| Lesson 2 | First Step in Normalization |
| Objective | Define normalization and recognize anomalies that it prevents. |
Database Normalization Defined
Normalization is a disciplined method for structuring tables so that each fact is stored once, updates are consistent, and queries remain reliable. You preserve the information captured during conceptual modeling (entities, attributes, relationships) while minimizing redundant storage and update anomalies.
- Design approach: Works with both top-down (start from the ERD) and bottom-up (start from attributes). In practice, teams blend both.
- Goal: Information preservation with minimal redundancy, leading to simpler maintenance and predictable behavior.
Insertion, Update, and Deletion Anomalies
Tables that combine multiple subjects or repeat groups typically suffer from:
- Insertion anomaly: You cannot add a fact because another, unrelated fact is missing (e.g., can’t add a new product until an order exists).
- Update anomaly: The same fact stored in many rows must be changed everywhere; if one row is missed, data diverges.
- Deletion anomaly: Removing one fact deletes another unintentionally (e.g., deleting a final line item also deletes the only copy of a customer address).
Visual Walkthrough of the Process
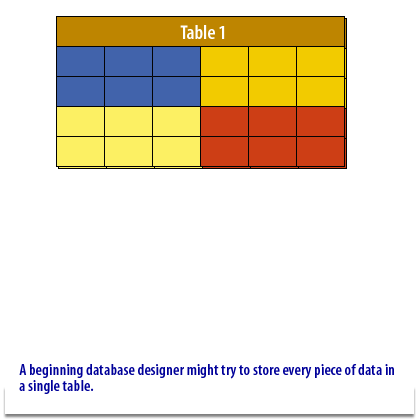
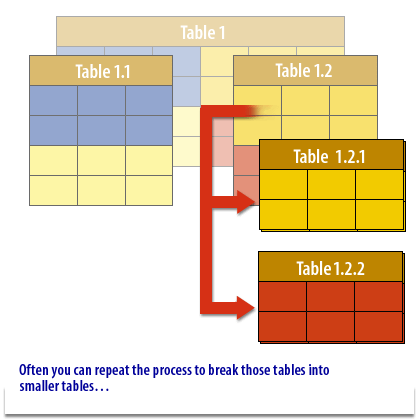
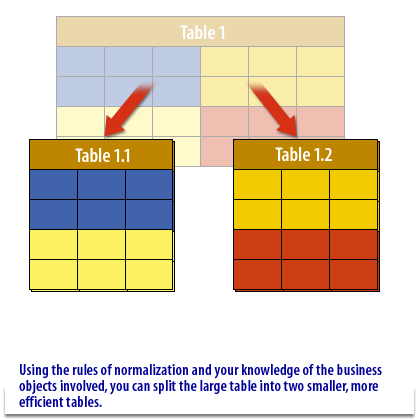
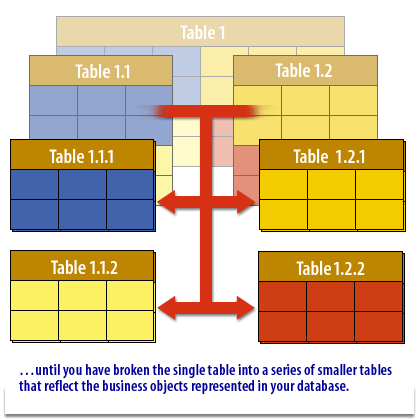
Core Definitions
- Functional Dependency (FD): Attributes
Xdetermine attributeY(writtenX → Y). - 1NF: No repeating groups; each column is atomic; one value per row-column intersection.
- 2NF: For composite keys, every non-key attribute depends on the entire key (no partial dependencies).
- 3NF: No non-key attribute depends on another non-key attribute (no transitive dependencies).
Worked Example: UNF → 1NF → 2NF → 3NF
Scenario: Orders, customers, and products are jammed into one table with repeating line items.
-- UNF: single row contains multiple line items (repeating groups)
OrderUNF(OrderID, OrderDate, CustomerID, CustomerName,
Item1_ProductID, Item1_ProductName, Item1_Qty, Item1_Price,
Item2_ProductID, Item2_ProductName, Item2_Qty, Item2_Price, ...)
-- 1NF: eliminate repeating groups (one line per row)
OrderLine1NF(OrderID, OrderDate, CustomerID, CustomerName,
ProductID, ProductName, Qty, Price)
-- FDs (illustrative)
-- OrderID → OrderDate, CustomerID
-- CustomerID → CustomerName
-- ProductID → ProductName
-- (OrderID, ProductID) → Qty, Price
-- 2NF: if key is (OrderID, ProductID), remove partial dependencies
Order(OrderID, OrderDate, CustomerID)
Customer(CustomerID, CustomerName)
Product(ProductID, ProductName)
OrderLine(OrderID, ProductID, Qty, Price)
-- 3NF: remove transitive dependencies between non-key attributes
-- If ProductID → ListPrice and OrderLine.Price stores the actual sale price,
-- keep ListPrice in Product and retain OrderLine.Price for history (business rule).
Normalization and the ERD
Normalization complements ER modeling: if each ER entity represents a single business object, the mapped tables tend to satisfy 1NF by design. FDs discovered during normalization often refine attribute placement and keys in the logical model.
Quick Checklist
- Any repeating groups? Split them into a child table (1NF).
- Composite keys present? Ensure non-key columns depend on the whole key (2NF).
- Do any non-key columns determine other non-key columns? Split them out (3NF).
Practice Notes
- Information preservation: Decompose without losing facts; you’re redistributing, not discarding.
- Performance: Normalize first for correctness. Consider denormalization later, deliberately, and document why.
- Cross-reference: Review Functional Dependencies next and proceed to BCNF when appropriate.