| Lesson 4 | Oracle Networks for Distributed Computers |
| Objective | Describe the Evolution of Databases from Centralized to Distributed |
Evolution of Databases from Centralized to Distributed
The evolution of database architectures across six decades mirrors the evolution of computing itself — from a single mainframe in a locked room accessible only by dumb terminals, to a globally distributed federated system spanning cloud regions, edge nodes, and IoT devices. Understanding this progression explains why Oracle Network Services exists, why Oracle Net was designed the way it was, and why the modern OCI networking model represents such a departure from the on-premises configurations that preceded it.
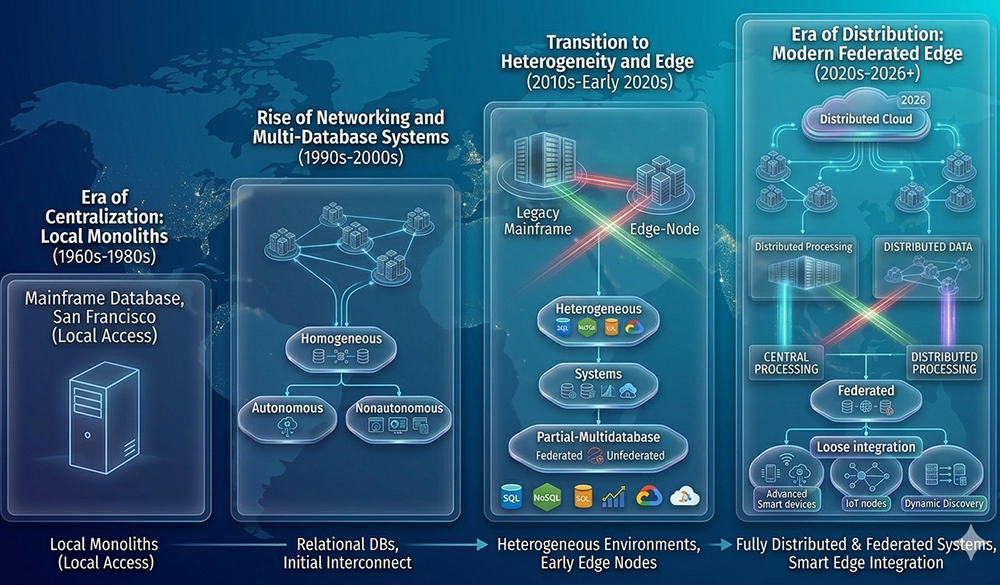
Generation 1 — Era of Centralization: Local Monoliths (1960s–1980s)
The first generation of serious business databases were monolithic systems[1] running on one large machine — a mainframe — accessed exclusively by dumb terminals that performed no local processing. All data resided in a single location. All computation occurred on the central processor. Users at remote desks were connected by dedicated serial lines to terminal controllers that passed keystrokes to the mainframe and displayed responses on character-based screens.
The advantages of this model were significant: tight control over data security and access, single-unit backup and recovery, and centrally enforced business rules. A single authoritative source of truth for all organizational data was a genuine architectural benefit that distributed systems would spend decades trying to replicate.
The disadvantages were equally significant: the mainframe was a single point of failure at both the compute and data layers. When the CPU failed, the entire organization lost access to its data. When the CPU became overloaded, every user experienced degraded response simultaneously. Scaling required replacing the entire machine — there was no horizontal scaling option. And the cost of mainframe compute time made interactive query execution prohibitively expensive for many use cases.
Oracle's origins in 1977 placed it squarely in this era. Oracle Database version 1 ran on a DEC PDP-11 — a minicomputer that was the era's affordable alternative to mainframes. The networking challenge of this generation was not distribution but connectivity — how to get terminal users connected to the single central machine across building-scale and campus-scale distances.
There are five major developmental trends that affect the current nature of distributed databases.
Generation 2 — Rise of Networking and Multi-Database Systems (1990s–2000s)
Between 1987 and 1988, Oracle Corporation moved first the client function and then the database server from minicomputers to microcomputers and Local Area Networks. This was the client/server revolution — the most significant architectural shift in enterprise computing since the introduction of the mainframe. A client application running on one machine could now issue queries to a database server running on a separate machine connected through a LAN.
The five developmental trends that define this generation, each succeeding and improving on the one before it:
- 1960s — Monolithic databases: Single-machine, single-instance, terminal access only
- 1970s — Distributed databases: Early research and experimental multi-site database systems; ARPA network providing the first distributed computing infrastructure
- 1980s — Personal databases: Database software moving to microcomputers; dBASE, FoxPro, and early desktop Oracle creating isolated data islands
- 1980s — Networks of databases: LANs connecting PC databases; Novell NetWare providing shared file access; Oracle moving to client/server architecture on LANs
- 1990s — Networked networks of databases: WAN connectivity linking geographically distributed Oracle databases; SQL*Net enabling inter-database communication; the internet providing the ultimate distributed computing infrastructure
The networking topology of this generation was homogeneous — all sites ran the same Oracle Database version, connected through Oracle Net Services using tnsnames.ora service name resolution. The Autonomous sub-type of homogeneous distribution — where each Oracle database instance operated independently while exchanging data updates with peers — was implemented through Oracle's snapshot replication and database links. The Nonautonomous sub-type — where a master database coordinated access across all nodes — was implemented through Oracle Parallel Server and later Real Application Clusters.
The internet's emergence as a distributed computing infrastructure in the mid-1990s was the ultimate expression of this generation. With tens of thousands of connected computers and new nodes joining daily, the internet demonstrated that distributed data at global scale was achievable. Oracle Network Services provided the connectivity layer that allowed Oracle databases to participate in this distributed world while maintaining the transactional integrity guarantees that enterprise applications required.
Generation 3 — Transition to Heterogeneity and Edge (2010s–Early 2020s)
The third generation broke the homogeneous assumption of Generation 2. Enterprise data environments in the 2010s were no longer exclusively Oracle — MySQL, PostgreSQL, MongoDB, Cassandra, Hadoop, and cloud data warehouses all coexisted in the same organizations. The database landscape became heterogeneous: different sites used different schemas, different software, and different query languages. Legacy mainframes persisted for transaction processing while edge nodes handled local data collection and analytics.
The distributed database taxonomy of this generation reflects the heterogeneous complexity:
- Heterogeneous systems: Environments where different DBMS types — SQL relational, NoSQL document, column-store, and cloud-native — participate in a unified logical data environment. Schema differences create query processing complexity; software differences complicate transaction management. Oracle Database Gateway products addressed this by making non-Oracle databases appear as Oracle to the application layer.
- Partial-Multidatabase: Systems that support some but not all of the functionality of a unified logical database. Federated architectures — where sites retain local autonomy but share a common identity — and unfederated architectures — where sites operate with no shared identity framework — emerged as distinct patterns.
- Early edge nodes: The emergence of IoT and mobile computing created the first wave of edge database deployments — Oracle Database Lite and later Oracle Mobile Server providing Oracle connectivity to devices operating intermittently connected to the central enterprise database.
Oracle GoldenGate became the primary tool for heterogeneous distribution in this generation — providing real-time bidirectional replication between Oracle and non-Oracle databases including MySQL, SQL Server, PostgreSQL, and Kafka. The distributed database was no longer necessarily an all-Oracle environment.
Generation 4 — Era of Distribution: Modern Federated Edge (2020s–2026)
The fourth generation — the current era — completes the evolution that the mainframe-to-LAN shift began in the 1980s. Data and processing are now fully distributed across a hierarchy of compute environments: distributed cloud at the top, regional processing nodes in the middle, and IoT devices and smart edge systems at the base. No single node is the authoritative center — distribution is the architecture, not an optimization.
The Nano Banana 2 image captures the key characteristics of this generation:
- Distributed Cloud (2026): Oracle Cloud Infrastructure provides the top-level distributed cloud layer — multiple OCI regions globally, each capable of hosting primary or standby Oracle database instances. Active Data Guard multi-region configurations provide active-active read capability with automatic failover, eliminating the single-region dependency of Generation 3 deployments.
- Distributed Processing and Distributed Data: The four-quadrant model from Lesson 2 is now the default architecture rather than an advanced configuration. Central processing and distributed processing coexist in the same deployment — Autonomous Database handles centralized OLTP workloads while distributed edge processing handles real-time analytics closer to the data source.
- Federated architecture with Loose Integration: Modern OCI deployments use OCI IAM as the federated identity layer — a single identity framework governing access across Oracle Database, Oracle Analytics, OCI Object Storage, and third-party services. Dynamic Discovery allows new nodes to join the federated environment without pre-configured schema agreements, supporting the rapid provisioning that cloud infrastructure enables.
- Advanced Smart Devices and IoT Nodes: Oracle's Mission Critical at the Edge offering deploys autonomous Oracle database instances on edge hardware — retail stores, manufacturing floors, telecommunications network nodes — that operate with local autonomy when connectivity is unavailable and synchronize with OCI when connection is restored. This closes the loop that the 1980s personal database era opened: compute and data at the edge, connected to a global distributed fabric.
The Distributed Database Defined
A distributed database is a single logical database that is spread physically across computers in multiple locations connected by a data communications network. This definition — established by C.J. Date in the 1980s — remains accurate in 2026. The key word is logical: to the application and to the user, a distributed database appears as a single coherent database regardless of how many physical nodes store its data.
Three properties distinguish a true distributed database from a loose collection of files or a set of independent databases:
- Transparent data access: A user at location A can query data at location B using
the same SQL syntax as local queries. Oracle implements this through database links and synonyms —
SELECT * FROM customer@londonreturns rows from the London database as transparently as a local table query. - Central administration with local flexibility: The distributed database is administered as a corporate resource — backup policies, security roles, and data retention rules apply across all nodes — while each site retains the ability to optimize for local workload characteristics. OCI's unified management console provides this centralized administration view across all regions and availability domains.
- Network-enabled sharing: Users and programs at any participating location can access and update data at any other location, subject to security permissions. Oracle Net Services provides the connectivity layer; Oracle Database's two-phase commit protocol ensures that distributed transactions maintain ACID properties across all participating nodes.
Advantages of Distributed Databases Over Centralized Systems
The failure of a single processor in a distributed network leaves all remaining database nodes intact and operational — the most compelling argument for distribution in enterprise environments where availability is a business requirement rather than a preference. Additional advantages include:
- Fault isolation: A hardware failure at one site does not cascade to other sites. Oracle Data Guard and Active Data Guard provide automatic failover when a primary database becomes unavailable, maintaining availability without manual intervention.
- Horizontal scalability: New nodes can be added to a distributed database to handle increased load without replacing existing hardware. Oracle RAC adds instances to an existing cluster; OCI Autonomous Database scales compute and storage independently through API calls.
- Data locality: Storing data close to where it is generated and consumed reduces network latency for the most frequent access patterns. A regional sales database stored in an OCI region close to the sales team's location delivers lower query response times than a centralized database on the other side of the world.
- Resilience to network partitions: A distributed database with appropriate replication can continue operating during network outages that would completely disable a centralized system dependent on a single WAN link.
Oracle Network — Quiz
Oracle Network — Quiz
Summary
The evolution of Oracle databases from centralized monoliths to modern federated edge systems spans four generations across six decades. Local monoliths gave way to networked relational databases as client/server architecture moved Oracle from mainframes to LANs. Networked databases gave way to heterogeneous distributed environments as NoSQL, cloud databases, and early edge nodes entered the enterprise. Heterogeneous environments have given way to the modern federated edge — fully distributed across cloud regions, processing nodes, and IoT devices with OCI IAM providing unified identity and Oracle Net Services providing the connectivity layer that has persisted across every generation. The next lesson examines the changing attitudes toward distributed data that drove each of these generational transitions.