| Lesson 3 | Entity Identifiers |
| Objective | Explain the purpose of entity identifiers and how they support relationships and integrity. |
Purpose of Entity Identifiers in Database Design
Why Identifiers Matter
- Uniqueness: Prevent duplicate rows and allow unambiguous reference to a single record.
- Efficient Retrieval: PKs are typically indexed, enabling fast lookups and joins.
- Relationship Mapping: FKs in child tables reference the parent’s PK to link related data.
- Consistency & Integrity: PK/FK and
UNIQUE/CHECKconstraints prevent orphan records and broken links. - Scalability: Stable keys keep joins and maintenance predictable as data grows.
Choosing a Good Identifier
- Stable over time: Avoid values likely to change (e.g., phone numbers).
- Minimal: No unnecessary attributes in a composite key.
- Non-null and unique: Enforce with
NOT NULLandUNIQUE/PRIMARY KEY. - Natural vs. Surrogate: Use a natural key when it’s small and stable (e.g., ISBN). Otherwise use a surrogate (e.g.,
CustomerID) and enforce the natural business rule with aUNIQUEconstraint.
From Identifiers to Keys
- Candidate keys: All attributes/attribute-sets that can uniquely identify a row.
- Primary key (PK): The chosen candidate key used by FKs.
- Alternate keys: Remaining candidate keys enforced with
UNIQUE. - Foreign keys (FKs): Columns in child tables that reference the parent’s PK (or a candidate key).
Many-to-Many Requires an Associative (Composite) Entity
When two entities have a many-to-many (M:N) relationship (e.g., Students ↔ Courses), introduce an associative (bridge/junction) entity to break it into two 1:M relationships. The associative table’s identifier can be modeled in two common ways:
Pattern A - Composite Primary Key (compact and natural):
CREATE TABLE Enrollment (
StudentID INT NOT NULL,
CourseID INT NOT NULL,
EnrolledOn DATE NOT NULL,
PRIMARY KEY (StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);Pattern B - Surrogate PK plus Business Uniqueness (flexible for additional relationships/attributes):
CREATE TABLE Enrollment (
EnrollmentID BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
StudentID INT NOT NULL,
CourseID INT NOT NULL,
EnrolledOn DATE NOT NULL,
UNIQUE (StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);Note: An associative entity does have an identifier-either the composite of its FKs (Pattern A) or a surrogate PK with a UNIQUE constraint on the FK pair (Pattern B). Choose based on stability, simplicity, and query needs.
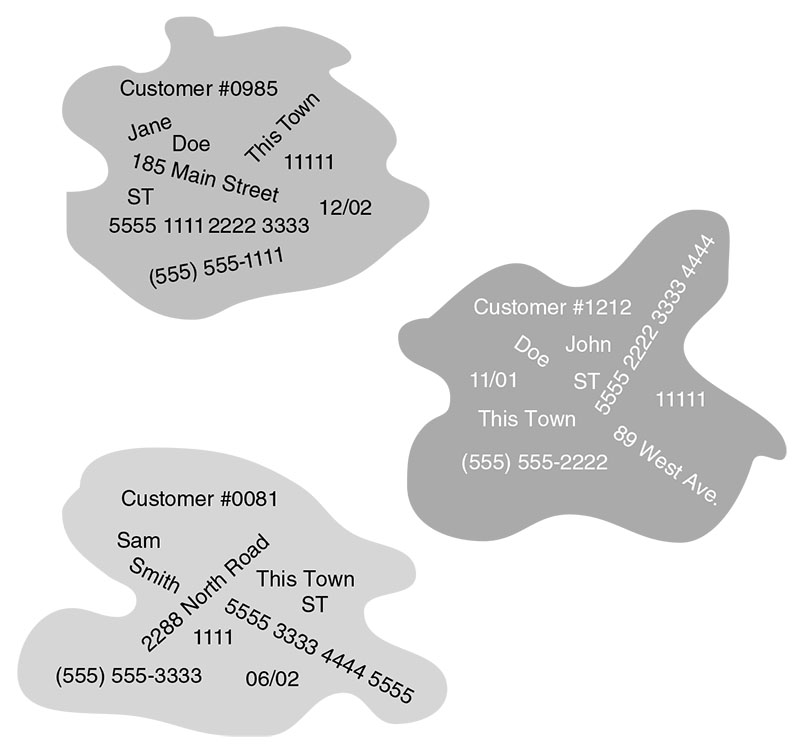
Example: Identifying Customer Records
Each customer must be uniquely identifiable-by a surrogate CustomerID or a stable natural key. All other columns describe the customer but do not uniquely identify them.
Rules of Thumb
- Every entity needs at least one candidate identifier; choose one PK.
- Keys should be immutable and minimal; never reuse a primary key.
- Model M:N with an associative entity; avoid list-like columns.
- Document natural-key constraints with
UNIQUEto preserve business rules even when using surrogate PKs.