| Lesson 12 | Archived Redo Logs |
| Objective | Explain how archived redo enables point-in-time and media recovery, and how to monitor/operate it safely. |
Archived Redo Logs in Oracle
Archived redo logs are copies of full online redo log groups created when a log switch occurs and the database runs in ARCHIVELOG mode. Together with backups, archived redo lets Oracle recover to any time, SCN, or sequence after a failure-without losing committed work.
- LGWR writes redo to the current online log group.
- At a switch, ARCn processes copy one member of the closed group to the archive destination (often the Fast Recovery Area, FRA).
- Oracle can reuse a group only when checkpoint progress is sufficient and, in ARCHIVELOG mode, after that group has been archived.
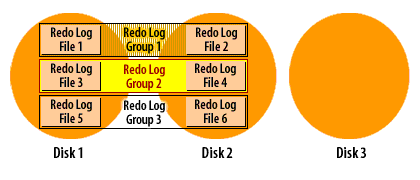
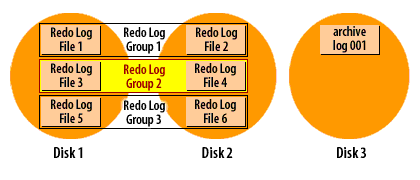
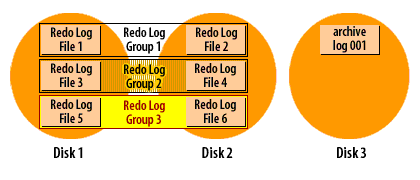
How ARCHIVELOG mode works (visual walkthrough)
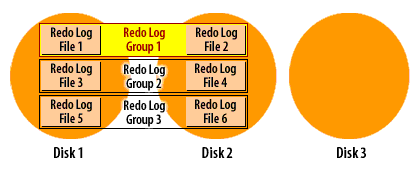
Transcription excerpt: “Redo Log Group 1/2/3 … Disks 1–3.”
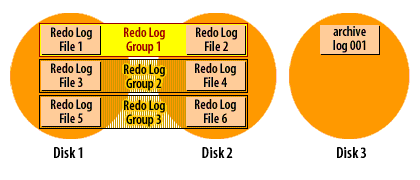
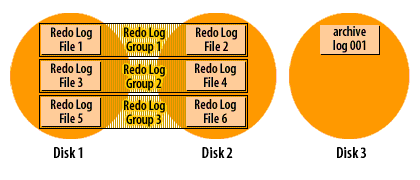
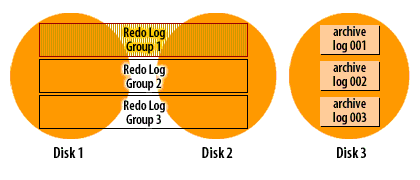
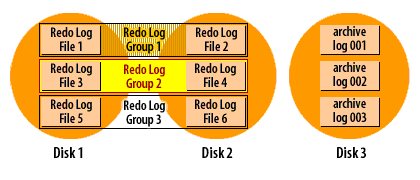
Enabling ARCHIVELOG and directing archives to FRA
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
-- Fast Recovery Area (FRA) - preferred landing zone for archives/backups
ALTER SYSTEM SET db_recovery_file_dest = '/u02/app/oracle/fast_recovery_area' SCOPE=BOTH;
ALTER SYSTEM SET db_recovery_file_dest_size = 200G SCOPE=BOTH;
ALTER SYSTEM SET log_archive_dest_1 = 'LOCATION=USE_DB_RECOVERY_FILE_DEST' SCOPE=BOTH;
Notes: If you use Oracle Managed Files (OMF), archive naming is automatic. Without OMF, naming is controlled by LOG_ARCHIVE_FORMAT (where supported). Size the FRA so ARCn never stalls; monitor and purge obsolete files with RMAN.
Point-in-time recovery (PITR): how archives are used
- Restore datafiles from a full/incremental backup (RMAN or storage snapshot).
- Apply archived redo (and, if needed, online redo) up to a target SCN/time/sequence.
- Open the database RESETLOGS at the chosen point.
Operational SQL to monitor health
What groups exist and which is current?
SELECT l.group#, l.sequence#, ROUND(l.bytes/1024/1024) AS size_mb,
l.members, l.archived, l.status
FROM v$log l
ORDER BY l.group#;
Archive destinations and errors (watch FRA fullness):
SELECT dest_id, destination, status, error
FROM v$archive_dest
ORDER BY dest_id;
Recent archive activity and lag:
SELECT sequence#, first_time, next_time, applied
FROM v$archived_log
WHERE dest_id = 1
ORDER BY first_time DESC
FETCH FIRST 20 ROWS ONLY;
Switch cadence (helps size logs for steady intervals):
SELECT TO_CHAR(first_time, 'YYYY-MM-DD HH24') AS hour_slot,
COUNT(*) AS switches
FROM v$log_history
WHERE first_time > SYSDATE - 1
GROUP BY TO_CHAR(first_time, 'YYYY-MM-DD HH24')
ORDER BY hour_slot DESC;
RMAN essentials (back up and clean up)
RMAN> CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;
RMAN> BACKUP DATABASE PLUS ARCHIVELOG;
RMAN> BACKUP ARCHIVELOG ALL NOT BACKED UP 1 TIMES;
RMAN> CROSSCHECK ARCHIVELOG ALL;
RMAN> DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;
RMAN> DELETE NOPROMPT OBSOLETE;
Log mining [1] (change reporting)
LogMiner reads redo/archived redo to reconstruct DML/DDL for auditing and troubleshooting. It populates dictionary views you can query for reports. It’s complementary to recovery: redo guarantees durability; LogMiner helps interpret what happened.
Common pitfalls and how to avoid them
- Archiver backlog → add/move ARCn slaves, speed up archive storage, right-size logs, ensure FRA headroom.
- Single-member groups → multiplex members on separate devices/ASM failure groups.
- All members on one LUN → no failure isolation; spread paths.
- FRA saturation → monitor usage, back up and purge obsolete archives; set alerts and jobs.
Fleet monitoring and Automation
For dashboards, alerts, jobs, and trend analysis across many databases, use Enterprise Manager Cloud Control (monitoring, automation, lifecycle operations).
Glossary
- LGWR - Log Writer; flushes redo at commit and other triggers.
- ARCn - Archiver processes; copy closed online logs to archive destinations.
- FRA - Fast Recovery Area; managed storage for archives/backups.
- PITR - Point-in-time recovery; restore and roll forward to a chosen point.