| Lesson 10 | Oracle cycles through redo logs |
| Objective | Explain how Oracle writes redo to groups, performs log switches, and reuses log files safely. |
How Oracle Cycles Through Online Redo Logs
Oracle writes change records (redo) to one redo log group at a time. Each group may have multiple members (multiplexed copies). When the active group fills, Oracle performs a log switch to the next group, and—after all groups are used—returns to the first group and reuses it once it is safe. This looping pattern continues for the life of the database.
Step-by-step: cycling across groups
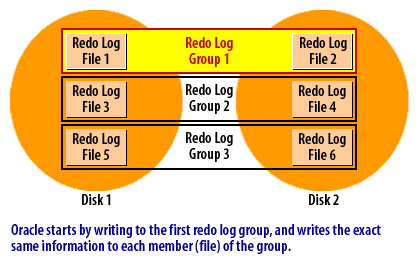
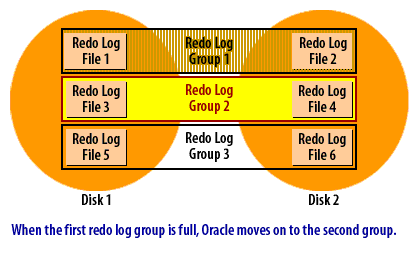
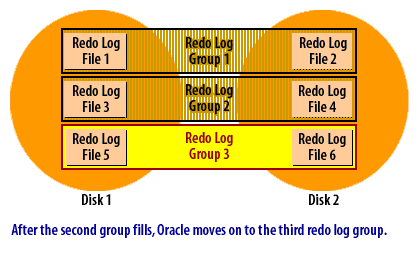
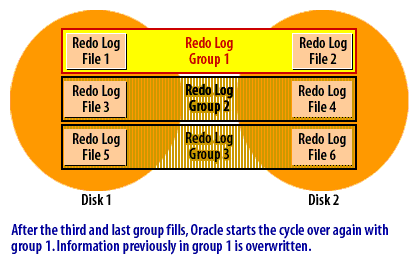
Why multiple groups are required
You need at least two groups. Oracle cannot overwrite the group it just filled because those redo records may still be needed for recovery or archiving. With two or more groups, LGWR can continue writing to the next group while background processes checkpoint and archive previous groups as needed.
What makes a log switch "safe"?
Before Oracle can reuse a group, two conditions must hold:
- Checkpoint progress: All data blocks protected by redo in the candidate group have been written to datafiles up to the relevant change number (SCN).
- Archiving (if ARCHIVELOG): The group has been successfully archived so media recovery remains possible.
Oracle Cloud DBA
Checkpointing in context
A checkpoint records that dirty buffers have been written to datafiles up to a specific SCN. It bounds how much redo must be processed during recovery and influences when a full group becomes reusable.
- LGWR writes redo sequentially to the current group.
- DBWR writes dirty data blocks to datafiles asynchronously.
- CKPT signals checkpoints and updates control file / datafile headers.
Sizing and switch cadence
Aim for a steady switch cadence aligned with your workload and backup strategy (often on the order of 15–30 minutes during peaks, then tune). Too-small logs cause frequent switches and checkpoints; too-large logs can prolong crash recovery and delay archiving.
Inspecting current layout and history
Which groups exist, and which is current?
SELECT l.group#, l.sequence#, l.bytes/1024/1024 AS size_mb,
l.members, l.archived, l.status
FROM v$log l
ORDER BY l.group#;
What are the member files (paths) for each group?
SELECT lf.group#, lf.member, lf.status
FROM v$logfile lf
ORDER BY lf.group#, lf.member;
How often do we switch (useful for sizing)?
SELECT sequence#, first_time, next_time
FROM v$log_history
ORDER BY first_time DESC
FETCH FIRST 30 ROWS ONLY;
Operational tips
- Multiplex members: ≥2 members per group on separate devices (or ASM failure groups) to tolerate single-file loss.
- ARCHIVELOG + FRA: Ensure archiving keeps up; monitor FRA usage to avoid stalls.
- Alerting: Warn on rapid switches, archiver errors, invalid log members, or FRA > 85% full.
Key takeaways
- Oracle writes to one redo group at a time and cycles through groups.
- Reuse of a full group requires checkpoint completion and, in ARCHIVELOG, successful archiving.
- Right-sized logs, proper multiplexing, and healthy archiving keep switches smooth and recovery reliable.