| Lesson 5 | Replication and Distribution as Elements of Database Design |
| Objective | Explain why Replication and Distribution are now viable Elements of Database Design |
Why Replication and Distribution Are Now Viable Elements of Database Design
Prior to the advent of inexpensive hard disks in the 1980s, minimizing redundant data was a fundamental database design requirement. Storage was expensive, replication was a luxury that few organizations could afford, and distributed processing was rare. A single mainframe held all organizational data in one place, and the idea of deliberately maintaining multiple copies of the same data across geographically distributed nodes would have been considered wasteful and operationally unmanageable.
That constraint no longer exists. In 2026, five converging drivers have made replication and distribution not just viable but the preferred architecture for enterprise Oracle deployments. Understanding these drivers — and the technical mechanisms that implement replication and distribution in Oracle Database 23ai — is essential for any DBA or architect designing systems that must scale, survive failures, and comply with data sovereignty requirements.
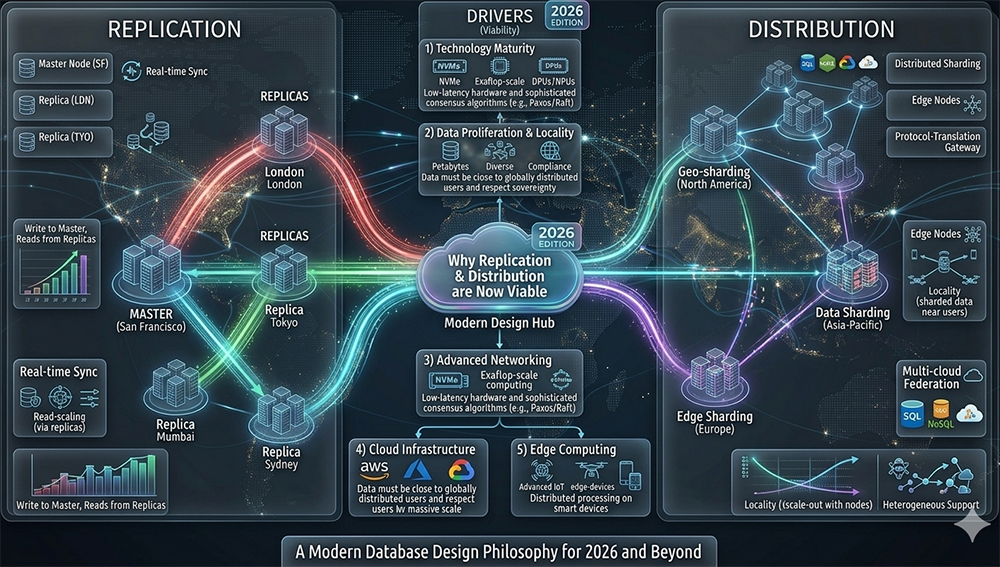
The Five Drivers That Made Replication and Distribution Viable
Driver 1 — Technology Maturity
The hardware and algorithm foundations that replication and distribution require have matured to the point where they are commodity rather than research-grade technology. NVMe storage delivers sub-millisecond random read latency — eliminating the disk I/O bottleneck that made synchronous replication prohibitively expensive in the spinning-disk era. Exaflop-scale computing provides the raw processing power to execute distributed transactions and consensus algorithms without degrading application response time. DPUs (Data Processing Units) and NPUs (Neural Processing Units) offload network processing from the main CPU, reducing the overhead of maintaining multiple replica connections simultaneously.
Perhaps most significantly, distributed consensus algorithms — Paxos and Raft in particular — have become both well-understood and widely implemented. These algorithms allow a cluster of database nodes to agree on the order of committed transactions even when some nodes fail or network partitions occur. Oracle's implementation of Raft-based consensus in Oracle Database 23ai provides a mathematically proven correctness guarantee for replicated data that earlier replication mechanisms — including Oracle's own snapshot replication — could not offer.
Driver 2 — Data Proliferation and Locality
Enterprise data volumes have grown to petabyte scale in organizations of all sizes. At petabyte scale, centralizing all data in a single database in a single location creates latency problems for globally distributed users and compliance problems for data sovereignty regulations. The European Union's GDPR, Brazil's LGPD, China's PIPL, and a growing number of national data residency laws require that personal data about citizens be stored within specific geographic boundaries.
Distribution is no longer a performance optimization — it is a legal requirement for organizations operating across multiple jurisdictions. Oracle's geo-sharding capability in OCI places data shards in specific OCI regions based on data classification rules, ensuring that European customer data remains in the EU Frankfurt or Amsterdam region while Asia-Pacific customer data resides in the Singapore or Tokyo region. This is not achievable with a centralized single-region database.
Driver 3 — Advanced Networking
The network latency that made synchronous replication impractical in the WAN era of Oracle 11g R2 has been dramatically reduced by OCI's private backbone network. Traffic between OCI regions travels over Oracle's dedicated fiber network rather than the public internet, providing consistent low-latency connections between regions. Oracle's FastConnect provides dedicated private connectivity between on-premises data centers and OCI regions, replacing the variable-latency T1 and T3 circuits that connected 11g R2 Data Guard configurations.
The combination of NVMe-based storage, Exaflop-scale compute, and low-latency backbone networking makes synchronous redo log shipping between an Oracle Active Data Guard primary in OCI US East and a standby in OCI EU Frankfurt practical at transaction rates that would have saturated a T3 circuit in the 11g R2 era.
Driver 4 — Cloud Infrastructure
AWS, Google Cloud Platform, and Oracle Cloud Infrastructure have industrialized the provisioning of distributed database infrastructure. What required weeks of hardware procurement, rack installation, network cabling, and OS configuration in the on-premises era can now be provisioned through API calls in minutes. A new OCI region can host a standby Oracle database that is fully synchronized with a primary database in a different region within hours of provisioning — no physical infrastructure decisions required.
Cloud infrastructure also eliminates the capital expenditure barrier that prevented smaller organizations from implementing distributed database architectures. In the Oracle 11g R2 on-premises era, a geographically distributed Active Data Guard configuration required duplicate hardware investment at the standby site. In OCI, the standby database is provisioned on demand and billed per hour — bringing enterprise-grade distribution within reach of organizations that could never have justified the on-premises capital cost.
Driver 5 — Edge Computing
The proliferation of IoT devices, edge computing nodes, and smart devices has created a new tier of distributed database deployment at the network edge. Oracle's Mission Critical at the Edge offering deploys autonomous Oracle database instances on edge hardware — manufacturing floor controllers, retail point-of-sale systems, telecommunications network nodes — that operate with local autonomy when WAN connectivity is unavailable. Data generated at the edge is processed locally and synchronized with the central OCI database when connectivity is restored.
This edge tier makes distribution a physical necessity rather than an architectural choice. Data that is generated on a factory floor in real time cannot wait for a round-trip to a central data center before it is processed — the latency would render real-time control impossible. Edge distribution is the only viable architecture for IoT-scale data processing.
Replication — Write to Master, Read from Replicas
The diagram's replication panel shows the fundamental Oracle replication pattern: a Master Node in San Francisco accepts all writes, with replicas in London, Tokyo, Mumbai, and Sydney serving read traffic. This write-to-master, read-from-replicas architecture is the standard pattern for Oracle Active Data Guard in OCI — all DML (INSERT, UPDATE, DELETE) executes on the primary database and the redo stream is shipped to standbys in real time. Read queries can be offloaded to any standby replica, distributing the read load across all participating regions.
Oracle replication in 2026 spans a spectrum from synchronous to asynchronous, each with different consistency and performance tradeoffs:
- Synchronous replication (Eager Replication): The transaction does not commit on the primary until the redo data has been written to the standby redo log and acknowledged. This guarantees zero data loss (RPO = 0) but adds the round-trip latency to the standby to every transaction's commit path. Oracle Active Data Guard Maximum Protection mode implements synchronous replication. The low-latency OCI backbone makes synchronous replication between nearby OCI regions practical — within-region latency is typically under 1ms, and between-region latency on OCI's private network is significantly lower than equivalent WAN circuit latency in the 11g R2 era.
- Asynchronous replication (Lazy Replication): The transaction commits on the primary without waiting for standby acknowledgment. The redo stream is shipped to standbys asynchronously, meaning a brief window of potential data loss exists if the primary fails before the redo ships. Oracle Active Data Guard Maximum Performance mode implements asynchronous replication. This mode is appropriate for geographically distant standbys where synchronous replication latency would unacceptably degrade primary transaction throughput.
The original asynchronous replication mechanisms in Oracle — Lazy Group Replication and Lazy Master Replication — used timestamp-based conflict detection to reconcile concurrent updates at different nodes. In Lazy Group Replication, any node can update local data and broadcast the update to all peers. Conflict detection compares the incoming update's old-timestamp tag against the current replica timestamp — if they match, the update is safe; if they diverge, the update is flagged as potentially dangerous and queued for reconciliation. In Lazy Master Replication, a designated master node owns each object and all updates are first applied at the master before being propagated to slave replicas in sequential commit order, providing a simpler consistency model at the cost of master node availability becoming the bottleneck.
Oracle GoldenGate — the modern implementation of bidirectional replication — supersedes both patterns with a capture-and-apply architecture that extracts committed transactions from the Oracle redo log and applies them to target databases with sub-second latency. GoldenGate supports heterogeneous replication between Oracle and non-Oracle databases, enabling the multi-cloud federation patterns visible in the diagram's distribution panel.
Distribution Strategies — Horizontal and Vertical Partitioning
The four fundamental strategies for distributing a database across nodes are:
- Data replication: Complete or partial copies of tables maintained at multiple sites. Provides read scalability and fault tolerance at the cost of storage overhead and consistency management. Oracle Active Data Guard implements full database replication; Oracle GoldenGate implements selective table replication.
- Horizontal partitioning (sharding): Rows of a table are distributed across nodes based on a partition key — typically a geographic or customer identifier. A customer table in a global bank might be horizontally partitioned so that North American customers reside in an OCI US East shard, European customers in an OCI EU Frankfurt shard, and Asia-Pacific customers in an OCI AP Tokyo shard. Oracle Sharding implements horizontal partitioning natively, with the Oracle Global Data Services layer routing queries to the correct shard transparently.
- Vertical partitioning: Different columns of a table are stored at different nodes. Less common than horizontal partitioning but useful when different parts of a row have very different access patterns or data sensitivity classifications — separating PII columns to a higher-security shard while keeping non-sensitive columns in a lower-security shard.
- Combinations: Production Oracle Sharding deployments typically combine horizontal partitioning with replication — each shard has a primary in one OCI region and a standby in a different region, providing both geographic distribution for data locality and replication for fault tolerance.
Modern Oracle Distribution — Geo-Sharding and Edge Sharding
The diagram's distribution panel shows three tiers of Oracle distribution at enterprise scale in 2026. Geo-sharding in North America places data shards in OCI US regions based on customer geography, meeting US data residency requirements. Data Sharding in Asia-Pacific distributes shards across OCI Singapore, Tokyo, and Sydney regions for customers in those markets. Edge Sharding in Europe places shards in OCI EU regions to meet GDPR data residency requirements.
All three tiers connect through the Protocol-Translation Gateway — Oracle's equivalent of the Connection Manager (CMAN) that handles protocol translation between different network segments. In OCI, this function is implemented by the OCI Load Balancer and Oracle Connection Manager working in combination, routing application connections to the appropriate shard based on connection string parameters and data routing rules defined in the Oracle Global Data Services catalog.
Multi-cloud Federation — shown in the bottom-right panel — extends this distribution beyond OCI to heterogeneous cloud and on-premises environments. Oracle GoldenGate connects Oracle shards with non-Oracle databases across AWS RDS, Google Cloud SQL, and on-premises MySQL or PostgreSQL deployments, providing a unified logical database view across a heterogeneous distributed environment.
Summary
Replication and distribution became viable elements of Oracle database design because five converging drivers eliminated the constraints that made them impractical in the mainframe and 11g R2 eras: NVMe storage and Paxos/Raft consensus algorithms addressed the performance and correctness barriers; data sovereignty regulations made geographic distribution legally required; OCI's private backbone network made synchronous replication across regions practical; cloud infrastructure made distributed deployments economically accessible; and edge computing made distribution physically necessary for IoT-scale workloads. Oracle implements replication through Active Data Guard and GoldenGate, and distribution through Oracle Sharding with geo-sharding, edge sharding, and multi-cloud federation. The next lesson examines the specific features of distributed databases that make these architectures function as single logical systems despite their physical distribution.