between Oracle 11g and the later cloud-enabled databases, including Oracle 12c to Oracle 19c.
- De-emphasis in Tuning: In Oracle 12c and beyond, tuning parameters like
log_checkpoint_intervalhas become less emphasized, mainly due to the introduction of more sophisticated and automated mechanisms, such as thefast_start_mttr_target[1] parameter, which dynamically manages checkpoints and recovery performance. - Reliance on
fast_start_mttr_target: Starting with Oracle 12c, Oracle's recommendation is to set and tune thefast_start_mttr_targetparameter rather than manually adjustinglog_checkpoint_interval. The database usesfast_start_mttr_targetto automatically adjust the checkpoint frequency to meet the desired Mean Time To Recovery (MTTR) without having to rely heavily onlog_checkpoint_interval. - Deprecation Warnings: While
log_checkpoint_intervalis still available in Oracle 12c to 19c, it is generally considered deprecated, and Oracle advises using automated features for checkpoint tuning. In many cases, the effect oflog_checkpoint_intervalis overridden or minimized by other, more modern mechanisms in these versions.
- De-emphasis in Tuning: In Oracle 12c and beyond, tuning parameters like
[1]
fast_start_mttr_target: `fast_start_mttr_target` is an Oracle database initialization parameter that allows you to specify the desired Mean Time To Recover (MTTR) in seconds. Oracle uses this target to automatically adjust checkpoint frequency and other internal mechanisms to try and achieve the specified recovery time objective in the event of an instance failure.