| Lesson 2 | The History of Networking |
| Objective | Explain the Evolution from Centralized to Decentralized Computers |
Evolution from Centralized to Decentralized Computers
The decentralized, distributed computing environment that defines modern enterprise IT is a relatively recent phenomenon. For most of computing history, data and processing were centralized — one large machine, one database, all users sharing the same CPU. The client/server revolution of the late 1980s began the shift toward distribution. Cloud computing and Oracle Cloud Infrastructure have completed it. Understanding this evolution is essential for understanding why Oracle networking exists — it was built specifically to connect distributed databases that could not otherwise communicate.
The client/server model does much more than distribute data across a network. One of the foremost reasons for adopting it is to share the processing load. A single overloaded CPU creates a single point of failure that can cripple an entire organization. Distribution addresses both the performance ceiling and the reliability problem simultaneously.
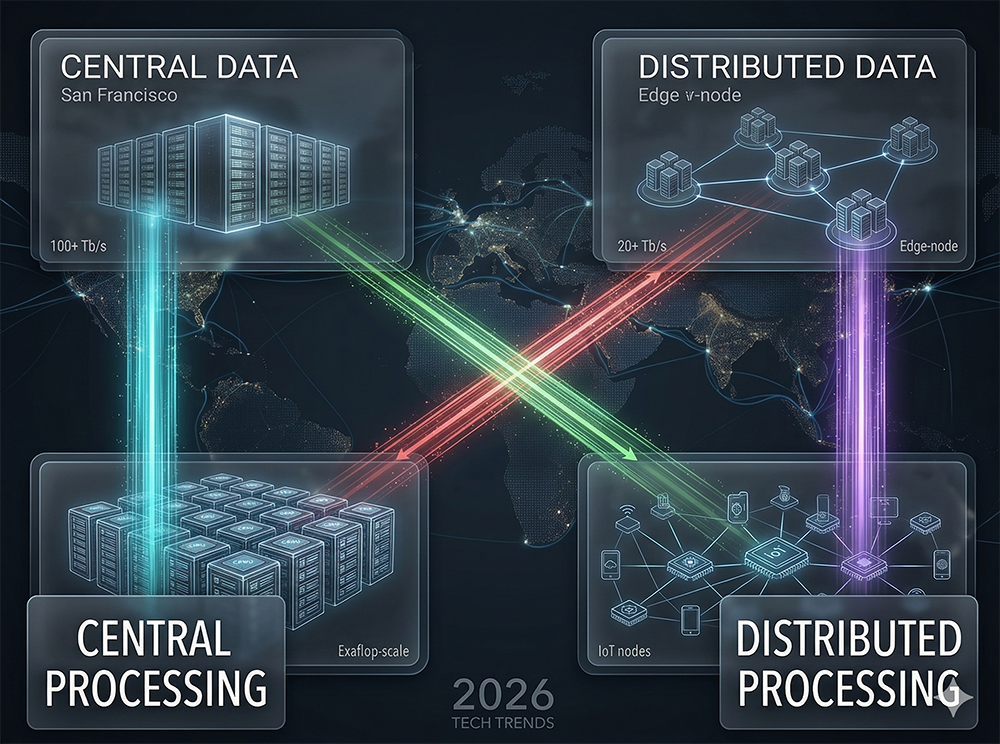
Quadrant 1 — Centralized Data, Centralized Processing
The traditional approach to Oracle data places all data in a single database and performs all processing on a centralized computer — historically a large UNIX server or mainframe. This model offers strong control over data consistency, backup, and security, but introduces two significant liabilities that drove the move toward distribution.
The first liability is performance degradation. When a single CPU becomes overloaded, every user connected to that system experiences degraded response time simultaneously. There is no horizontal scaling option — you can only scale up by replacing the hardware.
The second liability is the single point of failure. If the central CPU fails, the entire system becomes unavailable. No redundancy exists at the compute layer. For organizations where database availability is critical — financial systems, order processing, healthcare records — this risk is unacceptable.
A centralized database (sometimes abbreviated CDB in older Oracle documentation, though note that CDB now refers to Container Database in Oracle 12c and later) is located, stored, and maintained in a single location. All users access it through a computer network that connects them to the central CPU. While this provides a significant advantage in terms of data governance and a single authoritative source of truth, the single-location constraint limits both scalability and resilience.
In Oracle Cloud Infrastructure, the equivalent of centralized data with centralized processing is Oracle Autonomous Database — a single logical database endpoint managed entirely by Oracle, with compute and storage scaling handled transparently. The fundamental data management simplicity of centralization is preserved while the hardware single-point-of-failure is eliminated through OCI's multi-availability-domain infrastructure.
Quadrant 2 — Centralized Data, Distributed Processing
This configuration centralizes the data in one controlled environment while distributing the processing across a network of remote CPUs. The data resides in a single Oracle database, but multiple application servers or processing nodes connect to it to execute queries and transactions in parallel. The main advantage is control over the data — backup, recovery, and security policies apply to a single database. The main disadvantage is that the Oracle database itself becomes a single point of failure and a potential bottleneck as the number of processing nodes grows.
Oracle implemented this approach historically with Oracle Parallel Server (OPS). OPS allowed two or more database instances on different machines to open and manipulate a single shared database — the physical data files resided on shared storage accessible by all instances. OPS required an operating system that supported clustering and a distributed lock manager to coordinate data access between instances. If a user on instance A updated a row and a user on instance B queried that row, instance B had to instruct instance A to write the updated data to disk before the query could return the correct value. This disk-based coordination mechanism was OPS's fundamental performance limitation.
OPS was superseded by Real Application Clusters (RAC) in Oracle 9i. RAC introduced Cache Fusion — a mechanism allowing instances to share data blocks directly in memory across the cluster interconnect rather than requiring disk writes for cross-instance coordination. This eliminated the primary performance bottleneck of OPS. RAC also introduced enhanced cluster interconnect support using faster InfiniBand and dedicated Ethernet technologies, and greater flexibility in supported operating systems and hardware platforms.
Beyond RAC, Oracle introduced complementary technologies:
- In-Memory Parallel Execution (IMPX): Leverages the Shared Global Area (SGA) to store data for subsequent parallel processing across cluster nodes, improving performance for large-scale analytical workloads where the data set fits in the aggregate cluster memory.
- Grid Infrastructure: A unified infrastructure layer for managing multiple databases and clusters, providing cluster services, volume management, and automatic storage management (ASM) in a single administrative framework.
- Oracle RAC on OCI Exadata: The modern evolution of centralized data with distributed processing — Exadata provides shared storage with extreme I/O bandwidth while RAC provides multiple database instances accessing that storage. In OCI, this is delivered as a managed service without the hardware procurement and cluster management burden.
Quadrant 3 — Distributed Data, Centralized Processing
This approach distributes the data across geographically separate locations while centralizing the processing in one large system. Remote data hubs store data close to where it is generated or consumed, but a central processor executes all queries and transactions — reaching out to the remote nodes as needed. The proximity of data to users reduces network latency for data retrieval. The disadvantage is that the central processor becomes the performance bottleneck and the single point of failure for processing, while the distributed data creates complexity for backup and recovery operations.
This is the standard configuration for Oracle Network Services in its traditional form. Oracle Net connects the central processing node to remote data servers through TNS service names and database links. A distributed query executes at the node where the user is connected, partitioning sub-queries to their respective host processors and assembling the results. Oracle implements distributed queries using database links — covered in detail in Lessons 8 and 9 of this module.
In the modern OCI model, this quadrant maps to scenarios where a central Oracle Autonomous Database processes queries against data that has been distributed across Oracle Object Storage buckets or federated through PolyBase-equivalent capabilities — querying external data sources without moving the data into the central database.
Quadrant 4 — Distributed Data, Distributed Processing
This is the approach used by most modern Oracle deployments — both data and processing are distributed across a network. The primary advantage is the ability to assign both data and compute resources on an as-needed basis, matching processing power to data locality and workload demand. The primary challenge is coordinating backup and recovery across all distributed nodes and ensuring data consistency when updates occur at multiple sites simultaneously.
Oracle implements distributed data with distributed processing through Oracle Net Services interfacing to remote databases, supplemented by Oracle GoldenGate for real-time replication and Oracle Data Guard for high availability. In OCI, this quadrant is represented by multi-region Active Data Guard deployments where primary and standby databases exist in different OCI regions, each capable of independent processing — the standby accepting read queries while the primary processes writes.
Distributed query performance is a critical design concern in this quadrant. The optimization of distributed queries is vital — a poor execution plan can take orders of magnitude longer than the optimal plan. A query that generates a large intermediate result set should never ship that result set over the network to join with a small table at a remote site. Oracle's query optimizer accounts for network transmission costs when generating execution plans for distributed queries, but DBA awareness of data locality remains essential for tuning.
Distributed Database Environments — Taxonomy
The range of distributed database configurations can be classified along two primary dimensions: homogeneous versus heterogeneous, and autonomous versus nonautonomous. The following diagram illustrates the full taxonomy of distributed database environments as understood in 2026.
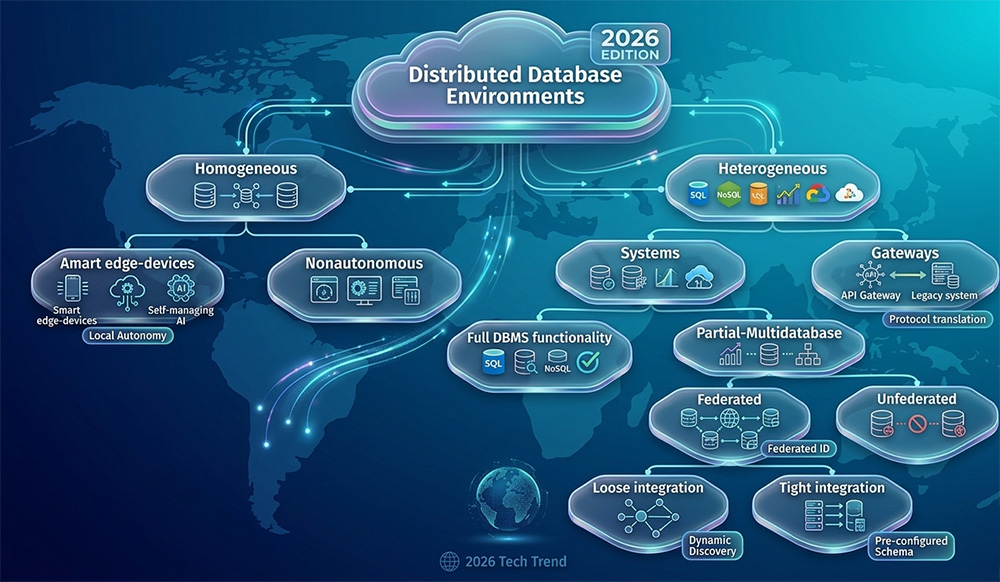
Homogeneous Distributed Databases
A homogeneous distributed database uses the same DBMS at every node. In Oracle's context this means Oracle Database at every site — the configuration that Oracle Network Services was designed to support. Two sub-types exist:
- Autonomous: Each DBMS works independently, passing messages to share data updates. Sites are aware of each other but retain the right to change their own schemas and software independently. Oracle GoldenGate replication between autonomous Oracle databases is the modern implementation of this pattern.
- Nonautonomous: A central or master DBMS coordinates database access and updates across all nodes. Sites surrender some autonomy in exchange for tighter consistency guarantees. Oracle RAC with a primary database and read-only standby replicas follows this pattern.
In 2026, homogeneous distributed databases also encompass smart edge-device deployments — autonomous Oracle database instances running on edge nodes with local autonomy, synchronizing with a central OCI database when connectivity allows. Oracle's Mission Critical at the Edge offering targets exactly this pattern for industrial IoT, retail, and telecommunications use cases.
Heterogeneous Distributed Databases
A heterogeneous distributed database uses different database systems at different nodes — Oracle at headquarters, MySQL at branch offices, MongoDB for document storage, and Snowflake for analytics, all participating in a unified logical data environment. This is the reality of most enterprise data architectures in 2026.
The challenges of heterogeneous distribution are significant. Schema differences between nodes create query processing complexity, a join between an Oracle relational table and a MongoDB document collection requires translation at the query level. Software differences between nodes complicate transaction processing — two-phase commit across different database systems requires careful coordination and is not universally supported. Sites may have limited awareness of each other and provide only partial cooperation in distributed transactions.
Oracle addresses heterogeneous distribution through Oracle Database Gateway products — transparent gateways that make non-Oracle databases appear as Oracle databases to the application layer. In OCI, the equivalent is Oracle Data Integrator and Oracle GoldenGate, which provide bidirectional replication between Oracle and heterogeneous sources including MySQL, PostgreSQL, SQL Server, Kafka, and cloud data warehouses.
Managing Distributed Databases — Then and Now
During the 1990s, the volatile nature of corporate computing created widespread challenges in managing distributed database systems spanning geographical areas, hardware platforms, and database architectures. Corporations embraced downsizing — moving from expensive mainframes to cheaper UNIX servers — and rightsizing — matching hardware capacity to actual workload — creating diverse islands of information spread across many disconnected networks. Oracle Network Services emerged as the solution for linking these islands into a coherent distributed system.
In 2026, the distributed database management challenge has shifted from physical connectivity to operational governance. The physical network is largely solved by OCI's Virtual Cloud Network, FastConnect for on-premises connectivity, and software-defined networking. The remaining challenges are data consistency across regions, identity and access management across heterogeneous systems, compliance with data residency regulations, and cost optimization of distributed query execution across cloud services that charge for egress.
Oracle addresses these modern distributed management challenges through OCI Data Catalog for metadata governance, OCI IAM for unified identity across all services, Oracle Audit Vault and Database Firewall for compliance monitoring, and the Oracle Cloud Cost Management console for optimizing distributed query costs across OCI regions.
Summary
The evolution from centralized to decentralized computing reflects the economic and technical pressures that have shaped enterprise IT for five decades. Centralized data with centralized processing offered simplicity but created performance ceilings and single points of failure. Distributed processing with centralized data — implemented through Oracle Parallel Server and its successor RAC — addressed the performance ceiling while retaining data governance. Distributed data with centralized processing — the standard Oracle Network Services model — brought data closer to users while maintaining processing control. Distributed data with distributed processing — the modern OCI multi-region model — provides maximum flexibility at the cost of coordination complexity. Oracle Net Services connects all four quadrants, and Oracle Cloud Infrastructure has extended that connectivity into a globally distributed, software-defined network where the physical location of data and processing is increasingly transparent to the application. The next lesson examines the evolution of the network protocols that make this distributed connectivity possible.