| Lesson 8 | Tuning considerations of the redo log buffer |
| Objective | Describe the performance issues related to the redo log buffer. |
Redo Log Buffer and Performance Issues related to redo log buffer
Performance issues related to the Redo Log Buffer in Oracle 19c primarily center on contention, insufficient sizing, and inefficient log-writing processes. Understanding these issues helps ensure better performance and reliability for transactional workloads.
Here’s a detailed breakdown:
What is the Redo Log Buffer? The redo log buffer is a memory area in Oracle that temporarily stores redo entries (records of changes made to the database). These redo entries are eventually written by the Log Writer process (LGWR) into the redo log files on disk.
Potential Performance Issues:
1. Redo Log Buffer Contention
2. Inefficient or Delayed Writes by LGWR
Here’s a detailed breakdown:
What is the Redo Log Buffer? The redo log buffer is a memory area in Oracle that temporarily stores redo entries (records of changes made to the database). These redo entries are eventually written by the Log Writer process (LGWR) into the redo log files on disk.
Potential Performance Issues:
1. Redo Log Buffer Contention
-
Cause: Multiple concurrent transactions competing for space in the redo log buffer.
- High activity on transactional systems can result in frequent waiting for redo buffer space.
-
Symptoms: "log buffer space" wait events appear frequently.
- Reduced transaction throughput.- (This item describes symptoms, not child items, so no further nested list is needed)
-
Resolution: Increase the redo log buffer size (`LOG_BUFFER` parameter).
- Optimize transactions (commit less frequently in small transactions).
2. Inefficient or Delayed Writes by LGWR
-
Cause: Slow disk I/O subsystem.
- Inefficient disk configuration (lack of fast SSDs or insufficient IOPS).
- Overloaded LGWR process due to excessive commit frequency or small redo log files.
-
Symptoms: Increased wait events like "log file sync" or "log file parallel write".
- Users experience increased latency during commits.- (This item describes symptoms, not child items, so no further nested list is needed)
-
Resolution: Improve disk I/O subsystem performance (SSD, RAID configuration).
- Multiplex redo log files across different storage devices.
- Adjust commit frequency in applications.
3. Insufficient Redo Log Buffer Size
-
Cause: Redo buffer size too small to accommodate transaction load.
- Results in increased frequency of LGWR writes to disk.
-
Symptoms: Frequent "log buffer space" waits.
- Reduced transaction throughput, high CPU overhead.- (This item describes symptoms, not child items, so no further nested list is needed)
-
Resolution: Appropriately size the redo log buffer (default managed automatically in Oracle 19c, but manual tuning may be needed):
-
ALTER SYSTEM SET LOG_BUFFER = [appropriate_size] SCOPE=SPFILE;
- Reboot the instance after changes.
-
4. High Transaction Commit Rates
-
Cause: Applications frequently issuing short transactions (frequent commits).
- High “log file sync” waits.
- Increased I/O overhead on redo logs.
-
Symptoms: High “log file sync” waits.
- Increased I/O overhead on redo logs.- (This item describes symptoms, not child items, so no further nested list is needed)
-
Resolution: Batch transactions and commit less frequently.
- Tune applications to use fewer commits for bulk operations.- (This item describes resolutions, not child items, so no further nested list is needed)
Best Practices for Redo Log Buffer in Oracle 19c: Allow Oracle Automatic Memory Management to set redo log buffer size.
-
Monitor frequently using:
SELECT event, total_waits, average_wait FROM v$system_event WHERE event IN ('log file sync', 'log file parallel write', 'log buffer space'); - Optimize disk I/O performance (SSD or NVMe).
- Regularly evaluate LGWR performance.
Conclusion: Redo log buffer performance issues in Oracle 19c are usually due to contention, inefficient buffer sizing, excessive commit frequency, or disk I/O bottlenecks. Addressing these through buffer sizing, application tuning, and storage optimization significantly improves Oracle database performance.
The redo log buffer contains the Oracle redo logs that hold previous versions of Oracle transactions and are used to roll-forward the database in cases of disk failure. When a database is in ARCHIVELOG mode, Oracle will write these redo logs onto a disk file with the ARCH background process. Regardless of the ARCHIVELOG mode, Oracle must still manage the redo images and write them to the online redo logs, via the redo log buffer.
Oracle System Global Area (SGA)
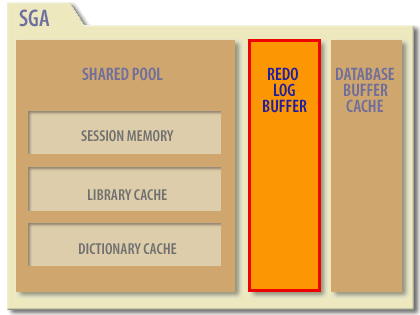
-
Shared Pool (Left-hand side box)
- Session Memory: Stores session-specific information for each connected user, including user-specific session variables and context data.
- Library Cache: Stores parsed SQL statements, execution plans, and PL/SQL program units to avoid redundant parsing and compilation.
- Dictionary Cache: Holds frequently accessed data dictionary information such as object definitions, privileges, and users.
-
Redo Log Buffer (highlighted in orange with red outline):
- Temporarily stores changes made to the database.
- Changes are recorded here before being written to redo log files on disk.
- Essential for recovery operations, ensuring transaction durability and consistency.
-
Database Buffer Cache:
- Caches copies of data blocks from disk to minimize disk I/O.
- Provides quick access to frequently used data blocks.
In a typical database operation sequence:
- When a database transaction occurs, the change information (redo entries) first goes into the Redo Log Buffer.
- Eventually, these entries are flushed (written) by the Log Writer process (LGWR) to the Redo Log Files, ensuring durability and recoverability of database transactions.
- The redo information is critical for recovery operations, database rollbacks, and to maintain ACID properties.
Redo Log - Exercise
Before you go on, click the Exercise link below to check your knowledge of basic SGA tuning concepts.
Redo Log - Exercise
Redo Log - Exercise