| Lesson 1 | Entities & Attributes |
| Objective | Introduce entities, attributes, and identifiers in ER modeling and how they emerge from business objects. |
Entities and Attributes: An Introduction
In Entity–Relationship (ER) modeling, an entity represents a real-world thing or concept the business cares about (e.g., Student, Order, Appointment). An entity has attributes—properties that describe it (e.g., StudentID, Name, GPA). ER diagrams capture these structures and their relationships before any data is stored, giving designers a clear blueprint for the database.
From Business Objects to ER Models
During logical design, you convert business objects and their characteristics into entities and attributes. The result is a conceptual model (ERD) that focuses on structure—not on timing, screens, or code. Think of it as the building plan for your data: design the structure first, then populate it with rows later.
Learning Objectives
After completing this module, you will be able to:
- Define entities, attributes, and entity identifiers (keys).
- Explain how identifiers are chosen and why they matter.
- Describe entity instances (rows) vs. entity types (tables).
- Define attribute domains (valid value sets) and data types.
- Recognize problems with multi-valued attributes and how to resolve them.
- List common entity/attribute constraints used to protect data quality.
Key Concepts
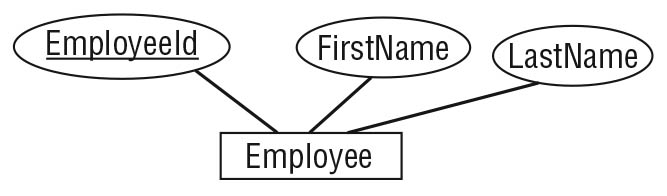
- Entity (type): A category of things to store data about (e.g., Employee). In a relational schema, usually a table.
- Entity instance: A single occurrence (a row), e.g., employee “E12345”.
- Attribute: A property of an entity (columns), e.g., FirstName, HireDate.
- Identifier (key): An attribute or set of attributes that uniquely identifies each instance (candidate keys; one chosen as the primary key). Can be natural (e.g., ISBN) or surrogate (e.g., numeric ID).
- Domain: The allowed set/format of values for an attribute (data type, length, constraints, enumerations).
- Nullability: Whether an attribute may be unknown/absent; restrict nulls for identifiers and mandatory facts.
- Derived attribute: Computed from other data (e.g., Age from BirthDate); often excluded from base tables or documented as a view calculation.
Choosing Good Identifiers
A strong identifier is:
- Unique across all rows and stable over time.
- Minimal (no unnecessary attributes in a composite key).
- Non-volatile (rarely changes as business evolves).
When natural keys are unstable or bulky, adopt a surrogate key (EmployeeID) and enforce natural key rules with UNIQUE constraints.
Designing Attributes
- Simple vs. composite: Prefer atomic attributes; split Address into Street, City, State, PostalCode if queried separately.
- Single-valued vs. multi-valued: Avoid columns that store lists (PhoneNumbers); they break indexing and integrity.
- Validation: Capture value rules as domains and constraints (e.g.,
CHECK (GPA BETWEEN 0 AND 4.0)).
Resolving Multi-Valued Attributes
Two common patterns:
- Add attributes only when there is a small, fixed set (e.g., HomePhone, WorkPhone), and each is truly distinct.
- Create a new entity for one-to-many facts (preferred for open-ended lists):
Employee(EmployeeID PK, FirstName, LastName, ...)
Phone (PhoneID PK, EmployeeID FK, PhoneType, PhoneNumber)This preserves searchability, indexing, and referential integrity.
Notation Tips
You may see different ER notations (e.g., Chen, Crow’s Foot). Regardless of symbol style, keep naming, key markings, and cardinalities consistent across the model.
In the next lessons, you will formalize identifiers, define attribute domains, and refactor multi-valued attributes into proper entity relationships.