Fact File: Table data
Visit the Pet Store directory to view the database tables in greater detail.
Pet Store Tables
Dimension in Data Warehousing
The term dimension in data warehousing is a collection of reference information about a measurable event. These events are stored in a fact table and are known as facts. The dimensions are generally the entities for which an organization wants to preserve records. The descriptive attributes are organized as columns in dimension tables by a data warehouse. For example, a student’s dimension attributes could consist of first and last name, roll number, age, gender, or an address dimension that would include street name, state, and country attributes.
Dimension Table
A dimension table consists of a primary key column that uniquely identifies each record (row) of dimension. A dimension is a framework that consists of one or more hierarchies that classify data. Usually dimensions are de-normalized tables and may have redundant data.
Let us take a quick recap of the concepts of normalization and de-normalization, as they will be used in this module.
Normalization is a process of breaking up a larger table into smaller tables free of any possible insertion, updation or deletion anomalies. Normalized tables have reduced redundancy of data. In order to get full information, these tables are usually joined. In de-normalization, smaller tables are merged to form larger tables to reduce joining operations. De-normalization is particularly performed in those cases where retrieval is a major requirement and insert, update, and delete operations are minimal, as in case of historical data or data warehouse. These de-normalized tables will have redundancy of data.
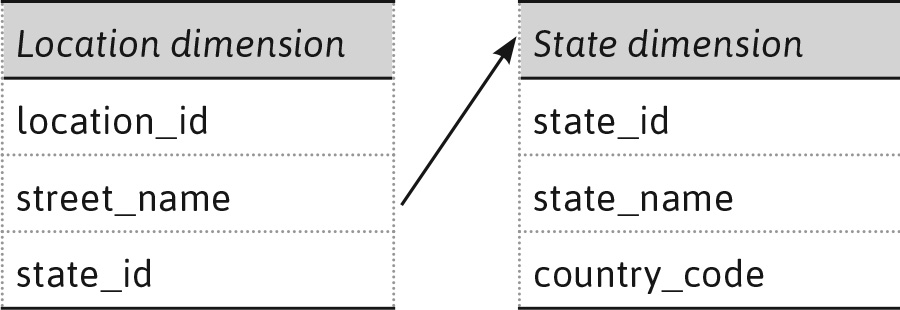
For example, in case of EMP-DEPT (employee-department) database, there will be two normalized tables as EMP(eno, ename, job, sal, deptno) and DEPT(deptno, dname), while in case of de-normalization we will have a single table EMP_DEPT with attributes [eno, ename, job, sal, deptno, dname]. Let us consider Location and Item dimensions as shown in Figure 3.4 a). Here, in Location dimension location_id is the primary key with street_name, city, state_id and country_code as its attributes. Figure 3.4 (b) shows another dimension namely Item having item_code as primary key and item_name, item_type, brand_name, and supplier_id as other attributes.
Normalization is a process of breaking up a larger table into smaller tables free of any possible insertion, updation or deletion anomalies. Normalized tables have reduced redundancy of data. In order to get full information, these tables are usually joined. In de-normalization, smaller tables are merged to form larger tables to reduce joining operations. De-normalization is particularly performed in those cases where retrieval is a major requirement and insert, update, and delete operations are minimal, as in case of historical data or data warehouse. These de-normalized tables will have redundancy of data.
For example, in case of EMP-DEPT (employee-department) database, there will be two normalized tables as EMP(eno, ename, job, sal, deptno) and DEPT(deptno, dname), while in case of de-normalization we will have a single table EMP_DEPT with attributes [eno, ename, job, sal, deptno, dname]. Let us consider Location and Item dimensions as shown in Figure 3.4 a). Here, in Location dimension location_id is the primary key with street_name, city, state_id and country_code as its attributes. Figure 3.4 (b) shows another dimension namely Item having item_code as primary key and item_name, item_type, brand_name, and supplier_id as other attributes.

It is important to note that these dimensions may be de-normalized tables as the location dimension may be derived from location_detail (location_id, street_name, state_id) and state_detail (state_id, state_name, country_code) tables as shown in the figure below.