Oracle Redo Log Process
- Data blocks are read into memory from disk.
- Records are deleted from the blocks in memory.
- A record of each deletion is written to the redo log.
- A commit record is written to the redo log.
- The transaction ends successfully.
The process is the same regardless of whether you are inserting, updating, or deleting data. From a redo log perspective,
all of these actions result simply in changes to one or more blocks.
How Oracle uses the redo logs
Once Oracle fills one redo logfile, it automatically begins to use the next logfile.
When the server cycles through all the available redo logfiles, it returns to the first one and
reuses it. Oracle keeps track of the different redo logs by using a redo log sequence number. This sequence number is recorded inside the redo logfiles as they are used.
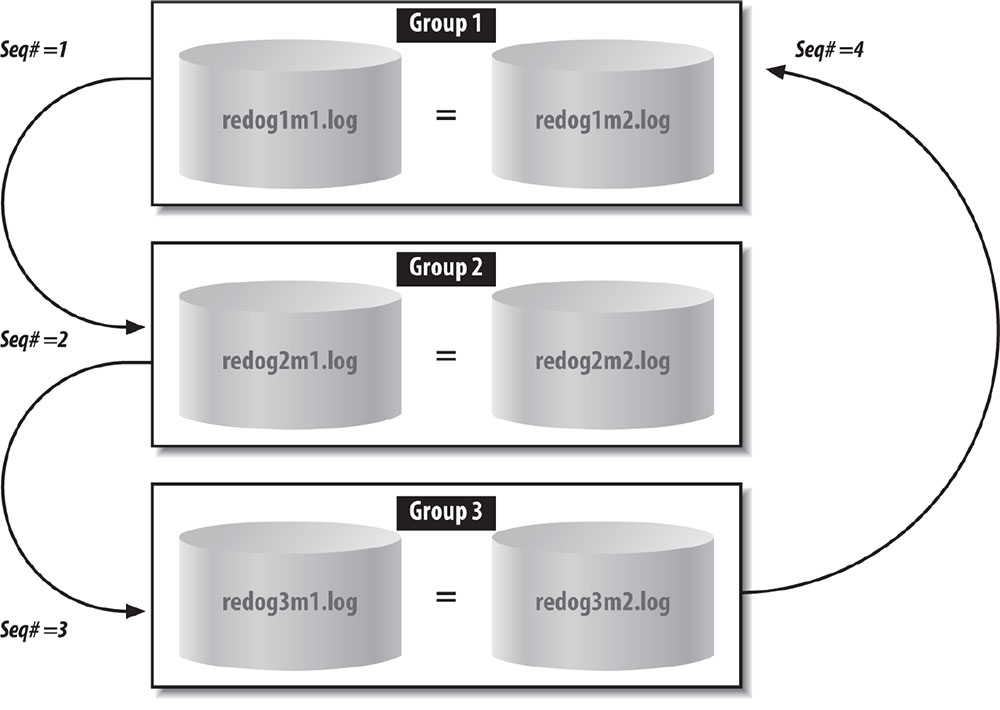
To understand the concepts of redo log filenames and redo log sequence numbers, consider three redo logfiles called redolog1.log, redolog2.log, and redolog3.log. The first time Oracle uses them, the redo log sequence numbers for each will be 1, 2, and 3, respectively. When Oracle returns to the first redo log, redolog1.log, it will reuse it and assign it a sequence number of 4. When it moves to redolog2.log, it will initialize that file with a sequence number of 5.
Remember that the operating system uses the redo logfile to identify the physical file, while Oracle uses the redo logfile sequence number to determine the order in which the logs were filled and cycled. Because Oracle automatically reuses redo logfiles, the name of the redo logfile is not necessarily indicative of its place in the redo logfile sequence.
To understand the concepts of redo log filenames and redo log sequence numbers, consider three redo logfiles called redolog1.log, redolog2.log, and redolog3.log. The first time Oracle uses them, the redo log sequence numbers for each will be 1, 2, and 3, respectively. When Oracle returns to the first redo log, redolog1.log, it will reuse it and assign it a sequence number of 4. When it moves to redolog2.log, it will initialize that file with a sequence number of 5.
Remember that the operating system uses the redo logfile to identify the physical file, while Oracle uses the redo logfile sequence number to determine the order in which the logs were filled and cycled. Because Oracle automatically reuses redo logfiles, the name of the redo logfile is not necessarily indicative of its place in the redo logfile sequence.