| Lesson 17 | The Checkpoint Process (CKPT) |
| Objective | Explain the function of the Checkpoint process. |
Checkpoint Process (CKPT) in Oracle
The Checkpoint process (CKPT) is a critical Oracle background process that ensures database consistency by coordinating the writing of modified data to disk. A checkpoint is a point in time when Oracle ensures that all changes up to a specific redo log entry are written to the database datafiles by the Database Writer (DBWR) process. The CKPT process records this checkpoint in the control file and updates the headers of all datafiles. Checkpoints are triggered by events such as log switches, database shutdowns, or specific administrative commands, rather than a fixed time interval.
The following series of images illustrates the checkpoint process:
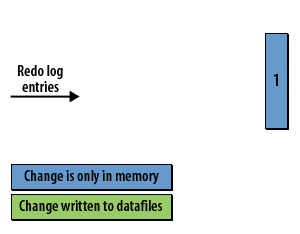
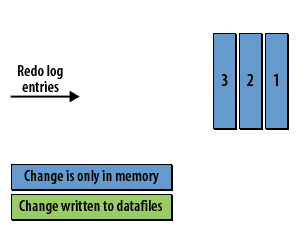
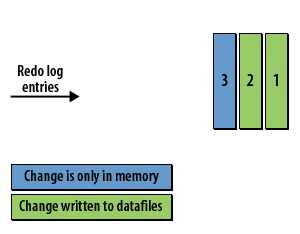
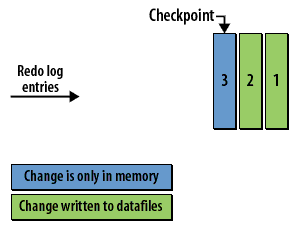
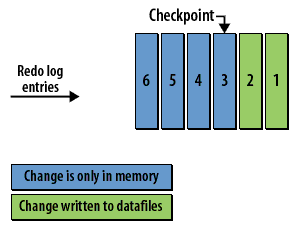
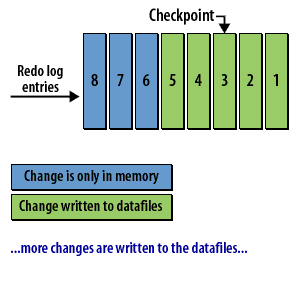
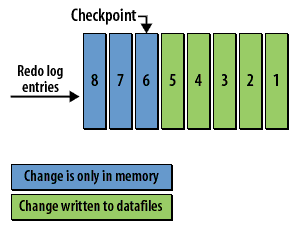
Checkpoint Concepts
- The checkpoint and data recovery: The checkpoint is critical for database recovery. It identifies the first redo log entry that Oracle will need to process in a recovery situation, as all changes related to previous redo log entries have been written to the datafiles on disk.
- Checkpoint Process (CKPT): During a checkpoint, the CKPT process updates the headers of all datafiles and the control file to record the checkpoint details. The CKPT process does not write data blocks to disk; this is handled by the DBWR process. The statistic DBWR checkpoints in Enterprise Manager indicates the number of checkpoint requests completed.